ESPnet-SDS: Unified Toolkit and Demo for Spoken Dialogue Systems
作者: Siddhant Arora, Yifan Peng, Jiatong Shi, Jinchuan Tian, William Chen, Shikhar Bharadwaj, Hayato Futami, Yosuke Kashiwagi, Emiru Tsunoo, Shuichiro Shimizu, Vaibhav Srivastav, Shinji Watanabe
分类: cs.CL, cs.SD, eess.AS
发布日期: 2025-03-11
备注: Accepted at NAACL 2025 Demo Track
🔗 代码/项目: HUGGINGFACE
💡 一句话要点
ESPnet-SDS:用于语音对话系统的统一工具包与演示平台
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 语音对话系统 端到端系统 评估工具包 Web界面 自动评估 开源工具 ESPnet
📋 核心要点
- 现有语音对话系统缺乏统一的评估和比较平台,阻碍了研究进展。
- ESPnet-SDS提供统一的Web界面,支持多种级联和端到端语音对话系统。
- 该工具包提供实时评估指标,方便研究人员对比不同系统的性能。
📝 摘要(中文)
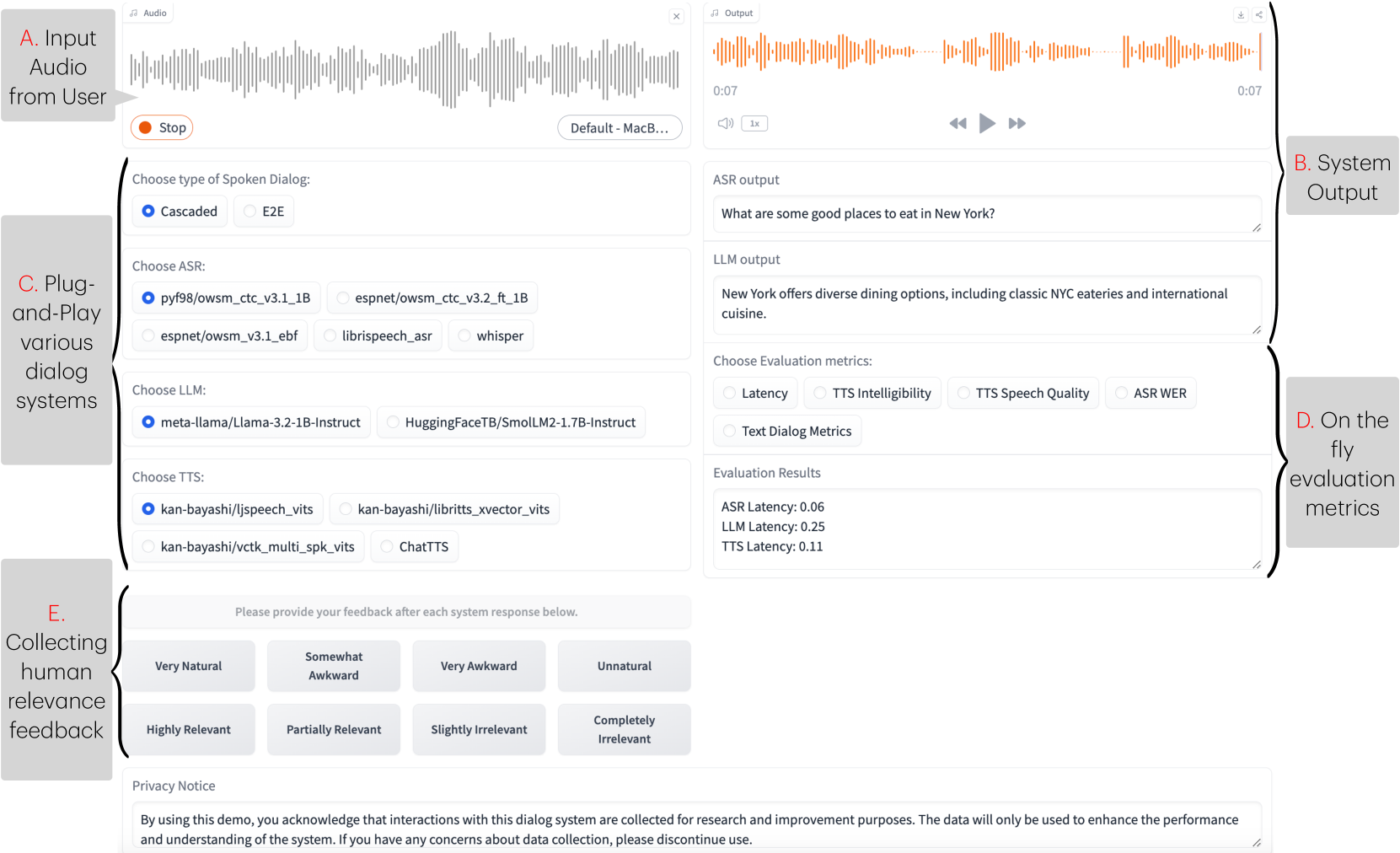
音频基础模型(FMs)的进步激发了人们对端到端(E2E)语音对话系统的兴趣,但每个系统使用不同的Web界面使得有效比较和对比它们变得具有挑战性。为此,我们引入了一个开源、用户友好的工具包,旨在为各种级联和E2E语音对话系统构建统一的Web界面。我们的演示进一步为用户提供了实时自动评估指标,例如(1)延迟,(2)理解用户输入的能力,(3)系统响应的连贯性、多样性和相关性,以及(4)系统输出的可理解性和音频质量。利用这些评估指标,我们使用人与人对话数据集作为代理,比较了各种级联和E2E语音对话系统。我们的分析表明,该工具包使研究人员能够轻松地比较和对比不同的技术,从而提供有价值的见解,例如当前E2E系统具有较差的音频质量和较少的多样性响应。使用我们的工具包生成的演示示例可在此处公开获得:https://huggingface.co/spaces/Siddhant/Voice_Assistant_Demo。
🔬 方法详解
问题定义:现有语音对话系统,特别是端到端系统,缺乏一个统一的评估和比较平台。不同的系统通常有各自独立的Web界面,这使得研究人员难以进行公平、高效的对比分析,从而阻碍了相关技术的发展。此外,缺乏标准化的评估指标也使得系统性能的客观衡量变得困难。
核心思路:ESPnet-SDS的核心思路是构建一个开源、用户友好的工具包,为各种级联和端到端语音对话系统提供统一的Web界面和评估框架。通过提供标准化的评估指标和统一的交互界面,该工具包旨在简化不同系统之间的比较和对比,从而加速语音对话系统的研究和开发。
技术框架:ESPnet-SDS工具包主要包含以下几个核心模块:(1) 统一的Web界面:提供标准化的用户交互界面,支持多种语音对话系统接入。(2) 自动评估模块:提供实时评估指标,包括延迟、理解能力、响应质量(连贯性、多样性、相关性)和音频质量。(3) 系统集成模块:方便研究人员将现有的或新开发的语音对话系统集成到该平台。(4) 数据集接口:支持使用标准数据集进行系统评估和比较。整体流程是从用户输入语音开始,系统将语音传递给集成的语音对话系统,然后将系统的响应返回给用户,同时自动评估模块会计算各项性能指标。
关键创新:ESPnet-SDS的关键创新在于其统一的Web界面和自动评估框架。与以往每个系统都有独立界面的方式不同,该工具包提供了一个标准化的平台,使得研究人员可以方便地比较和对比不同的系统。此外,自动评估模块可以实时提供多种性能指标,从而简化了系统评估的过程。
