Medical Large Language Model Benchmarks Should Prioritize Construct Validity
作者: Ahmed Alaa, Thomas Hartvigsen, Niloufar Golchini, Shiladitya Dutta, Frances Dean, Inioluwa Deborah Raji, Travis Zack
分类: cs.CL
发布日期: 2025-03-12
💡 一句话要点
医学大语言模型评测应优先考虑建构效度,避免唯榜单论
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 医学大语言模型 基准测试 建构效度 临床应用 模型评估
📋 核心要点
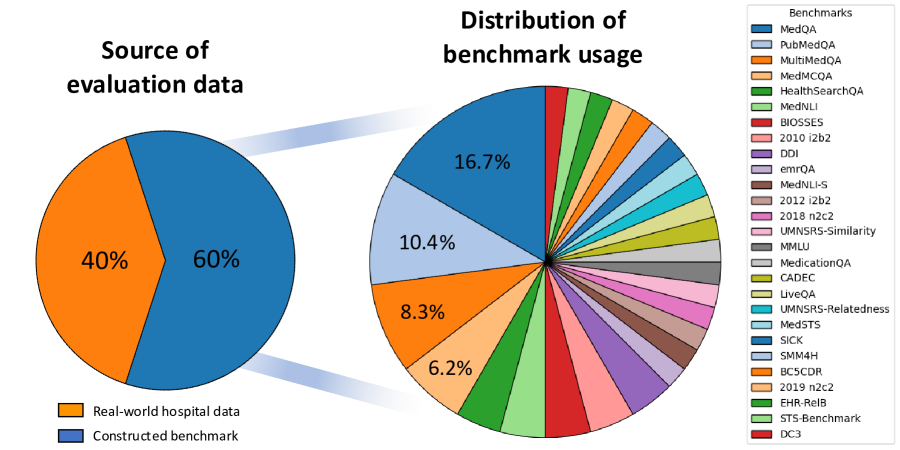
- 现有医学LLM基准测试多采用医学执照考试题,未能准确反映真实临床任务,导致评估结果与实际应用脱节。
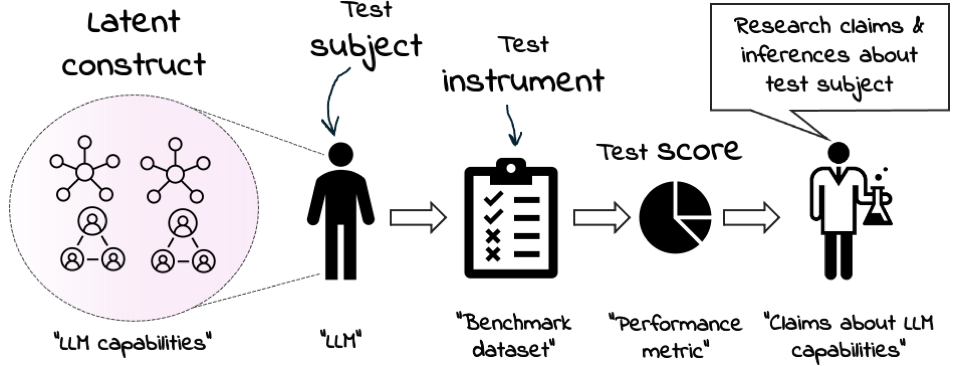
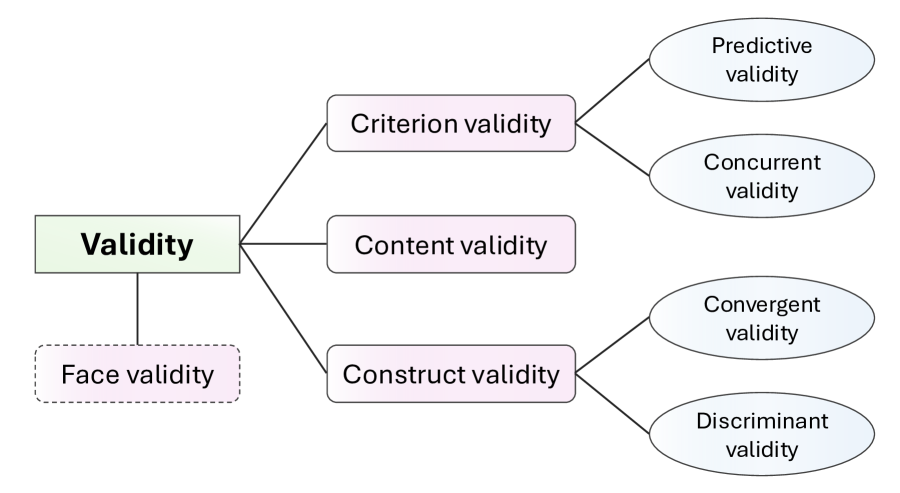
- 该论文借鉴心理测试领域的“建构效度”概念,提出对医学LLM基准进行实证评估,确保其有效衡量目标能力。
- 通过实验验证,发现现有医学LLM基准在建构效度方面存在显著差距,并展望了构建更有效基准的未来方向。
📝 摘要(中文)
医学大语言模型(LLM)研究经常提出大胆的主张,从编码临床知识到像医生一样推理。这些主张通常以在竞争性基准上的评估为后盾,这是从主流机器学习继承下来的传统。但是,我们如何区分真正的进步和排行榜上的虚张声势?医学LLM基准测试,就像其他领域的一样,是使用医学执照考试问题随意构建的。为了使这些基准真正衡量进步,它们必须准确地捕捉它们旨在代表的真实世界任务。在这篇立场文件中,我们认为医学LLM基准应该(并且确实可以)根据它们的建构效度进行实证评估。在心理测试文献中,“建构效度”是指测试测量潜在“建构”的能力,即评估的实际概念目标。通过将LLM基准测试与心理测试进行类比,我们解释了该领域的框架如何为验证基准测试提供经验基础。为了将这些想法付诸实践,我们使用真实世界的临床数据在概念验证实验中评估流行的医学LLM基准测试,并报告它们建构效度方面的重大差距。最后,我们概述了一个以创建有效基准为中心的医学LLM评估新生态系统的愿景。
🔬 方法详解
问题定义:现有医学大语言模型(LLM)的评估基准主要依赖于医学执照考试题目,这些题目虽然能测试模型对医学知识的掌握,但无法准确反映模型在真实临床场景中的应用能力。现有方法的痛点在于,高分不代表模型真正具备解决实际问题的能力,容易误导研究方向。
核心思路:论文借鉴心理测量学中的“建构效度”概念,认为一个有效的评估基准应该能够准确测量其声称要测量的潜在能力(即“建构”)。因此,需要对现有医学LLM基准进行实证评估,验证其是否真正能够反映模型在临床实践中的能力。核心在于从真实临床数据出发,设计实验来检验基准测试的有效性。
技术框架:论文的技术框架主要包含以下几个阶段:1) 提出建构效度的概念,并将其引入医学LLM基准测试的评估中。2) 使用真实世界的临床数据设计实验,评估现有医学LLM基准的建构效度。3) 分析实验结果,揭示现有基准的不足之处。4) 提出构建更有效的医学LLM基准的愿景,强调基准测试应更贴近实际临床任务。
关键创新:该论文最重要的创新点在于将心理测量学中的“建构效度”概念引入医学LLM的评估领域。与以往只关注模型在特定数据集上的表现不同,该论文强调评估基准本身的有效性,确保其能够准确反映模型在真实世界中的能力。这种方法论上的转变有助于避免“唯榜单论”,推动医学LLM研究朝着更实用的方向发展。
关键设计:论文的关键设计在于如何利用真实临床数据来评估现有基准的建构效度。具体的实验设计细节未知,但可以推测可能包括:1) 使用真实患者的病历数据,模拟临床诊断场景。2) 设计针对特定临床任务的评估指标,例如诊断准确率、治疗方案合理性等。3) 将模型在现有基准上的表现与在真实临床数据上的表现进行对比,分析两者之间的相关性。
