KSOD: Knowledge Supplement for LLMs On Demand
作者: Haoran Li, Junfeng Hu
分类: cs.CL, cs.AI, cs.LG
发布日期: 2025-03-10
💡 一句话要点
提出KSOD框架,按需为LLM补充知识以提升领域任务性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 知识补充 监督微调 领域知识 知识模块
📋 核心要点
- 现有LLM在特定领域任务中表现不佳,主要原因是缺乏相关领域的知识。
- KSOD框架通过识别LLM缺失的知识,并利用知识模块进行补充,从而提升LLM的性能。
- 实验结果表明,KSOD在提升特定领域任务性能的同时,保持了LLM在其他任务上的性能。
📝 摘要(中文)
大型语言模型(LLM)在各种任务中表现出卓越的能力,但在特定领域任务中仍然会产生错误。为了进一步提高其性能,我们提出了一种新颖的框架KSOD(按需为LLM补充知识),该框架使LLM能够通过基于知识的监督微调(SFT)来提高其能力。KSOD通过识别LLM中可能导致错误的潜在缺失知识,从知识缺陷的角度分析错误的原因。随后,KSOD在知识数据集上调整知识模块,并验证LLM是否缺乏基于该模块识别的知识。如果知识得到验证,KSOD使用知识模块为LLM补充已识别的知识。在特定知识而非特定任务上调整LLM,将任务和知识解耦。我们在两个领域特定基准和四个通用基准上的实验经验表明,KSOD增强了LLM在需要补充知识的任务上的性能,同时保留了它们在其他任务上的性能。我们的发现揭示了通过基于知识的SFT提高LLM能力的潜力。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在特定领域任务中由于知识不足而产生错误的问题。现有方法通常针对特定任务进行微调,导致任务与知识耦合,泛化能力受限。此外,直接对LLM进行微调成本较高,且容易遗忘已掌握的知识。
核心思路:KSOD的核心思路是按需为LLM补充知识,而非直接针对特定任务进行微调。通过识别LLM缺失的知识,训练一个独立的知识模块,并将该模块的知识注入到LLM中。这种方法将任务和知识解耦,提高了模型的泛化能力,并降低了微调成本。
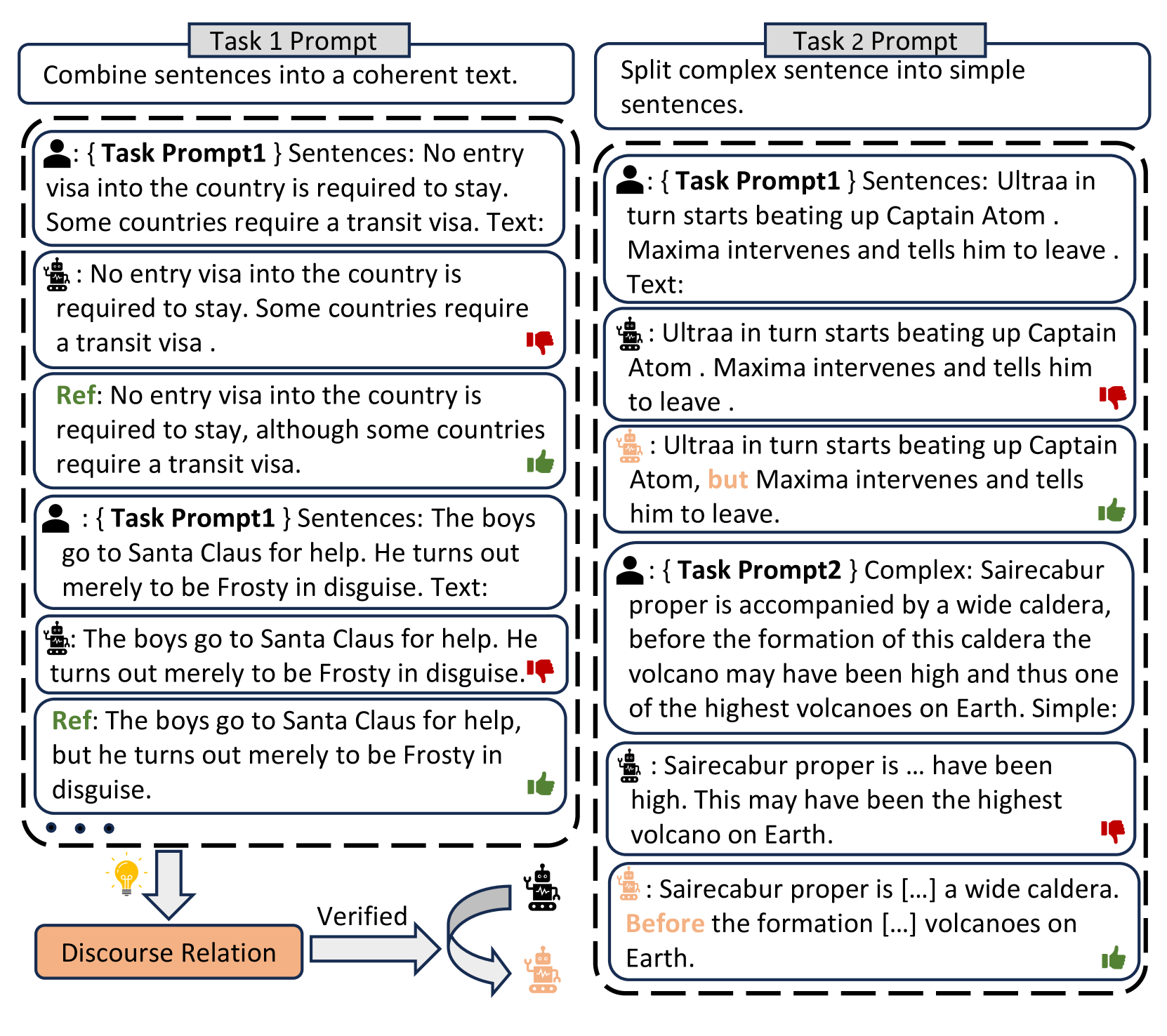
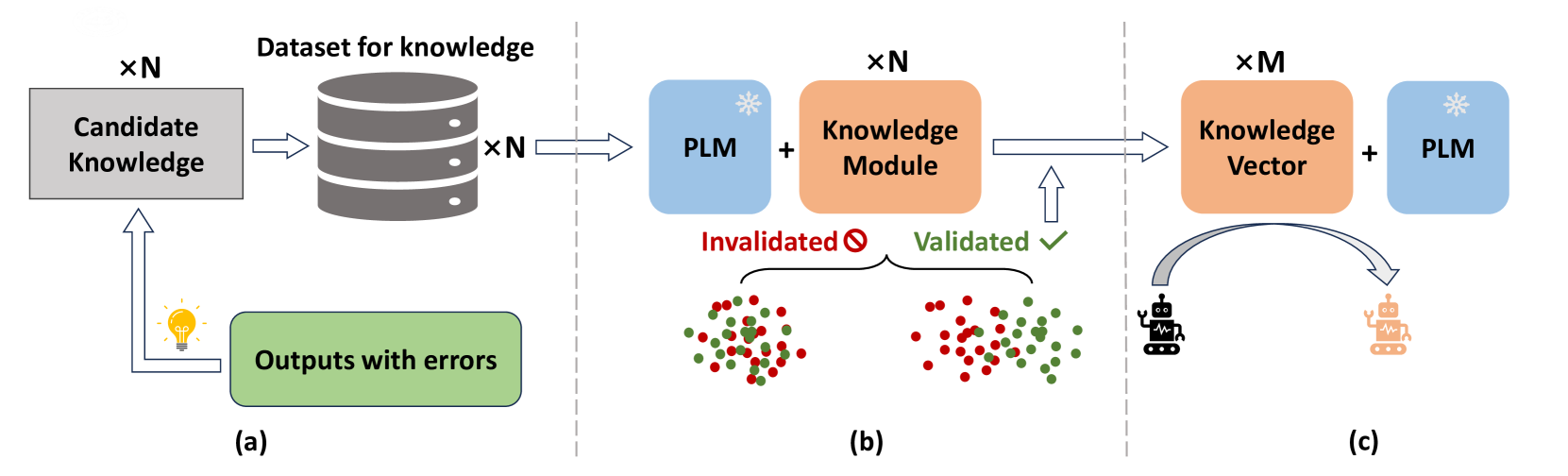
技术框架:KSOD框架主要包含以下几个阶段:1) 错误分析:分析LLM在特定领域任务中产生的错误,识别潜在的知识缺陷。2) 知识识别:根据错误分析的结果,确定LLM需要补充的知识。3) 知识模块训练:使用知识数据集训练一个知识模块,该模块能够编码和表示所需的知识。4) 知识验证:验证LLM是否缺乏已识别的知识,通过知识模块进行验证。5) 知识补充:如果知识得到验证,则使用知识模块为LLM补充已识别的知识。
关键创新:KSOD的关键创新在于按需补充知识的策略,以及知识模块的引入。与传统的任务特定微调方法相比,KSOD能够更有效地提升LLM在特定领域任务中的性能,同时保持其在其他任务上的性能。此外,知识模块的设计使得知识的补充更加灵活和可控。
关键设计:论文中知识模块的具体实现细节未知,可能采用Transformer或其他适合知识表示的网络结构。损失函数的设计可能包括知识重构损失、知识对齐损失等,以确保知识模块能够准确地编码和表示所需的知识。具体的参数设置和训练策略未知。
