ReviewAgents: Bridging the Gap Between Human and AI-Generated Paper Reviews
作者: Xian Gao, Jiacheng Ruan, Zongyun Zhang, Jingsheng Gao, Ting Liu, Yuzhuo Fu
分类: cs.CL
发布日期: 2025-03-11 (更新: 2025-07-16)
备注: Work in progress
💡 一句话要点
提出ReviewAgents框架,利用LLM生成高质量学术论文评审意见,缩小与人类评审的差距。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 学术论文评审 自动化评审 结构化推理 多Agent系统
📋 核心要点
- 现有学术论文评审耗时且难以自动化,主要挑战在于生成与人类评审员判断一致的全面、准确和推理一致的评审意见。
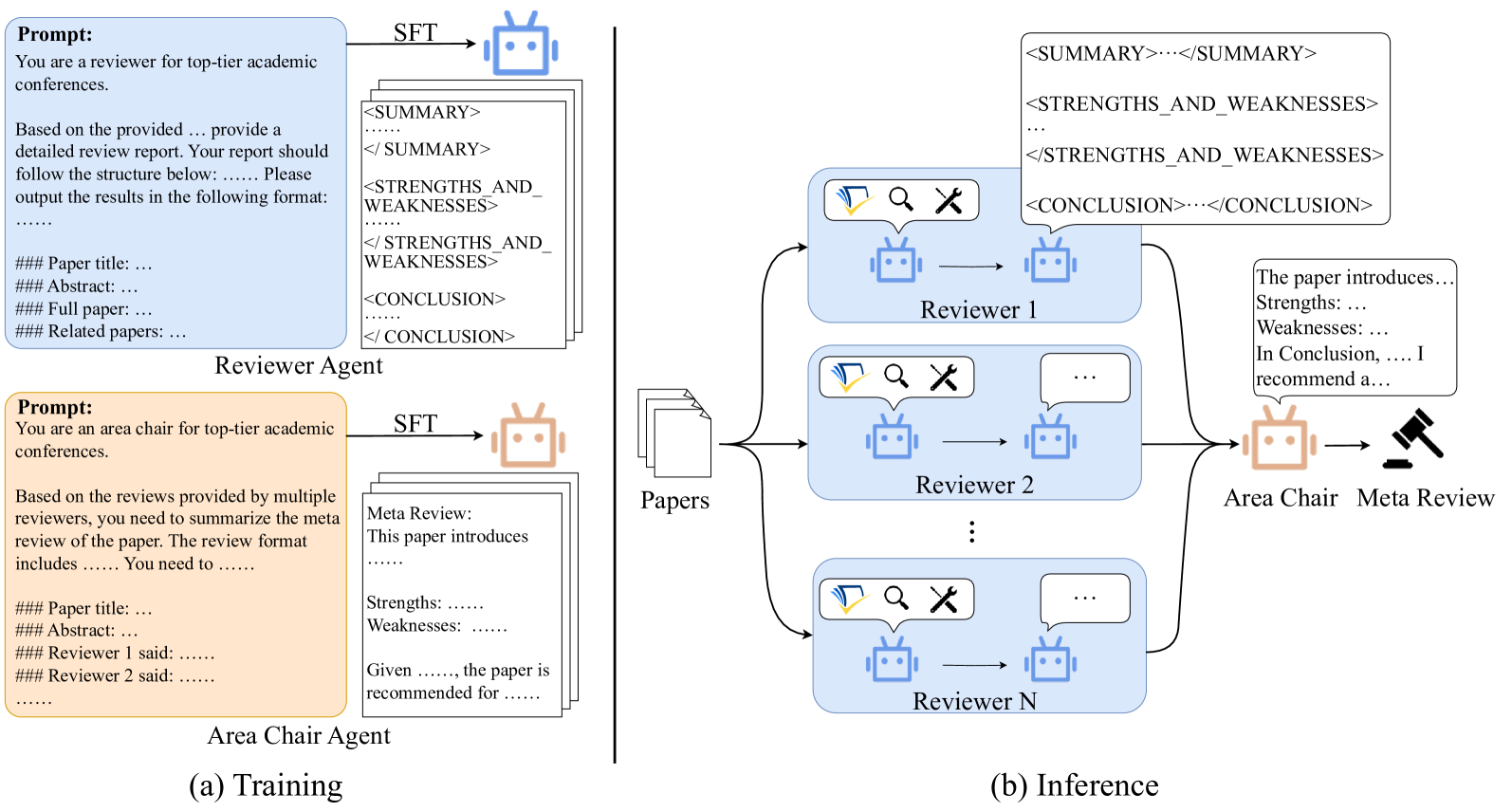
- ReviewAgents框架利用大型语言模型,通过构建Review-CoT数据集和训练LLM评审Agent,模拟人类评审员的结构化推理过程。
- 实验结果表明,ReviewAgents框架缩小了LLM生成评审意见与人类评审意见之间的差距,并在ReviewBench基准测试中优于先进的LLM。
📝 摘要(中文)
学术论文评审是研究领域一项关键但耗时的任务。随着学术出版物数量的增加,评审过程的自动化已成为一项重大挑战。主要问题在于生成全面、准确且推理一致的评审意见,使其与人类评审员的判断相符。本文提出了ReviewAgents框架,该框架利用大型语言模型(LLM)生成学术论文评审。首先,引入了一个名为Review-CoT的新数据集,包含142k条评审意见,用于训练LLM Agent。该数据集模拟了人类评审员的结构化推理过程——总结论文、引用相关工作、识别优点和缺点,并生成评审结论。在此基础上,使用相关论文感知训练方法训练了能够进行结构化推理的LLM评审Agent。此外,构建了ReviewAgents,一个多角色、多LLM Agent评审框架,以增强评审意见生成过程。同时,提出了ReviewBench,一个用于评估LLM生成的评审意见的基准。在ReviewBench上的实验结果表明,现有的LLM在自动化评审过程方面表现出一定的潜力,但与人类生成的评审意见相比仍存在差距。ReviewAgents框架进一步缩小了这一差距,在生成评审意见方面优于先进的LLM。
🔬 方法详解
问题定义:学术论文评审任务繁重且耗时,现有方法难以生成高质量、与人类评审员一致的评审意见。现有方法的痛点在于缺乏结构化的推理过程模拟,以及对相关论文的有效利用。
核心思路:论文的核心解决思路是利用大型语言模型(LLM)模拟人类评审员的结构化推理过程,包括总结论文、引用相关工作、识别优缺点和生成结论。通过构建Review-CoT数据集,并采用相关论文感知训练方法,使LLM能够更好地理解和评估论文。
技术框架:ReviewAgents框架是一个多角色、多LLM Agent评审框架。它包含以下主要模块:1) Review-CoT数据集构建,用于训练LLM Agent;2) 相关论文感知训练方法,使LLM能够利用相关论文进行评审;3) 多角色LLM Agent协同,增强评审意见生成过程;4) ReviewBench基准测试,用于评估LLM生成的评审意见。
关键创新:最重要的技术创新点在于Review-CoT数据集的构建和相关论文感知训练方法。Review-CoT数据集模拟了人类评审员的结构化推理过程,为LLM提供了高质量的训练数据。相关论文感知训练方法使LLM能够利用相关论文进行评审,提高了评审意见的质量和准确性。
关键设计:Review-CoT数据集包含142k条评审意见,涵盖了多个学术领域。相关论文感知训练方法通过检索相关论文,并将相关信息融入到LLM的输入中,使LLM能够更好地理解和评估论文。ReviewBench基准测试包含多个评估指标,用于评估LLM生成的评审意见的质量、准确性和一致性。具体参数设置和损失函数等技术细节在论文中未详细说明,属于未知信息。
🖼️ 关键图片


📊 实验亮点
