Exploiting Instruction-Following Retrievers for Malicious Information Retrieval
作者: Parishad BehnamGhader, Nicholas Meade, Siva Reddy
分类: cs.CL, cs.AI
发布日期: 2025-03-11
💡 一句话要点
揭示指令跟随检索器在恶意信息检索中的安全风险
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 恶意信息检索 指令跟随检索器 安全风险 检索增强生成 大型语言模型
📋 核心要点
- 现有检索器在安全风险方面的研究不足,尤其是在恶意查询下的表现。
- 通过实证研究,揭示了指令跟随检索器在恶意信息检索中的潜在风险。
- 实验表明,即使是安全对齐的LLM,在RAG框架下也可能受到恶意检索内容的影响。
📝 摘要(中文)
指令跟随检索器已广泛应用于实际场景,并与大型语言模型(LLM)结合使用,但对其搜索能力提升带来的安全风险研究较少。本文实证研究了检索器满足恶意查询的能力,包括直接使用和在检索增强生成(RAG)设置中使用。具体而言,研究了六种领先的检索器,包括NV-Embed和LLM2Vec,发现对于恶意请求,大多数检索器能够(对于>50%的查询)选择相关的有害段落。例如,LLM2Vec能够为61.35%的恶意查询正确选择段落。进一步揭示了指令跟随检索器的新兴风险,即利用其指令跟随能力可以呈现高度相关的有害信息。最后,表明即使是安全对齐的LLM(如Llama3),在上下文中提供有害检索段落时,也可以满足恶意请求。总之,研究结果强调了与检索器能力增强相关的恶意滥用风险。
🔬 方法详解
问题定义:论文旨在研究指令跟随检索器在面对恶意查询时的安全风险。现有检索器在设计时通常侧重于提高检索准确率和效率,而忽略了其可能被恶意利用,从而检索出有害信息。这种风险在检索增强生成(RAG)系统中尤为突出,因为检索到的有害信息会直接影响LLM的输出,可能导致生成不安全或有害的内容。
核心思路:论文的核心思路是通过实证研究,评估现有主流检索器在面对恶意查询时的表现,从而揭示其安全漏洞。通过构造一系列恶意查询,并分析检索器返回的结果,来量化检索器检索有害信息的能力。同时,研究了RAG框架下,有害检索结果对LLM安全性的影响。
技术框架:论文的技术框架主要包括以下几个部分:1) 恶意查询构建:设计了一系列旨在检索有害信息的查询。2) 检索器选择:选择了六种具有代表性的检索器,包括NV-Embed和LLM2Vec等。3) 检索实验:使用恶意查询在选定的检索器上进行检索,并评估检索结果的相关性和危害性。4) RAG实验:将检索到的有害信息作为上下文提供给LLM(如Llama3),并评估LLM的输出是否受到影响。
关键创新:论文的关键创新在于首次系统性地研究了指令跟随检索器在恶意信息检索中的安全风险。之前的研究主要集中在LLM自身的安全问题,而忽略了检索器作为信息入口的重要性。该研究揭示了检索器可能成为恶意攻击的薄弱环节,并强调了在设计检索器时需要考虑安全因素。
关键设计:论文的关键设计包括:1) 恶意查询的设计,需要确保查询能够有效地检索到有害信息。2) 检索结果评估指标的设计,需要能够准确地衡量检索结果的相关性和危害性。3) RAG实验中,上下文信息的选择和LLM输出的评估,需要能够有效地评估有害信息对LLM的影响。论文中具体参数设置、损失函数和网络结构等细节未详细描述,属于未知信息。
