Towards Large Language Models that Benefit for All: Benchmarking Group Fairness in Reward Models
作者: Kefan Song, Jin Yao, Runnan Jiang, Rohan Chandra, Shangtong Zhang
分类: cs.CL, cs.AI, cs.CY, cs.LG
发布日期: 2025-03-10
💡 一句话要点
评估奖励模型中的群体公平性,揭示现有模型在不同人群上的显著不公平现象
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 群体公平性 奖励模型 偏见评估 RLHF
📋 核心要点
- 现有LLM公平性研究要求不同群体使用相同提示,这在实际应用中难以满足,限制了研究的适用性。
- 该研究通过评估奖励模型的群体公平性,旨在识别LLM流程中偏见的来源,从而为缓解偏见提供更有效的策略。
- 实验结果表明,即使是表现良好的奖励模型也存在显著的群体不公平性,这突显了该领域进一步研究的必要性。
📝 摘要(中文)
大型语言模型(LLM)日益强大并易于用户访问,确保不同人群之间的公平性,即群体公平性,是一个重要的伦理问题。然而,当前LLM中的公平性和偏见研究存在两个局限性。首先,与传统机器学习分类中的群体公平性相比,它要求不同群体使用相同的提示问题,这在许多实际场景中是不切实际的。其次,它仅评估LLM最终输出的群体公平性,而未识别可能的偏见来源,即LLM输出中的偏见可能来自预训练和微调。对于微调,偏见可能来自RLHF过程和学习到的奖励模型。评估LLM流程中每个组件的群体公平性有助于开发更好的方法来缓解可能的偏见。本研究针对这些局限性,对学习到的奖励模型的群体公平性进行基准测试。通过使用arXiv的专家撰写文本,我们能够在不需要不同人群使用相同提示问题的情况下,对奖励模型的群体公平性进行基准测试。令人惊讶的是,我们的结果表明,所有评估的奖励模型(例如,Nemotron-4-340B-Reward、ArmoRM-Llama3-8B-v0.1和GRM-llama3-8B-sftreg)都表现出统计上显著的群体不公平性。我们还观察到,在规范性能指标方面表现最佳的奖励模型往往表现出更好的群体公平性。
🔬 方法详解
问题定义:现有LLM的公平性研究主要集中在最终输出层面,忽略了奖励模型可能存在的群体偏见。此外,现有方法通常假设不同群体使用相同的提示问题,这在实际应用中是不合理的。因此,需要一种能够评估奖励模型在不同提示下对不同群体公平性的方法。
核心思路:该论文的核心思路是直接评估奖励模型对不同群体文本的奖励得分,从而衡量其群体公平性。通过使用来自arXiv的专家撰写文本,可以避免对不同群体使用相同提示的要求,更贴近实际应用场景。
