XIFBench: Evaluating Large Language Models on Multilingual Instruction Following
作者: Zhenyu Li, Kehai Chen, Yunfei Long, Xuefeng Bai, Yaoyin Zhang, Xuchen Wei, Juntao Li, Min Zhang
分类: cs.CL
发布日期: 2025-03-10 (更新: 2025-11-03)
备注: Accepted by the NeurIPS 2025 Datasets and Benchmarks Track
🔗 代码/项目: GITHUB
💡 一句话要点
XIFBench:一个用于评估大语言模型多语言指令遵循能力的综合基准
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 多语言 指令遵循 基准测试 约束分析
📋 核心要点
- 现有的大语言模型多语言指令遵循能力评估缺乏细粒度的约束分析,难以全面衡量模型性能。
- XIFBench通过构建包含多种约束类型和语言的基准,并引入文化可访问性标注等方法,实现了更可靠的跨语言评估。
- 实验结果揭示了语言资源、约束类别等因素对多语言指令遵循的影响,为模型改进提供了详细的分析。
📝 摘要(中文)
大语言模型(LLMs)在各种应用中展示了卓越的指令遵循能力。然而,它们在多语言环境下的性能缺乏系统的研究,现有的评估也缺乏对不同语言环境下的细粒度约束分析。我们推出了XIFBench,这是一个综合的、基于约束的基准,用于评估LLMs的多语言指令遵循能力。它包含558条指令,带有0-5个附加约束,涵盖五个类别(内容、风格、情境、格式和数值),涉及六种不同资源水平的语言。为了支持可靠和一致的跨语言评估,我们实现了三个方法创新:文化可访问性标注、约束级别翻译验证以及使用英语需求作为跨语言语义锚点的基于需求的评估。对各种LLMs的大量实验不仅量化了不同资源水平之间的性能差异,而且还详细地揭示了语言资源、约束类别、指令复杂性和文化特殊性如何影响多语言指令遵循。
🔬 方法详解
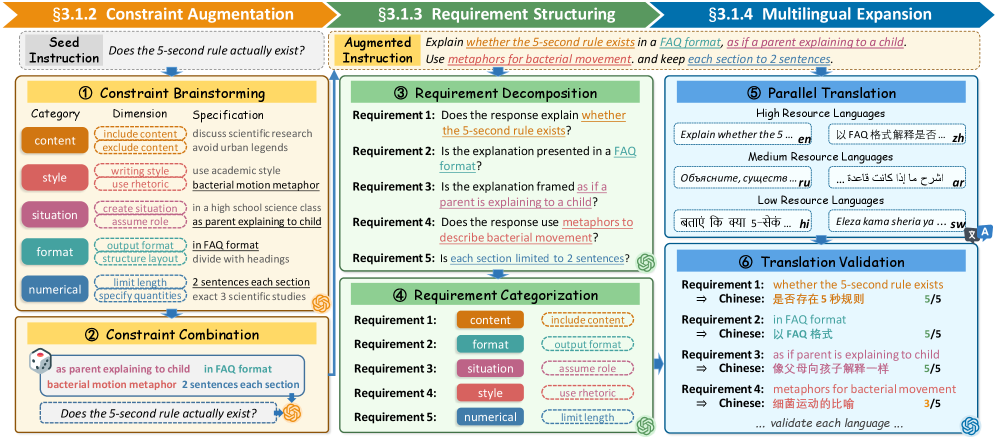
问题定义:现有的大语言模型在多语言环境下的指令遵循能力评估不够完善,缺乏对不同类型约束的细致分析,难以准确衡量模型在不同语言和文化背景下的表现。现有的评估方法可能存在翻译质量问题,导致评估结果不准确。
核心思路:XIFBench的核心思路是构建一个包含多种约束类型(内容、风格、情境、格式和数值)和多种语言的综合性基准,并采用一系列方法来保证评估的可靠性和一致性。通过引入文化可访问性标注、约束级别翻译验证和基于需求的评估,确保评估结果能够反映模型在不同语言和文化背景下的真实性能。
技术框架:XIFBench的整体框架包括以下几个主要组成部分:1) 指令集构建:设计包含多种约束类型和不同复杂度的指令;2) 多语言翻译:将指令翻译成六种不同资源水平的语言;3) 文化可访问性标注:对指令进行文化可访问性标注,以确保指令在不同文化背景下的适用性;4) 约束级别翻译验证:验证翻译质量,确保翻译后的指令能够准确表达原始指令的含义;5) 基于需求的评估:使用英语需求作为跨语言语义锚点,评估模型在不同语言下的指令遵循能力。
关键创新:XIFBench的关键创新在于其综合性的约束设计、文化可访问性标注、约束级别翻译验证和基于需求的评估方法。这些创新使得XIFBench能够更全面、更准确地评估大语言模型在多语言环境下的指令遵循能力。与现有方法相比,XIFBench能够提供更细粒度的性能分析,并揭示影响模型性能的关键因素。
关键设计:XIFBench的关键设计包括:1) 五种约束类型(内容、风格、情境、格式和数值)的设计,涵盖了指令遵循的各个方面;2) 文化可访问性标注的细粒度标准,确保指令在不同文化背景下的适用性;3) 约束级别翻译验证的流程,保证翻译质量;4) 基于需求的评估方法,使用英语需求作为跨语言语义锚点,确保评估的一致性。