🖼️ 关键图片
📊 实验亮点
论文通过概念验证实验,揭示了现有医学LLM基准在建构效度方面存在显著差距。具体性能数据未知,但实验结果表明,模型在现有基准上的高分并不一定代表其在真实临床场景中具有良好的表现。这突显了对基准进行有效性评估的重要性。
🎯 应用场景
该研究成果可应用于指导医学LLM基准测试的构建和选择,确保评估结果更具临床意义。通过构建更有效的基准,可以推动医学LLM在疾病诊断、治疗方案制定、患者咨询等领域的应用,最终提升医疗服务质量。
📄 摘要(原文)
Medical large language models (LLMs) research often makes bold claims, from encoding clinical knowledge to reasoning like a physician. These claims are usually backed by evaluation on competitive benchmarks; a tradition inherited from mainstream machine learning. But how do we separate real progress from a leaderboard flex? Medical LLM benchmarks, much like those in other fields, are arbitrarily constructed using medical licensing exam questions. For these benchmarks to truly measure progress, they must accurately capture the real-world tasks they aim to represent. In this position paper, we argue that medical LLM benchmarks should (and indeed can) be empirically evaluated for their construct validity. In the psychological testing literature, "construct validity" refers to the ability of a test to measure an underlying "construct", that is the actual conceptual target of evaluation. By drawing an analogy between LLM benchmarks and psychological tests, we explain how frameworks from this field can provide empirical foundations for validating benchmarks. To put these ideas into practice, we use real-world clinical data in proof-of-concept experiments to evaluate popular medical LLM benchmarks and report significant gaps in their construct validity. Finally, we outline a vision for a new ecosystem of medical LLM evaluation centered around the creation of valid benchmarks.