实验结果表明,ReviewAgents框架在ReviewBench基准测试中优于先进的LLM,缩小了LLM生成评审意见与人类评审意见之间的差距。具体的性能提升数据在摘要中未明确给出,但强调了ReviewAgents框架的优越性。该研究证明了LLM在自动化评审过程中的潜力,并为未来的研究方向提供了指导。
🎯 应用场景
该研究成果可应用于自动化学术论文评审流程,减轻评审员负担,提高评审效率。此外,该框架还可用于辅助科研人员进行论文写作,通过模拟评审过程,帮助作者发现论文中的不足之处并进行改进。未来,该技术有望应用于更广泛的文本评估和生成领域。
📄 摘要(原文)
Academic paper review is a critical yet time-consuming task within the research community. With the increasing volume of academic publications, automating the review process has become a significant challenge. The primary issue lies in generating comprehensive, accurate, and reasoning-consistent review comments that align with human reviewers' judgments. In this paper, we address this challenge by proposing ReviewAgents, a framework that leverages large language models (LLMs) to generate academic paper reviews. We first introduce a novel dataset, Review-CoT, consisting of 142k review comments, designed for training LLM agents. This dataset emulates the structured reasoning process of human reviewers-summarizing the paper, referencing relevant works, identifying strengths and weaknesses, and generating a review conclusion. Building upon this, we train LLM reviewer agents capable of structured reasoning using a relevant-paper-aware training method. Furthermore, we construct ReviewAgents, a multi-role, multi-LLM agent review framework, to enhance the review comment generation process. Additionally, we propose ReviewBench, a benchmark for evaluating the review comments generated by LLMs. Our experimental results on ReviewBench demonstrate that while existing LLMs exhibit a certain degree of potential for automating the review process, there remains a gap when compared to human-generated reviews. Moreover, our ReviewAgents framework further narrows this gap, outperforming advanced LLMs in generating review comments.