🖼️ 关键图片

📊 实验亮点
论文在两个领域特定基准和四个通用基准上进行了实验,结果表明KSOD能够有效提升LLM在需要补充知识的任务上的性能,同时保持其在其他任务上的性能。具体的性能提升数据未知,但实验结果验证了KSOD框架的有效性。
🎯 应用场景
KSOD框架可应用于各种需要领域知识的LLM应用场景,例如医疗诊断、金融分析、法律咨询等。通过按需补充知识,可以显著提升LLM在这些领域的专业能力,使其能够更好地服务于实际应用。该研究为LLM的持续学习和知识更新提供了一种新的思路,具有重要的实际价值和未来影响。
📄 摘要(原文)
Large Language Models (LLMs) have demonstrated remarkable capabilities in various tasks, yet still produce errors in domain-specific tasks. To further improve their performance, we propose KSOD (Knowledge Supplement for LLMs On Demand), a novel framework that empowers LLMs to improve their capabilities with knowledge-based supervised fine-tuning (SFT). KSOD analyzes the causes of errors from the perspective of knowledge deficiency by identifying potential missing knowledge in LLM that may lead to the errors. Subsequently, KSOD tunes a knowledge module on knowledge dataset and verifies whether the LLM lacks the identified knowledge based on it. If the knowledge is verified, KSOD supplements the LLM with the identified knowledge using the knowledge module. Tuning LLMs on specific knowledge instead of specific task decouples task and knowledge and our experiments on two domain-specific benchmarks and four general benchmarks empirically demonstrate that KSOD enhances the performance of LLMs on tasks requiring the supplemented knowledge while preserving their performance on other tasks. Our findings shed light on the potential of improving the capabilities of LLMs with knowledge-based SFT.