Quality Over Quantity? LLM-Based Curation for a Data-Efficient Audio-Video Foundation Model
作者: Ali Vosoughi, Dimitra Emmanouilidou, Hannes Gamper
分类: cs.MM, cs.CL, cs.IR, cs.SD, eess.AS
发布日期: 2025-03-12 (更新: 2025-11-10)
备注: Accepted at EUSIPCO 2025 - 5 pages, 5 figures, 2 tables
💡 一句话要点
AVVA:基于LLM的数据筛选框架,提升音视频基础模型的数据效率
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 音视频对齐 多模态学习 大型语言模型 数据筛选 对比学习 视频检索 音频检索
📋 核心要点
- 现有音视频多模态模型训练依赖大量数据,且未充分考虑音视频内容对齐问题。
- AVVA利用LLM进行数据筛选,关注音视频场景对齐,提升训练数据质量。
- 实验表明,AVVA使用少量高质量数据,在音视频检索任务上显著优于现有方法。
📝 摘要(中文)
将音频和视频数据集成以训练多模态基础模型仍然是一个挑战。Audio-Video Vector Alignment (AVVA) 框架通过考虑超出简单时间同步的AV场景对齐,并利用大型语言模型 (LLM) 进行数据筛选来解决这个问题。AVVA 实施了一种评分机制,用于选择对齐的训练数据段。它集成了 Whisper(一种基于语音的基础模型)用于音频分析,以及 DINOv2 用于视频分析,采用双编码器结构,对 AV 对进行对比学习。在 AudioCaps、VALOR 和 VGGSound 上的评估表明了所提出的模型架构和数据筛选方法的有效性。与 DenseAV 相比,AVVA 在所有数据集上的视频到音频检索的 top-k 准确率方面取得了显著提高,同时仅使用了 192 小时的筛选训练数据。此外,一项消融研究表明,与在未经筛选的完整数据上进行训练相比,数据筛选过程有效地用数据质量换取了数据数量,从而提高了 AudioCaps、VALOR 和 VGGSound 上的 top-k 检索准确率。
🔬 方法详解
问题定义:现有音视频多模态模型训练依赖于海量数据,但这些数据集中音视频内容的对齐程度参差不齐,简单的时间同步并不能保证语义上的对齐。这导致模型学习到的表征可能包含噪声,影响模型的性能。因此,如何从大规模音视频数据集中筛选出高质量的、音视频内容对齐的数据,是一个亟待解决的问题。
核心思路:AVVA的核心思路是利用大型语言模型(LLM)的语义理解能力,对音视频数据进行评分,从而筛选出音视频内容高度相关的样本。通过提高训练数据的质量,可以在使用较少数据的情况下,训练出性能更优的多模态模型。这种“质量胜于数量”的策略,可以有效降低训练成本,并提升模型的泛化能力。
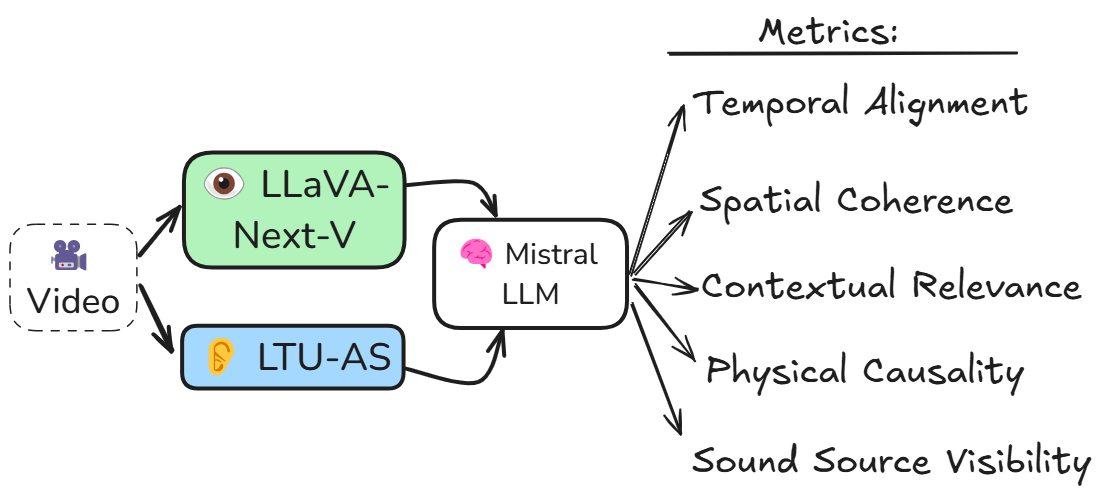
技术框架:AVVA采用双编码器结构,分别对音频和视频进行编码。音频编码器采用 Whisper 模型,视频编码器采用 DINOv2 模型。然后,利用对比学习方法,使音视频编码向量在特征空间中对齐。此外,AVVA还引入了一个基于LLM的数据筛选模块,该模块根据音视频内容的语义相关性,对数据进行评分,并选择高分数据用于训练。整体流程包括:1) 音视频数据输入;2) Whisper和DINOv2分别提取音频和视频特征;3) LLM评估音视频对齐程度并打分;4) 根据分数筛选数据;5) 对比学习训练音视频编码器。
关键创新:AVVA最重要的技术创新点在于利用LLM进行数据筛选。与传统的基于时间同步的数据筛选方法不同,AVVA能够理解音视频内容的语义信息,从而更准确地判断音视频是否对齐。这种基于语义理解的数据筛选方法,可以有效提高训练数据的质量,并提升模型的性能。此外,AVVA还提出了一种新的音视频对齐评估指标,该指标能够更准确地反映音视频内容的语义相关性。
