Understanding the Quality-Diversity Trade-off in Diffusion Language Models
作者: Zak Buzzard
分类: cs.CL, cs.AI, cs.LG
发布日期: 2025-03-11
备注: 11 pages, 8 figures
💡 一句话要点
利用无分类器指导和随机钳位,提升扩散语言模型在序列生成任务中的质量-多样性平衡。
🎯 匹配领域: 支柱四:生成式动作 (Generative Motion)
关键词: 扩散模型 文本生成 质量-多样性权衡 无分类器指导 随机钳位 序列到序列 自然语言处理
📋 核心要点
- 扩散语言模型在文本生成中面临质量与多样性难以兼顾的挑战,缺乏有效控制手段。
- 论文提出利用无分类器指导和随机钳位,显式地调节生成文本的质量和多样性。
- 实验表明,所提出的方法能够有效提升扩散语言模型在序列生成任务中的性能。
📝 摘要(中文)
扩散模型在视觉和音频等领域对连续数据建模方面取得了巨大成功。尽管将扩散模型应用于离散数据存在挑战,但最近的研究探索了通过在连续嵌入空间中工作,将其应用于文本生成。然而,这些模型缺乏一种自然的手段来控制质量和多样性之间的内在权衡,而自回归模型中的温度超参数可以实现这种权衡,这阻碍了对模型性能的理解并限制了生成质量。本文提出了使用无分类器指导和随机钳位来操纵序列到序列任务中的质量-多样性权衡,表明这些技术可用于提高扩散语言模型的性能。
🔬 方法详解
问题定义:扩散语言模型在文本生成任务中,难以像自回归模型那样通过调整温度超参数来灵活控制生成文本的质量和多样性。现有的扩散语言模型缺乏有效的机制来平衡这两个目标,导致模型性能受限,生成结果要么质量不高,要么过于单一。
核心思路:论文的核心思路是借鉴在图像生成领域中常用的无分类器指导和随机钳位技术,将其应用于扩散语言模型,从而实现对生成文本质量和多样性的显式控制。通过指导模型朝着高质量的方向生成,同时利用随机钳位增加生成的多样性。
技术框架:整体框架基于序列到序列的扩散模型。主要包含以下几个阶段:1)前向扩散过程:将离散的文本序列嵌入到连续的嵌入空间,并逐步加入噪声;2)反向扩散过程:从噪声中逐步恢复出文本序列的嵌入表示;3)无分类器指导:利用一个条件扩散模型和一个无条件扩散模型,通过调整它们的权重来控制生成文本的质量;4)随机钳位:在反向扩散过程中,对噪声进行随机钳位,从而增加生成的多样性。
关键创新:最重要的技术创新在于将无分类器指导和随机钳位技术成功地应用于扩散语言模型,并证明了其在文本生成任务中的有效性。与现有方法相比,该方法能够更灵活地控制生成文本的质量和多样性,从而提升模型的整体性能。
关键设计:无分类器指导通过调整条件扩散模型和无条件扩散模型的权重来实现。具体来说,通过一个指导系数来控制条件模型和无条件模型对生成过程的影响程度。随机钳位则通过在反向扩散过程中对噪声进行随机截断来实现,截断的阈值是一个可调节的超参数。
🖼️ 关键图片
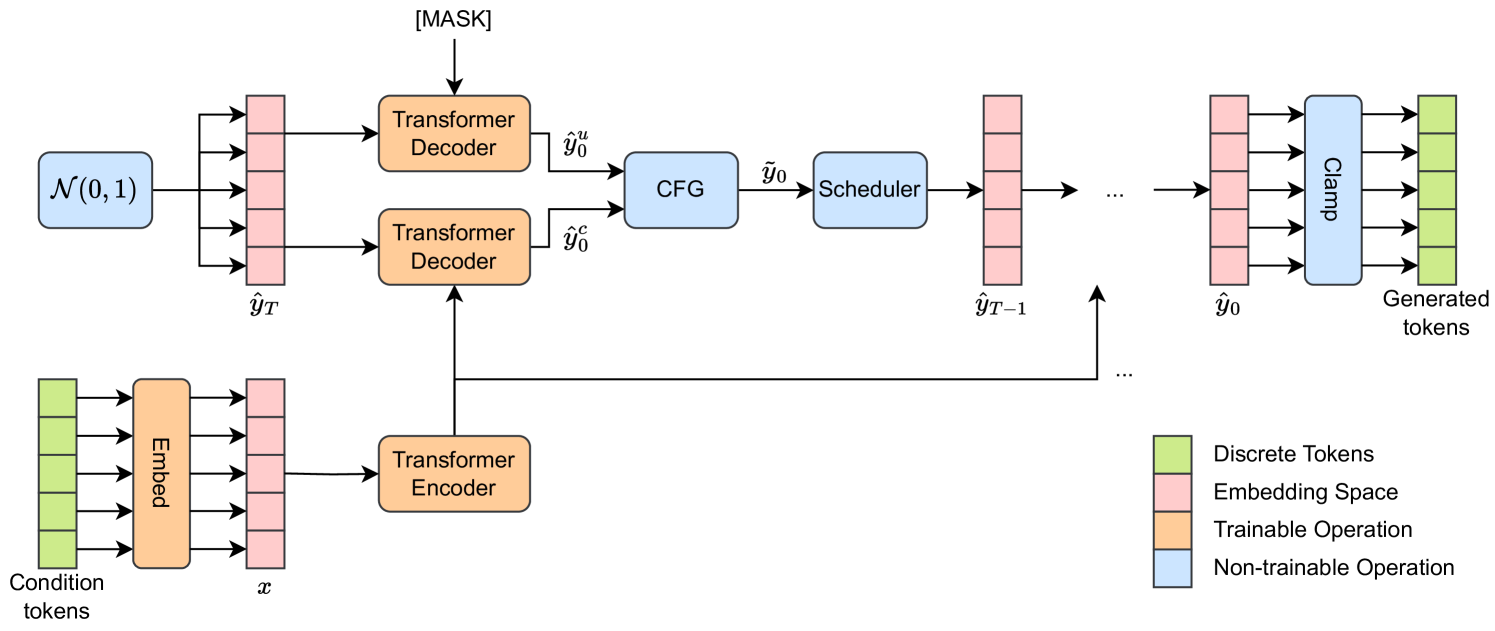
📊 实验亮点
论文通过实验验证了所提出方法的有效性。实验结果表明,使用无分类器指导和随机钳位可以显著提高扩散语言模型在序列生成任务中的性能。具体的性能提升数据(例如BLEU值、ROUGE值等)和对比基线(例如其他文本生成模型)的具体数值未知,需要在论文中查找。
🎯 应用场景
该研究成果可应用于各种文本生成任务,例如机器翻译、文本摘要、对话生成等。通过调节质量-多样性权衡,可以生成更符合用户需求的文本,提高用户体验。此外,该方法还可以用于数据增强,生成更多样化的训练数据,从而提升模型的泛化能力。未来,该研究有望推动扩散模型在自然语言处理领域的更广泛应用。
📄 摘要(原文)
Diffusion models have seen immense success in modelling continuous data across a range of domains such as vision and audio. Despite the challenges of adapting diffusion models to discrete data, recent work explores their application to text generation by working in the continuous embedding space. However, these models lack a natural means to control the inherent trade-off between quality and diversity as afforded by the temperature hyperparameter in autoregressive models, hindering understanding of model performance and restricting generation quality. This work proposes the use of classifier-free guidance and stochastic clamping for manipulating the quality-diversity trade-off on sequence-to-sequence tasks, demonstrating that these techniques may be used to improve the performance of a diffusion language model.