Cost-Optimal Grouped-Query Attention for Long-Context Modeling
作者: Yingfa Chen, Yutong Wu, Chenyang Song, Zhen Leng Thai, Xingyu Shen, Xu Han, Zhiyuan Liu, Maosong Sun
分类: cs.CL, cs.AI, cs.LG
发布日期: 2025-03-12 (更新: 2025-09-26)
备注: EMNLP 2025 Main
💡 一句话要点
提出面向长文本建模的成本优化分组查询注意力机制,显著降低计算成本。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 分组查询注意力 长文本建模 计算成本优化 模型大小优化 推理效率 大型语言模型 上下文长度 资源分配
📋 核心要点
- 现有GQA配置忽略了上下文长度对推理成本的影响,导致长文本场景下计算效率低下。
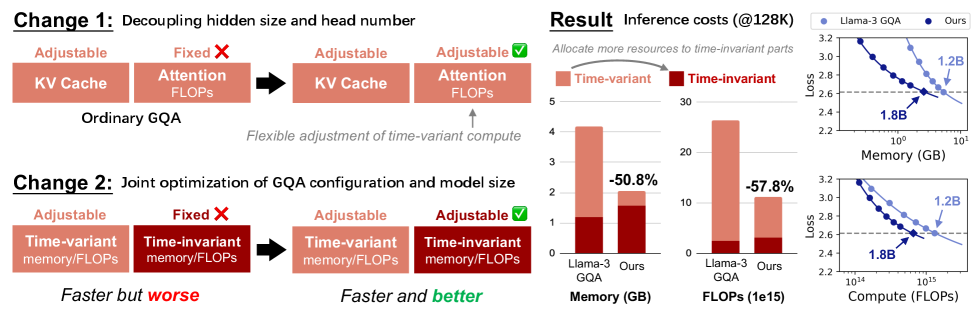
- 通过解耦总头大小与隐藏大小,并联合优化模型大小和GQA配置,实现推理资源的最优分配。
- 实验表明,该方法在长文本场景下能显著降低内存使用和FLOPs,同时保持模型性能。
📝 摘要(中文)
分组查询注意力(GQA)是一种广泛应用于大型语言模型(LLM)中,用于降低注意力层计算成本的策略。然而,当前的GQA配置通常是次优的,因为它们忽略了上下文长度对推理成本的影响。由于推理成本随上下文长度增长,因此最具成本效益的GQA配置也应相应变化。本文分析了上下文长度、模型大小、GQA配置和模型损失之间的关系,并提出了两项创新:(1)我们将总头大小与隐藏大小解耦,从而可以更灵活地控制注意力FLOPs;(2)我们联合优化模型大小和GQA配置,以在注意力层和其他组件之间更好地分配推理资源。我们的分析表明,常用的GQA配置对于长上下文场景而言是高度次优的。更重要的是,我们提出了一种用于推导成本最优GQA配置的方法。我们的结果表明,对于长上下文场景,应该使用更少的注意力头,同时扩大模型大小。通过我们的方法选择的配置可以比Llama-3的GQA减少超过50%的内存使用和FLOPs,且不降低模型能力。我们的发现为设计高效的长上下文LLM提供了有价值的见解。代码可在https://www.github.com/THUNLP/cost-optimal-gqa 获取。
🔬 方法详解
问题定义:论文旨在解决长文本建模中,现有分组查询注意力(GQA)配置在推理成本方面效率低下的问题。现有方法通常采用固定的GQA配置,而忽略了上下文长度对推理成本的影响,导致资源分配不合理,尤其是在长文本场景下,计算和内存开销巨大。
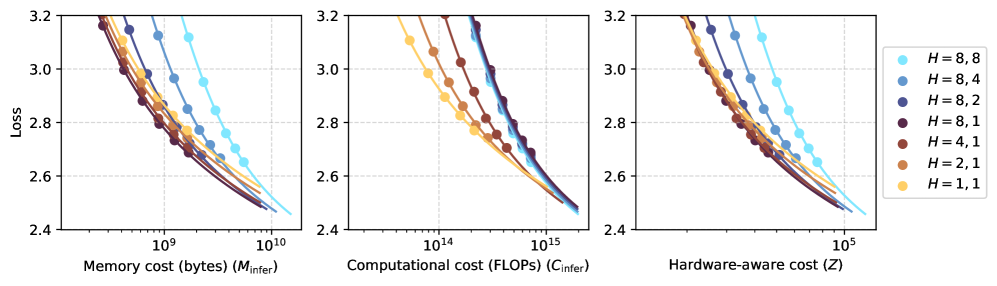
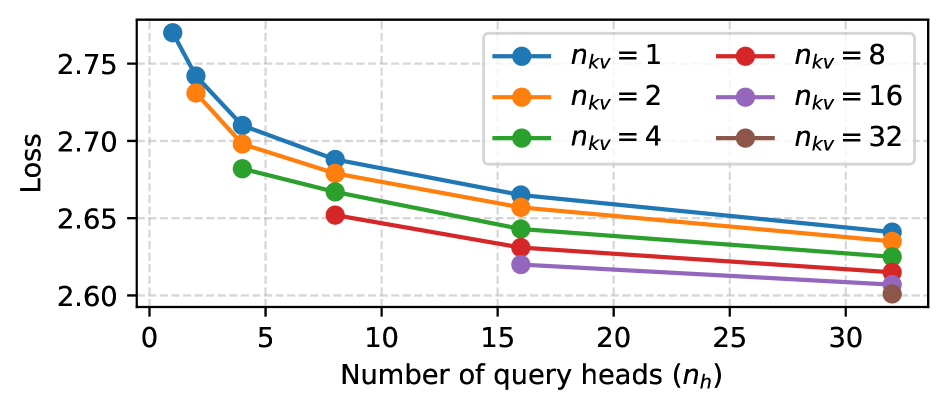
核心思路:论文的核心思路是根据上下文长度动态调整GQA配置,以实现成本最优的推理。具体而言,通过解耦总头大小与隐藏大小,并联合优化模型大小和GQA配置,使得在长文本场景下,能够以更少的注意力头和更大的模型规模,在保证模型性能的前提下,显著降低计算成本。
技术框架:论文提出了一种成本优化GQA配置的框架,主要包含以下几个阶段:1) 分析上下文长度、模型大小、GQA配置和模型损失之间的关系;2) 解耦总头大小与隐藏大小,允许更灵活地控制注意力FLOPs;3) 联合优化模型大小和GQA配置,以实现推理资源在注意力层和其他组件之间的最优分配;4) 基于分析结果,提出一种推导成本最优GQA配置的策略。
关键创新:论文的关键创新在于:1) 提出了总头大小与隐藏大小解耦的概念,打破了传统GQA配置的限制,使得可以更精细地控制注意力层的计算量;2) 提出了联合优化模型大小和GQA配置的方法,使得可以根据上下文长度动态调整GQA配置,从而实现成本最优的推理。与现有方法相比,该方法能够更有效地利用计算资源,在保证模型性能的同时,显著降低计算成本。