关键设计:ESPnet-SDS的关键设计包括:(1) 使用Hugging Face Spaces构建Web界面,方便部署和访问。(2) 采用标准化的API接口,方便不同语音对话系统的集成。(3) 定义了一系列客观的评估指标,包括延迟、理解能力、响应质量和音频质量,并提供了相应的计算方法。(4) 提供了详细的文档和示例代码,方便用户使用和扩展。
🖼️ 关键图片

📊 实验亮点
该论文通过实验对比了多种级联和端到端语音对话系统,发现当前端到端系统在音频质量和响应多样性方面仍有不足。实验结果表明,ESPnet-SDS工具包能够有效地评估和比较不同的语音对话系统,为研究人员提供了有价值的参考。
🎯 应用场景
ESPnet-SDS可广泛应用于语音助手、智能客服、人机对话等领域。该工具包能够帮助研究人员快速评估和比较不同的语音对话系统,从而加速相关技术的研发。此外,该工具包还可以用于教育和培训,帮助学生和工程师更好地理解和掌握语音对话系统的相关知识。
📄 摘要(原文)
Advancements in audio foundation models (FMs) have fueled interest in end-to-end (E2E) spoken dialogue systems, but different web interfaces for each system makes it challenging to compare and contrast them effectively. Motivated by this, we introduce an open-source, user-friendly toolkit designed to build unified web interfaces for various cascaded and E2E spoken dialogue systems. Our demo further provides users with the option to get on-the-fly automated evaluation metrics such as (1) latency, (2) ability to understand user input, (3) coherence, diversity, and relevance of system response, and (4) intelligibility and audio quality of system output. Using the evaluation metrics, we compare various cascaded and E2E spoken dialogue systems with a human-human conversation dataset as a proxy. Our analysis demonstrates that the toolkit allows researchers to effortlessly compare and contrast different technologies, providing valuable insights such as current E2E systems having poorer audio quality and less diverse responses. An example demo produced using our toolkit is publicly available here: https://huggingface.co/spaces/Siddhant/Voice_Assistant_Demo.