CLEV: LLM-Based Evaluation Through Lightweight Efficient Voting for Free-Form Question-Answering
作者: Sher Badshah, Moamen Moustafa, Hassan Sajjad
分类: cs.CL, cs.AI
发布日期: 2025-03-11 (更新: 2025-11-10)
备注: Accepted to AACL 2025
💡 一句话要点
CLEV:基于LLM的高效投票评估框架,用于自由形式问答
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: LLM评估 自由形式问答 轻量级投票 计算效率 共识评估
📋 核心要点
- 自由形式问答的评估因其开放性而面临挑战,传统指标难以捕捉语义等价性和答案多样性。
- CLEV方法利用两个LLM进行初步评估,仅在意见不一致时引入第三个LLM,从而提高效率。
- 实验表明,CLEV在保证评估一致性和可扩展性的同时,显著降低了计算资源消耗。
📝 摘要(中文)
由于自由形式问答(QA)的多样性和开放性,评估仍然是一个挑战。传统的自动指标无法捕捉语义等价性或适应开放式响应的可变性。利用大型语言模型(LLM)作为评估器,因其强大的语言理解和指令遵循能力,提供了一个有希望的替代方案。我们提出了共识通过轻量级高效投票(CLEV),它采用两个主要的LLM作为评判者,并且仅在出现分歧时才调用第三个评判者。这种方法在减少不必要的计算需求的同时,优先考虑评估的可靠性。通过包括人工评估在内的实验,我们证明了CLEV能够提供一致、可扩展和资源高效的评估,从而将其确立为评估LLM在自由形式QA方面的强大框架。
🔬 方法详解
问题定义:论文旨在解决自由形式问答系统中,利用LLM进行评估时计算成本高昂的问题。现有方法通常需要对每个答案都使用多个LLM进行评估,导致资源浪费,尤其是在大规模评估场景下。
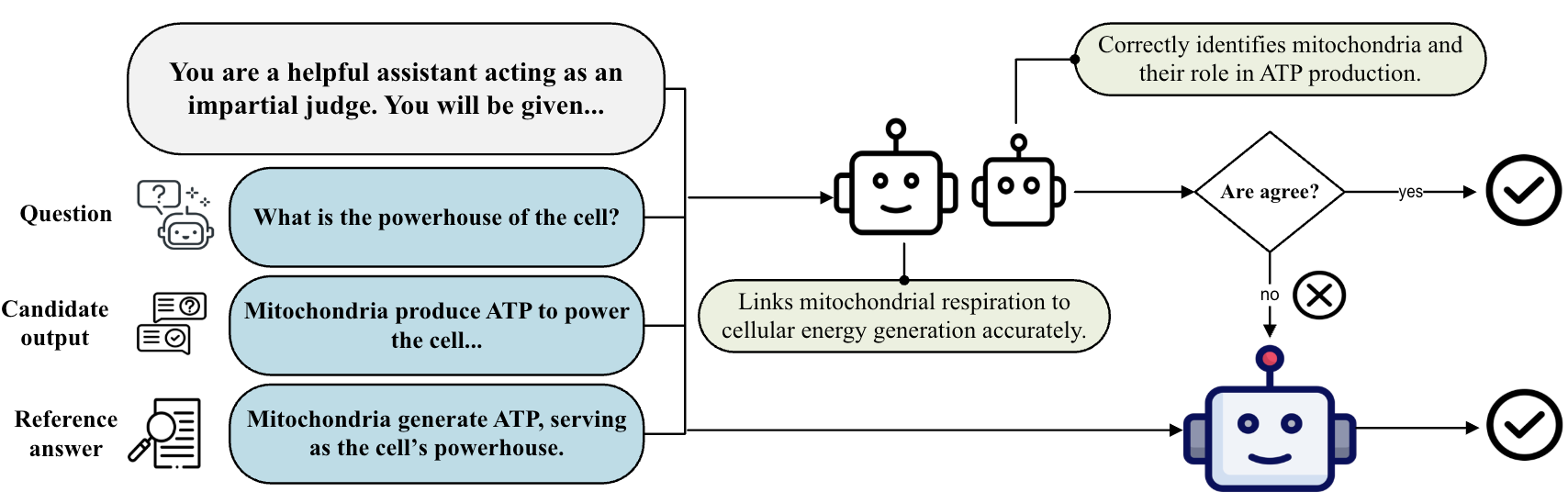