🖼️ 关键图片

📊 实验亮点
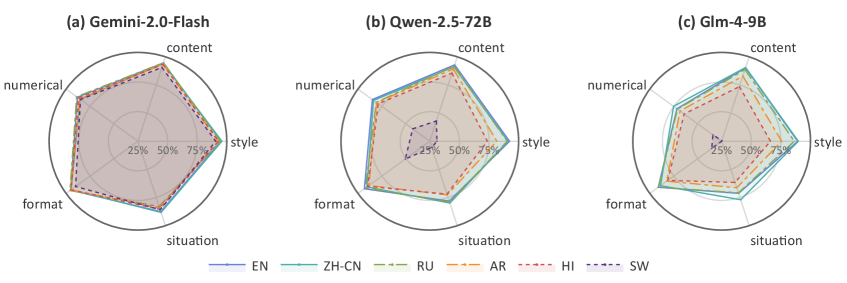
实验结果表明,不同资源水平的语言对LLMs的指令遵循能力有显著影响。例如,低资源语言的性能明显低于高资源语言。此外,不同约束类别对模型性能的影响也不同,例如,数值约束通常比内容约束更具挑战性。XIFBench还揭示了指令复杂性和文化特殊性对多语言指令遵循的影响。
🎯 应用场景
XIFBench的研究成果可应用于评估和改进大语言模型在多语言环境下的性能,提升其在跨语言任务中的表现。该基准可以帮助开发者更好地了解模型的优势和不足,从而有针对性地进行优化。此外,XIFBench还可以促进多语言自然语言处理技术的发展,推动全球范围内的信息交流和文化理解。
📄 摘要(原文)
Large Language Models (LLMs) have demonstrated remarkable instruction-following capabilities across various applications. However, their performance in multilingual settings lacks systematic investigation, with existing evaluations lacking fine-grained constraint analysis across diverse linguistic contexts. We introduce XIFBench, a comprehensive constraint-based benchmark for evaluating multilingual instruction-following abilities of LLMs, comprising 558 instructions with 0-5 additional constraints across five categories (Content, Style, Situation, Format, and Numerical) in six languages spanning different resource levels. To support reliable and consistent cross-lingual evaluation, we implement three methodological innovations: cultural accessibility annotation, constraint-level translation validation, and requirement-based evaluation using English requirements as semantic anchors across languages. Extensive experiments with various LLMs not only quantify performance disparities across resource levels but also provide detailed insights into how language resources, constraint categories, instruction complexity, and cultural specificity influence multilingual instruction-following. Our code and data are available at https://github.com/zhenyuli801/XIFBench.