Language Models Fail to Introspect About Their Knowledge of Language
作者: Siyuan Song, Jennifer Hu, Kyle Mahowald
分类: cs.CL, cs.AI
发布日期: 2025-03-10 (更新: 2025-09-23)
备注: 23 pages, 10 figures, COLM 2025 camera ready
💡 一句话要点
研究表明大型语言模型无法有效内省其语言知识
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 内省能力 语言知识 字符串概率 元语言提示
📋 核心要点
- 现有方法难以评估LLM是否真正理解语言,而不仅仅是模式匹配。
- 论文提出一种新的内省度量标准,通过比较模型提示响应和字符串概率来评估内省能力。
- 实验结果表明,LLM在语法知识和单词预测方面都缺乏有效的内省能力。
📝 摘要(中文)
最近的研究关注大型语言模型(LLM)是否能够内省其内部状态。这种能力将使LLM更具可解释性,并验证语言学中标准内省方法在评估模型语法知识方面的应用(例如,询问“这个句子是否符合语法?”)。我们系统地研究了21个开源LLM中涌现的内省能力,涉及语法知识和单词预测两个领域,这两个领域的模型内部语言知识都可以通过直接测量字符串概率在理论上得到证实。然后,我们评估模型对元语言提示的响应是否忠实地反映了其内部知识。我们提出了一种新的内省度量标准:模型提示响应预测自身字符串概率的程度,超出具有几乎相同内部知识的另一个模型的预测。虽然元语言提示和概率比较都带来了很高的任务准确性,但我们没有发现LLM具有特权的“自我访问”的证据。通过使用通用任务、控制模型相似性以及评估范围广泛的开源模型,我们表明LLM无法进行内省,并为提示响应不应与模型的语言泛化混淆的论点添加了新的证据。
🔬 方法详解
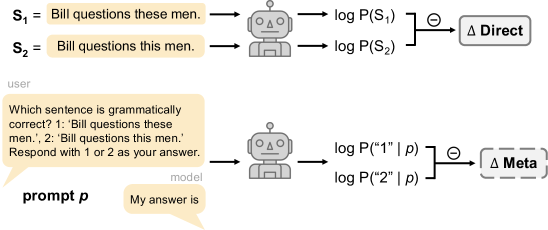
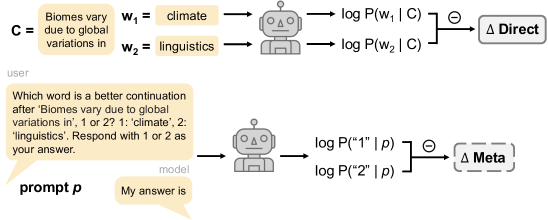
问题定义:论文旨在解决大型语言模型(LLM)是否具备内省能力的问题,即模型能否准确地访问并报告其自身的语言知识。现有方法,例如直接询问模型语法判断,可能无法区分模型真正的语言理解和简单的模式匹配。因此,需要一种更可靠的方法来评估LLM的内省能力。
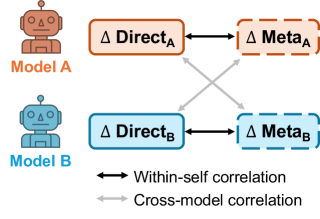
核心思路:核心思路是通过比较模型对元语言提示的响应和其自身生成的字符串概率,来判断模型是否真正了解其内部的语言知识。如果模型能够准确地内省,那么其对元语言提示的响应应该能够有效地预测其自身的字符串概率。同时,为了排除模型架构和训练数据的影响,论文还引入了一个具有相似内部知识的对比模型。
技术框架:整体框架包括以下几个步骤:1) 选择一系列开源LLM;2) 设计语法知识和单词预测两个领域的评估任务;3) 使用元语言提示来引导模型生成响应;4) 计算模型生成的字符串的概率;5) 提出新的内省度量标准,即模型提示响应预测自身字符串概率的程度,并与对比模型进行比较。
关键创新:最重要的创新点在于提出了一种新的内省度量标准,该标准能够更准确地评估LLM的内省能力。该度量标准通过比较模型提示响应和字符串概率之间的关系,以及与对比模型的比较,有效地排除了模型架构和训练数据的影响,从而更可靠地判断模型是否真正了解其内部的语言知识。
关键设计:论文的关键设计包括:1) 选择了21个开源LLM,涵盖了不同的模型架构和训练数据;2) 设计了语法知识和单词预测两个领域的评估任务,以全面评估模型的内省能力;3) 使用了元语言提示来引导模型生成响应,例如询问模型某个句子是否符合语法;4) 使用了字符串概率来衡量模型对语言的理解程度;5) 提出了新的内省度量标准,并与对比模型进行比较,以排除模型架构和训练数据的影响。
🖼️ 关键图片
📊 实验亮点
实验结果表明,尽管LLM在语法判断和单词预测任务上表现出较高的准确率,但其对元语言提示的响应并不能有效地预测其自身的字符串概率。与具有相似内部知识的对比模型相比,LLM并没有表现出更强的内省能力。这表明LLM可能缺乏真正的语言理解能力,而更多地依赖于模式匹配。
🎯 应用场景
该研究成果可应用于评估和改进大型语言模型的语言理解能力,帮助开发者更好地理解模型的内部机制,并开发更可靠、更可信的AI系统。此外,该研究也对语言学研究具有重要意义,有助于理解人类语言认知和模型学习之间的差异。
📄 摘要(原文)
There has been recent interest in whether large language models (LLMs) can introspect about their own internal states. Such abilities would make LLMs more interpretable, and also validate the use of standard introspective methods in linguistics to evaluate grammatical knowledge in models (e.g., asking "Is this sentence grammatical?"). We systematically investigate emergent introspection across 21 open-source LLMs, in two domains where introspection is of theoretical interest: grammatical knowledge and word prediction. Crucially, in both domains, a model's internal linguistic knowledge can be theoretically grounded in direct measurements of string probability. We then evaluate whether models' responses to metalinguistic prompts faithfully reflect their internal knowledge. We propose a new measure of introspection: the degree to which a model's prompted responses predict its own string probabilities, beyond what would be predicted by another model with nearly identical internal knowledge. While both metalinguistic prompting and probability comparisons lead to high task accuracy, we do not find evidence that LLMs have privileged "self-access". By using general tasks, controlling for model similarity, and evaluating a wide range of open-source models, we show that LLMs cannot introspect, and add new evidence to the argument that prompted responses should not be conflated with models' linguistic generalizations.