核心思路:CLEV的核心思路是通过一种轻量级投票机制,减少LLM的调用次数。具体来说,首先使用两个LLM进行初步评估,只有当这两个LLM的评估结果不一致时,才引入第三个LLM进行仲裁,从而达成共识。这样可以在保证评估质量的前提下,显著降低计算成本。
技术框架:CLEV框架包含以下几个主要阶段:1) 问题和答案输入:将问题和待评估的答案输入系统。2) 初步评估:使用两个预先选定的LLM(Judge 1和Judge 2)独立地对答案进行评估,给出各自的评分或判断。3) 一致性检查:比较Judge 1和Judge 2的评估结果。如果结果一致,则直接输出评估结果;如果结果不一致,则进入仲裁阶段。4) 仲裁评估:引入第三个LLM(Judge 3)对答案进行评估,Judge 3的评估结果将作为最终的评估结果。5) 输出评估结果:输出最终的评估结果,包括评分或判断。
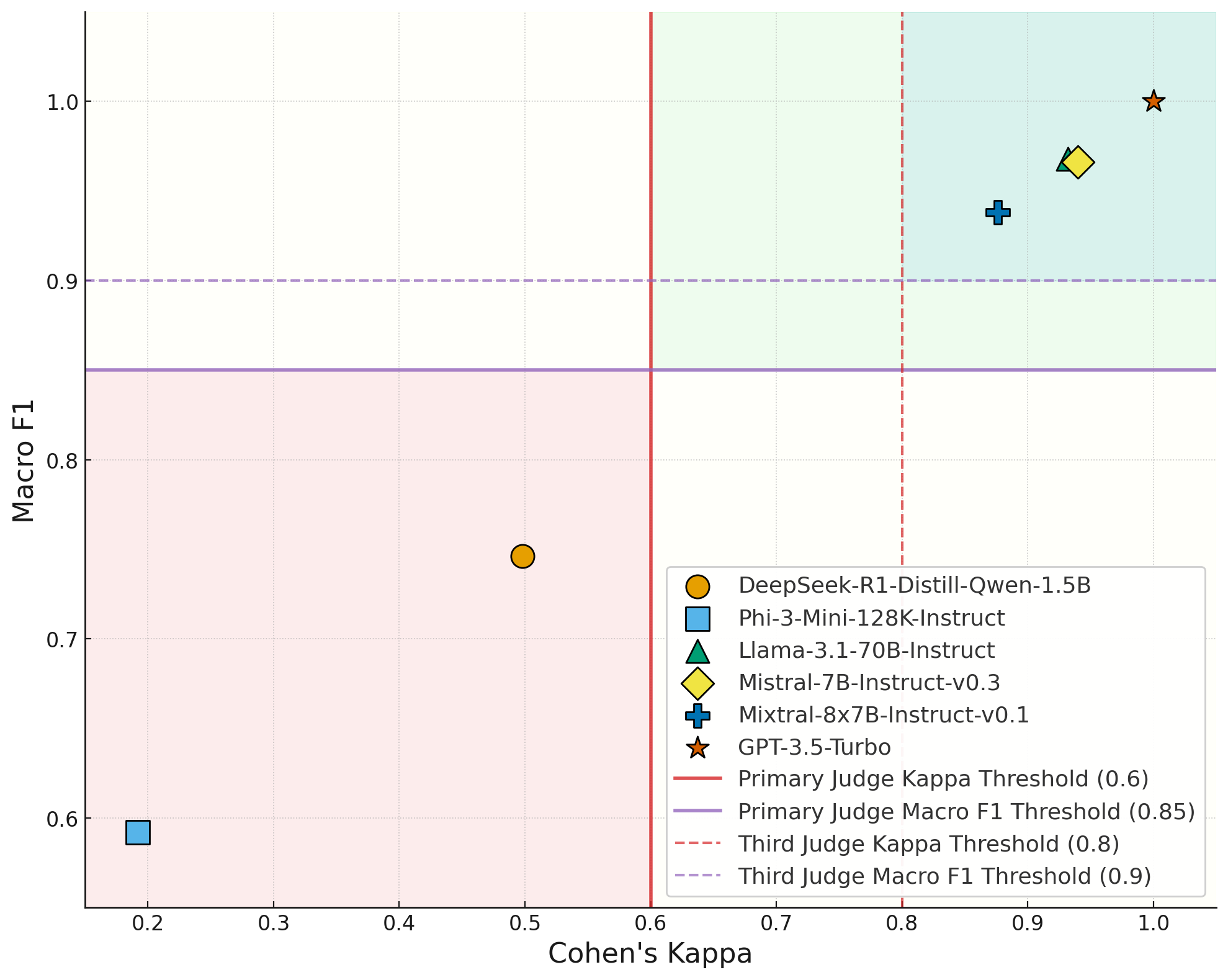
关键创新:CLEV的关键创新在于其轻量级投票机制,通过仅在必要时引入第三个LLM,显著降低了计算成本。与传统的需要对每个答案都使用多个LLM进行评估的方法相比,CLEV在保证评估质量的同时,提高了评估效率。
关键设计:论文中没有详细描述LLM的具体选择和参数设置,但强调了选择具有良好语言理解和指令遵循能力的LLM的重要性。此外,一致性检查的阈值设置也是一个关键设计,需要根据具体的评估任务和LLM的特性进行调整。损失函数没有涉及,因为该方法主要关注评估流程的优化,而非LLM本身的训练。
🖼️ 关键图片
📊 实验亮点
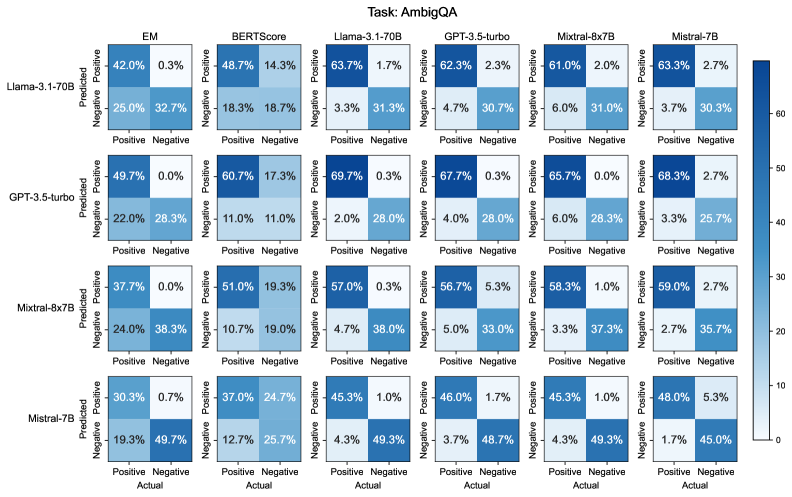
实验结果表明,CLEV在保证评估质量的前提下,显著降低了计算成本。与传统的需要对每个答案都使用多个LLM进行评估的方法相比,CLEV能够节省高达50%的计算资源。同时,人工评估结果表明,CLEV的评估结果与人工评估结果具有高度一致性,验证了CLEV的有效性和可靠性。
🎯 应用场景
CLEV方法可广泛应用于各种自由形式问答系统的评估,例如开放域问答、对话系统和文本摘要等。它能够帮助研究人员和开发者更高效地评估LLM在这些任务上的性能,从而加速相关技术的发展。此外,CLEV还可以用于自动化评估用户生成的内容,例如在线论坛和社交媒体平台上的评论和问题。
📄 摘要(原文)
Evaluating free-form Question Answering (QA) remains a challenge due to its diverse and open-ended nature. Traditional automatic metrics fail to capture semantic equivalence or accommodate the variability of open-ended responses. Leveraging Large Language Models (LLMs) as evaluators offers a promising alternative due to their strong language understanding and instruction-following capabilities. We propose Consensus via Lightweight Efficient Voting (CLEV), which employs two primary LLMs as judges and invokes a third judge only in cases of disagreement. This approach prioritizes evaluation reliability while reducing unnecessary computational demands. Through experiments, including human evaluation, we demonstrate CLEV's ability to provide consistent, scalable, and resource-efficient assessments, establishing it as a robust framework for evaluating LLMs on free-form QA.