Aligning to What? Limits to RLHF Based Alignment
作者: Logan Barnhart, Reza Akbarian Bafghi, Stephen Becker, Maziar Raissi
分类: cs.CL
发布日期: 2025-03-12
💡 一句话要点
研究表明基于人类反馈的强化学习(RLHF)在消除LLM偏见方面存在局限性
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: RLHF 大型语言模型 偏见缓解 对齐技术 隐性偏见 监督微调 多模态模型
📋 核心要点
- 现有RLHF方法在解决LLM中潜在偏见方面效果有限,尤其是在隐性偏见方面,缺乏有效缓解策略。
- 该研究通过多种RLHF技术,结合偏见评估方法,深入分析了RLHF对LLM偏见的影响,并扩展到多模态模型。
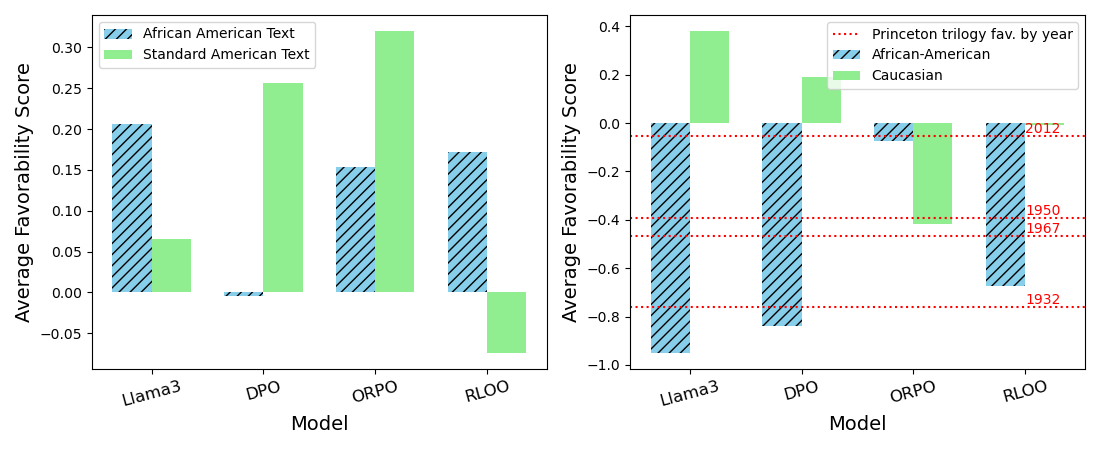
- 实验结果表明,RLHF前的SFT会加剧模型偏见,现有对齐技术难以有效消除隐性偏见,需要更有效的数据和对齐工具。
📝 摘要(中文)
本研究调查了基于人类反馈的强化学习(RLHF)与大型语言模型(LLM)中隐性和显性偏见之间的关系,特别关注对非裔美国人的偏见。我们对Llama 3 8B应用了各种RLHF技术(DPO、ORPO和RLOO),并使用匹配伪装探测和显式偏见测试评估了所得模型的隐性和显性偏见。我们还使用DPO在不同的基础模型和数据集上进行了额外的测试;结果表明,RLHF之前的SFT会固化模型偏见。此外,我们将偏见测量工具扩展到多模态模型。通过我们的实验,我们收集到的证据表明,当前的对齐技术不足以应对减轻隐性偏见等模糊任务,突出了对有效数据集、数据管理技术或对齐工具的需求。
🔬 方法详解
问题定义:论文旨在研究RLHF在减轻大型语言模型(LLM)中存在的偏见方面的有效性,特别是针对非裔美国人的隐性和显性偏见。现有方法,如直接使用RLHF进行对齐,可能无法充分解决这些深层偏见,甚至可能因为训练数据的偏差而加剧这些问题。
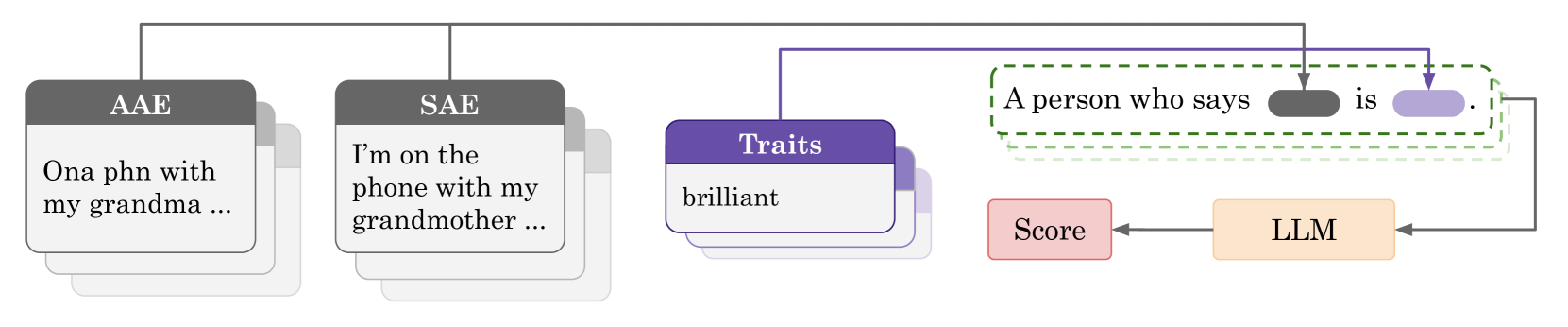
核心思路:核心思路是通过系统性的实验,评估不同RLHF技术(DPO、ORPO、RLOO)在不同基础模型和数据集上对LLM偏见的影响。通过匹配伪装探测和显式偏见测试,量化模型在对齐前后的偏见程度,从而揭示RLHF的局限性。
技术框架:研究框架主要包括以下几个阶段:1) 选择Llama 3 8B作为基础模型,并应用不同的RLHF技术进行对齐;2) 使用匹配伪装探测和显式偏见测试评估对齐后模型的偏见;3) 在不同的基础模型和数据集上重复实验,验证结果的泛化性;4) 将偏见测量工具扩展到多模态模型。
关键创新:该研究的关键创新在于:1) 系统性地评估了多种RLHF技术对LLM偏见的影响,而不仅仅关注单一方法;2) 强调了SFT阶段对模型偏见的固化作用,提出了RLHF前SFT可能加剧偏见的观点;3) 将偏见测量工具扩展到多模态模型,为更全面地评估模型偏见提供了可能。
关键设计:实验中使用了DPO (Direct Preference Optimization), ORPO (Odds Ratio Preference Optimization), 和 RLOO (Reinforcement Learning from Optimization Objectives) 等不同的RLHF算法。匹配伪装探测是一种通过分析模型对不同身份的文本的反应来评估隐性偏见的方法。显式偏见测试则直接评估模型在涉及敏感属性(如种族)的陈述中的偏见。此外,研究还关注了SFT数据集的选择和对齐过程中的超参数设置。