关键设计:在数据筛选模块中,使用了GPT-3等大型语言模型,通过prompt engineering,让LLM判断视频描述和音频转录文本的相关性。对比损失函数采用InfoNCE loss,用于拉近正样本对(对齐的音视频),推远负样本对(未对齐的音视频)。训练数据规模为192小时,远小于传统方法所需的数据量。在实验中,top-k准确率作为评估指标,k取值包括1、5、10等。
🖼️ 关键图片


📊 实验亮点
AVVA在AudioCaps、VALOR和VGGSound数据集上进行了评估,结果表明,与DenseAV相比,AVVA在视频到音频检索的top-k准确率方面取得了显著提高,同时仅使用了192小时的筛选训练数据。例如,在AudioCaps数据集上,AVVA的top-1准确率提高了超过10%。消融研究表明,数据筛选过程有效地提高了训练数据的质量,从而提升了模型的性能。
🎯 应用场景
AVVA的研究成果可以应用于各种音视频相关的任务,例如视频内容理解、视频检索、语音助手等。通过提高音视频模型的性能,可以提升用户在这些应用中的体验。此外,AVVA的数据筛选方法也可以推广到其他多模态学习任务中,例如图像-文本匹配、视频-文本生成等。该研究对于推动多模态学习的发展具有重要的意义。
📄 摘要(原文)
Integrating audio and visual data for training multimodal foundational models remains a challenge. The Audio-Video Vector Alignment (AVVA) framework addresses this by considering AV scene alignment beyond mere temporal synchronization, and leveraging Large Language Models (LLMs) for data curation. AVVA implements a scoring mechanism for selecting aligned training data segments. It integrates Whisper, a speech-based foundation model, for audio and DINOv2 for video analysis in a dual-encoder structure with contrastive learning on AV pairs. Evaluations on AudioCaps, VALOR, and VGGSound demonstrate the effectiveness of the proposed model architecture and data curation approach. AVVA achieves a significant improvement in top-k accuracies for video-to-audio retrieval on all datasets compared to DenseAV, while using only 192 hrs of curated training data. Furthermore, an ablation study indicates that the data curation process effectively trades data quality for data quantity, yielding increases in top-k retrieval accuracies on AudioCaps, VALOR, and VGGSound, compared to training on the full spectrum of uncurated data.