关键设计:论文的关键设计包括:1) 定义了总头大小与隐藏大小的解耦方式,允许独立调整两者的大小;2) 设计了联合优化模型大小和GQA配置的算法,该算法考虑了上下文长度、模型大小、GQA配置和模型损失之间的关系,以找到成本最优的配置;3) 提出了一种基于分析结果的GQA配置策略,该策略建议在长文本场景下使用更少的注意力头,同时扩大模型大小。
🖼️ 关键图片
📊 实验亮点
实验结果表明,该方法在长文本场景下,与Llama-3的GQA相比,能够减少超过50%的内存使用和FLOPs,同时保持模型性能不下降。这表明该方法能够有效地降低长文本建模的计算成本,为设计高效的长上下文LLM提供了有价值的参考。
🎯 应用场景
该研究成果可广泛应用于需要处理长文本的自然语言处理任务中,例如长文档摘要、机器翻译、对话生成等。通过降低计算成本和内存占用,可以使得大型语言模型在资源受限的设备上运行,并加速模型的训练和推理过程,具有重要的实际应用价值和潜在的商业前景。
📄 摘要(原文)
Grouped-Query Attention (GQA) is a widely adopted strategy for reducing the computational cost of attention layers in large language models (LLMs). However, current GQA configurations are often suboptimal because they overlook how context length influences inference cost. Since inference cost grows with context length, the most cost-efficient GQA configuration should also vary accordingly. In this work, we analyze the relationship among context length, model size, GQA configuration, and model loss, and introduce two innovations: (1) we decouple the total head size from the hidden size, enabling more flexible control over attention FLOPs; and (2) we jointly optimize the model size and the GQA configuration to arrive at a better allocation of inference resources between attention layers and other components. Our analysis reveals that commonly used GQA configurations are highly suboptimal for long-context scenarios. More importantly, we propose a recipe for deriving cost-optimal GQA configurations. Our results show that for long-context scenarios, one should use fewer attention heads while scaling up model size. Configurations selected by our recipe can reduce both memory usage and FLOPs by more than 50% compared to Llama-3's GQA, with no degradation in model capabilities. Our findings offer valuable insights for designing efficient long-context LLMs. The code is available at https://www.github.com/THUNLP/cost-optimal-gqa .