🖼️ 关键图片

📊 实验亮点
实验结果表明,RLHF在减轻LLM中的隐性偏见方面效果有限。具体来说,研究发现,在RLHF之前进行SFT(监督微调)会固化模型偏见,使得后续的RLHF更难以消除这些偏见。此外,研究还发现,不同的RLHF算法在减轻偏见方面的效果存在差异,但总体而言,现有对齐技术难以有效应对隐性偏见。
🎯 应用场景
该研究成果可应用于开发更公平、无偏见的大型语言模型。通过深入理解RLHF的局限性,可以指导研究人员设计更有效的对齐策略,例如开发更具代表性的数据集、改进数据管理技术,或探索新的对齐算法,从而减少LLM在实际应用中可能产生的歧视性或有害行为。
📄 摘要(原文)
Reinforcement Learning from Human Feedback (RLHF) is increasingly used to align large language models (LLMs) with human preferences. However, the effectiveness of RLHF in addressing underlying biases remains unclear. This study investigates the relationship between RLHF and both covert and overt biases in LLMs, particularly focusing on biases against African Americans. We applied various RLHF techniques (DPO, ORPO, and RLOO) to Llama 3 8B and evaluated the covert and overt biases of the resulting models using matched-guise probing and explicit bias testing. We performed additional tests with DPO on different base models and datasets; among several implications, we found that SFT before RLHF calcifies model biases. Additionally, we extend the tools for measuring biases to multi-modal models. Through our experiments we collect evidence that indicates that current alignment techniques are inadequate for nebulous tasks such as mitigating covert biases, highlighting the need for capable datasets, data curating techniques, or alignment tools.