Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning
作者: Bowen Jin, Hansi Zeng, Zhenrui Yue, Jinsung Yoon, Sercan Arik, Dong Wang, Hamed Zamani, Jiawei Han
分类: cs.CL, cs.AI, cs.IR
发布日期: 2025-03-12 (更新: 2025-08-05)
备注: 31 pages
🔗 代码/项目: GITHUB
💡 一句话要点
Search-R1:利用强化学习训练LLM进行推理并有效利用搜索引擎
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 强化学习 搜索引擎 检索增强生成 问答系统
📋 核心要点
- 现有LLM在推理时利用搜索引擎的能力不足,无法最佳地进行交互,导致检索效果不佳。
- Search-R1通过强化学习,使LLM学习自主生成搜索查询,并进行实时检索,优化推理轨迹。
- 实验表明,Search-R1在问答数据集上显著优于RAG基线,Qwen2.5-7B提升41%,Qwen2.5-3B提升20%。
📝 摘要(中文)
大型语言模型(LLM)有效获取外部知识和最新信息对于推理和文本生成至关重要。尽管可以通过提示具备推理能力的高级LLM在推理过程中使用搜索引擎,但效果往往不佳,因为LLM可能不完全具备与搜索引擎最佳交互的能力。本文提出了Search-R1,它是强化学习(RL)在推理框架中的扩展,LLM学习在逐步推理过程中自主生成(多个)搜索查询,并进行实时检索。Search-R1通过多轮搜索交互优化LLM推理轨迹,利用检索到的token masking来实现稳定的RL训练,并采用基于结果的简单奖励函数。在七个问答数据集上的实验表明,在相同设置下,Search-R1的性能比各种RAG基线提高了41%(Qwen2.5-7B)和20%(Qwen2.5-3B)。本文还提供了关于检索增强推理中RL优化方法、LLM选择和响应长度动态的经验性见解。代码和模型checkpoint可在https://github.com/PeterGriffinJin/Search-R1获取。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在推理过程中如何更有效地利用搜索引擎获取外部知识的问题。现有的方法,例如直接提示LLM使用搜索引擎,往往效果不佳,因为LLM可能不具备与搜索引擎进行有效交互的能力,导致检索到的信息质量不高,影响最终的推理结果。
核心思路:论文的核心思路是利用强化学习(RL)来训练LLM,使其能够自主地生成搜索查询,并根据检索结果调整后续的搜索策略。通过与搜索引擎的多次交互,LLM可以逐步获取所需的信息,从而提高推理的准确性和效率。这种方法将LLM与搜索引擎视为一个整体,通过RL优化它们的协同工作方式。
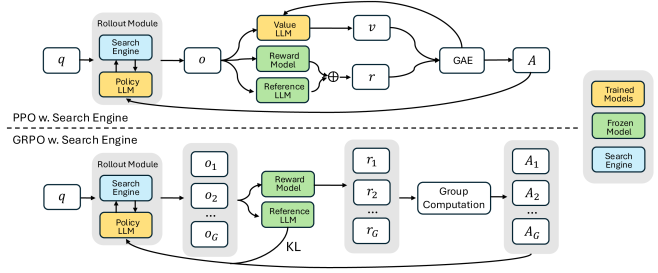
技术框架:Search-R1的整体框架包括以下几个主要模块:1) LLM作为智能体,负责生成搜索查询和进行推理;2) 搜索引擎,负责根据查询返回相关文档;3) 奖励函数,用于评估LLM的搜索和推理结果,并指导RL训练;4) 检索到的token masking,用于稳定RL训练。LLM在每个推理步骤中,首先生成一个或多个搜索查询,然后将查询发送给搜索引擎。搜索引擎返回的文档被用于增强LLM的知识,LLM根据增强的知识进行推理,并最终生成答案。奖励函数根据答案的正确性给予LLM奖励或惩罚,LLM通过RL算法不断学习,优化搜索策略和推理能力。
关键创新:Search-R1的关键创新在于将强化学习应用于LLM与搜索引擎的交互过程,使其能够自主学习如何有效地利用搜索引擎。与传统的RAG方法相比,Search-R1不是简单地将检索到的文档作为LLM的输入,而是通过RL优化LLM的搜索策略,使其能够主动地获取所需的信息。此外,检索到的token masking技术有助于稳定RL训练,避免出现训练崩溃的问题。
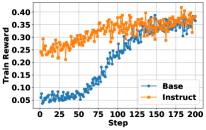
关键设计:Search-R1采用基于结果的简单奖励函数,根据LLM生成的答案的正确性给予奖励或惩罚。为了稳定RL训练,论文采用了检索到的token masking技术,即在训练过程中,随机mask掉一部分检索到的token,从而避免LLM过度依赖检索结果,提高模型的泛化能力。此外,论文还研究了不同的LLM选择、响应长度动态等因素对检索增强推理的影响。
🖼️ 关键图片
📊 实验亮点
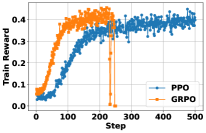
实验结果表明,Search-R1在七个问答数据集上显著优于各种RAG基线。具体来说,使用Qwen2.5-7B作为LLM时,Search-R1的性能比RAG基线提高了41%;使用Qwen2.5-3B作为LLM时,性能提升了20%。这些结果表明,通过强化学习优化LLM与搜索引擎的交互,可以显著提高LLM的推理能力。
🎯 应用场景
Search-R1具有广泛的应用前景,可以应用于问答系统、知识图谱构建、智能客服等领域。通过使LLM能够自主地利用搜索引擎获取外部知识,可以提高这些应用系统的准确性和效率。此外,Search-R1还可以用于训练LLM进行更复杂的推理任务,例如科学研究、金融分析等。
📄 摘要(原文)
Efficiently acquiring external knowledge and up-to-date information is essential for effective reasoning and text generation in large language models (LLMs). Prompting advanced LLMs with reasoning capabilities to use search engines during inference is often suboptimal, as the LLM might not fully possess the capability on how to interact optimally with the search engine. This paper introduces Search-R1, an extension of reinforcement learning (RL) for reasoning frameworks where the LLM learns to autonomously generate (multiple) search queries during step-by-step reasoning with real-time retrieval. Search-R1 optimizes LLM reasoning trajectories with multi-turn search interactions, leveraging retrieved token masking for stable RL training and a simple outcome-based reward function. Experiments on seven question-answering datasets show that Search-R1 improves performance by 41% (Qwen2.5-7B) and 20% (Qwen2.5-3B) over various RAG baselines under the same setting. This paper further provides empirical insights into RL optimization methods, LLM choices, and response length dynamics in retrieval-augmented reasoning. The code and model checkpoints are available at https://github.com/PeterGriffinJin/Search-R1.