技术框架:该研究的技术框架主要包括以下几个步骤:1) 收集来自arXiv的专家撰写文本,作为评估奖励模型的数据集。2) 选择多个具有代表性的奖励模型进行评估,例如Nemotron-4-340B-Reward、ArmoRM-Llama3-8B-v0.1和GRM-llama3-8B-sftreg。3) 使用这些奖励模型对不同群体的文本进行打分。4) 分析不同群体之间的奖励得分差异,以评估奖励模型的群体公平性。
关键创新:该论文的关键创新在于:1) 提出了一个更贴近实际应用场景的群体公平性评估方法,允许不同群体使用不同的提示问题。2) 将群体公平性评估的范围扩展到奖励模型,从而能够更全面地了解LLM中的偏见来源。
关键设计:该研究的关键设计包括:1) 使用来自arXiv的专家撰写文本,保证了评估数据的质量和多样性。2) 选择了多个具有代表性的奖励模型进行评估,从而能够更全面地了解现有奖励模型的群体公平性状况。3) 使用统计显著性检验来评估不同群体之间的奖励得分差异,从而保证了评估结果的可靠性。
🖼️ 关键图片

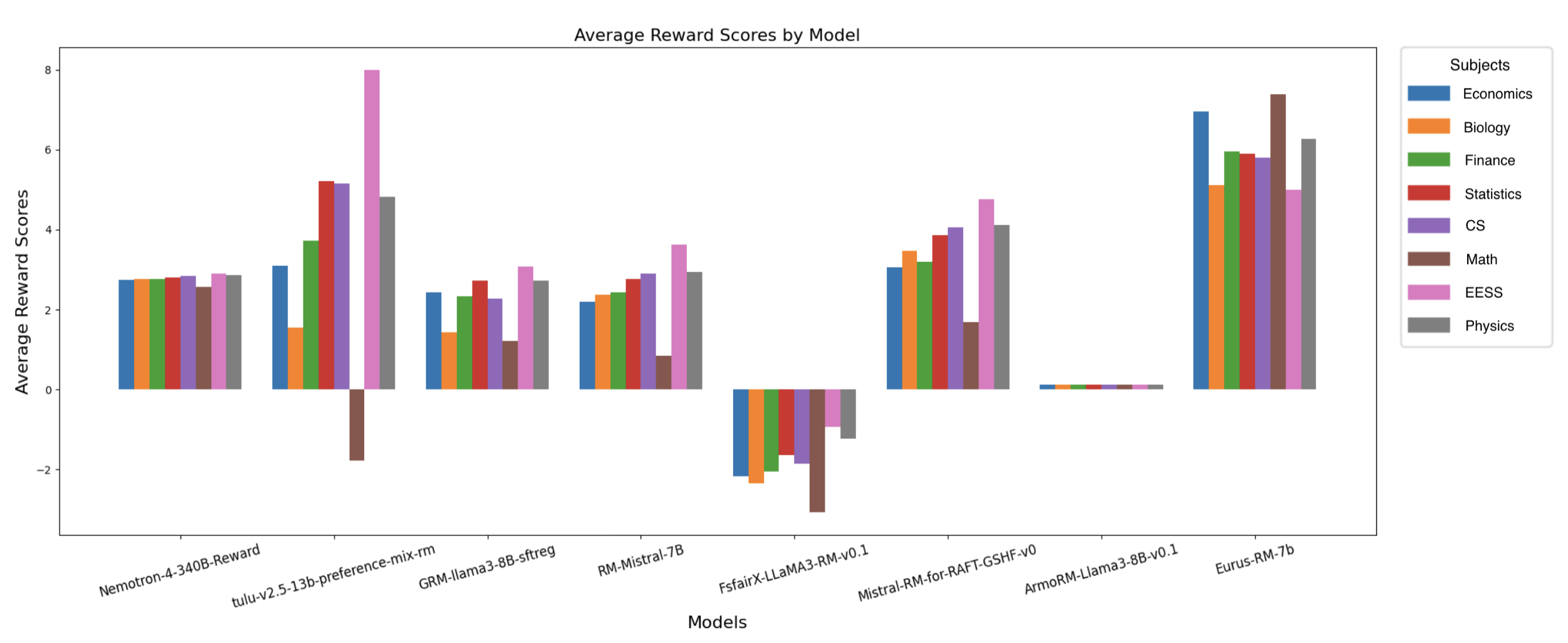
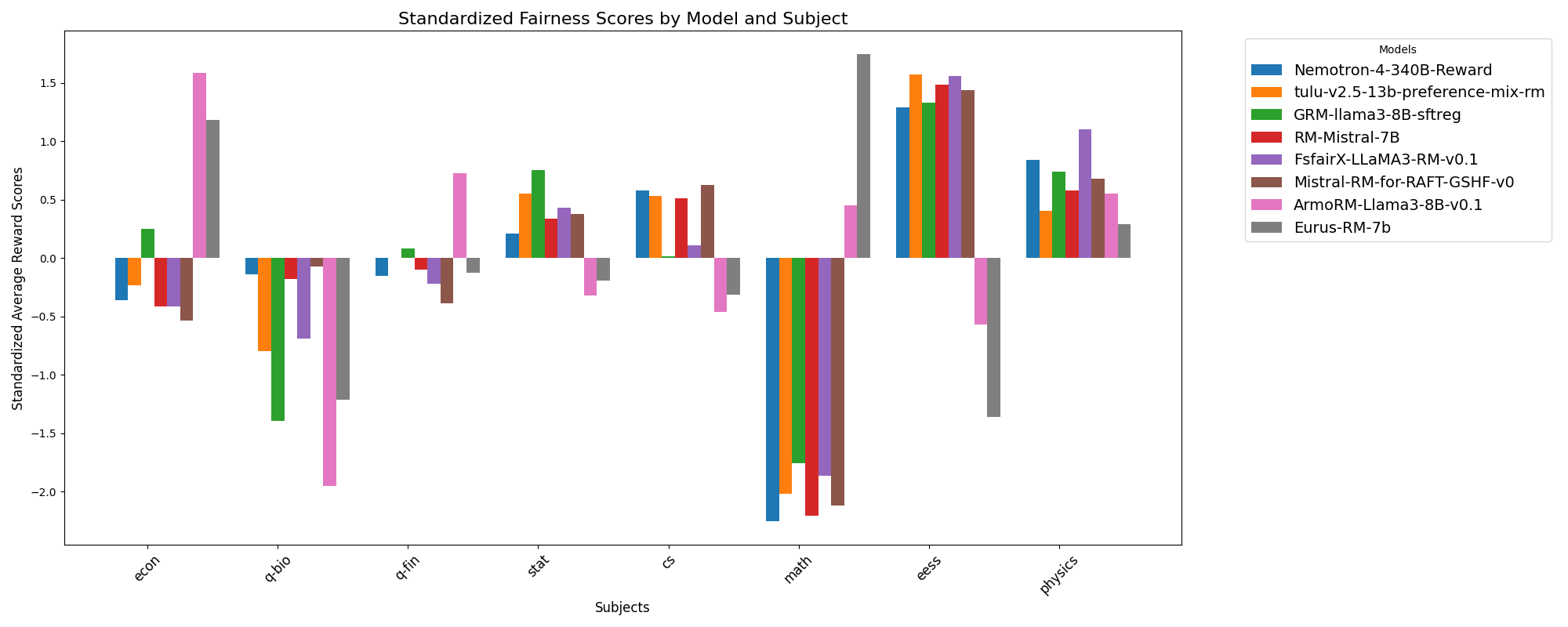
📊 实验亮点
实验结果表明,所有评估的奖励模型(包括Nemotron-4-340B-Reward、ArmoRM-Llama3-8B-v0.1和GRM-llama3-8B-sftreg)都表现出统计上显著的群体不公平性。此外,研究发现,在规范性能指标方面表现最佳的奖励模型往往表现出更好的群体公平性,但即使是这些模型仍然存在显著的群体偏见。
🎯 应用场景
该研究成果可应用于开发更公平的LLM系统,尤其是在涉及敏感人群的应用场景中,例如医疗诊断、法律咨询等。通过评估和改进奖励模型的群体公平性,可以减少LLM对特定人群的偏见,提高其在各个领域的可用性和可信度。未来的研究可以进一步探索缓解奖励模型群体偏见的方法。
📄 摘要(原文)
As Large Language Models (LLMs) become increasingly powerful and accessible to human users, ensuring fairness across diverse demographic groups, i.e., group fairness, is a critical ethical concern. However, current fairness and bias research in LLMs is limited in two aspects. First, compared to traditional group fairness in machine learning classification, it requires that the non-sensitive attributes, in this case, the prompt questions, be the same across different groups. In many practical scenarios, different groups, however, may prefer different prompt questions and this requirement becomes impractical. Second, it evaluates group fairness only for the LLM's final output without identifying the source of possible bias. Namely, the bias in LLM's output can result from both the pretraining and the finetuning. For finetuning, the bias can result from both the RLHF procedure and the learned reward model. Arguably, evaluating the group fairness of each component in the LLM pipeline could help develop better methods to mitigate the possible bias. Recognizing those two limitations, this work benchmarks the group fairness of learned reward models. By using expert-written text from arXiv, we are able to benchmark the group fairness of reward models without requiring the same prompt questions across different demographic groups. Surprisingly, our results demonstrate that all the evaluated reward models (e.g., Nemotron-4-340B-Reward, ArmoRM-Llama3-8B-v0.1, and GRM-llama3-8B-sftreg) exhibit statistically significant group unfairness. We also observed that top-performing reward models (w.r.t. canonical performance metrics) tend to demonstrate better group fairness.