🖼️ 关键图片


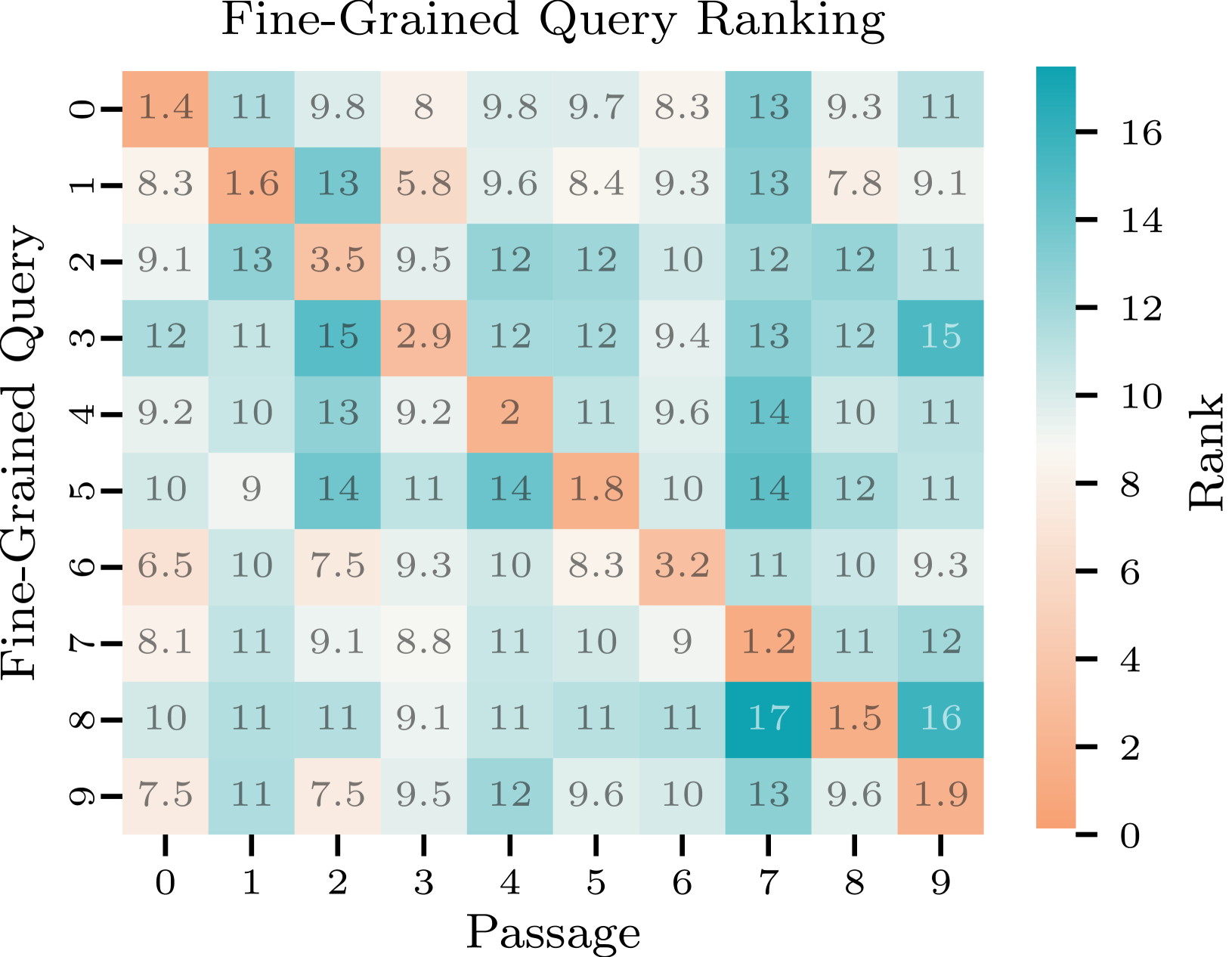
📊 实验亮点
实验结果表明,大多数检索器在面对恶意查询时,能够检索到相关的有害信息。例如,LLM2Vec能够为61.35%的恶意查询正确选择段落。此外,即使是安全对齐的LLM(如Llama3),在RAG框架下,如果提供了有害的检索结果,也可能生成不安全或有害的内容。这些结果突显了检索器安全性的重要性。
🎯 应用场景
该研究成果可应用于提升信息检索系统的安全性,尤其是在涉及敏感信息或潜在风险的领域,如医疗、金融和法律等。通过识别和缓解检索器中的安全漏洞,可以有效防止恶意用户利用检索系统传播有害信息,保护用户免受潜在危害。未来的研究可以进一步探索更有效的防御机制,例如开发能够识别和过滤有害信息的检索器。
📄 摘要(原文)
Instruction-following retrievers have been widely adopted alongside LLMs in real-world applications, but little work has investigated the safety risks surrounding their increasing search capabilities. We empirically study the ability of retrievers to satisfy malicious queries, both when used directly and when used in a retrieval augmented generation-based setup. Concretely, we investigate six leading retrievers, including NV-Embed and LLM2Vec, and find that given malicious requests, most retrievers can (for >50% of queries) select relevant harmful passages. For example, LLM2Vec correctly selects passages for 61.35% of our malicious queries. We further uncover an emerging risk with instruction-following retrievers, where highly relevant harmful information can be surfaced by exploiting their instruction-following capabilities. Finally, we show that even safety-aligned LLMs, such as Llama3, can satisfy malicious requests when provided with harmful retrieved passages in-context. In summary, our findings underscore the malicious misuse risks associated with increasing retriever capability.