Revisiting Noise in Natural Language Processing for Computational Social Science
作者: Nadav Borenstein
分类: cs.CL
发布日期: 2025-03-10
备注: PhD thesis. Under the supervision of Prof. Isabelle Augenstein
💡 一句话要点
重新审视自然语言处理中的噪声,以促进计算社会科学研究。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
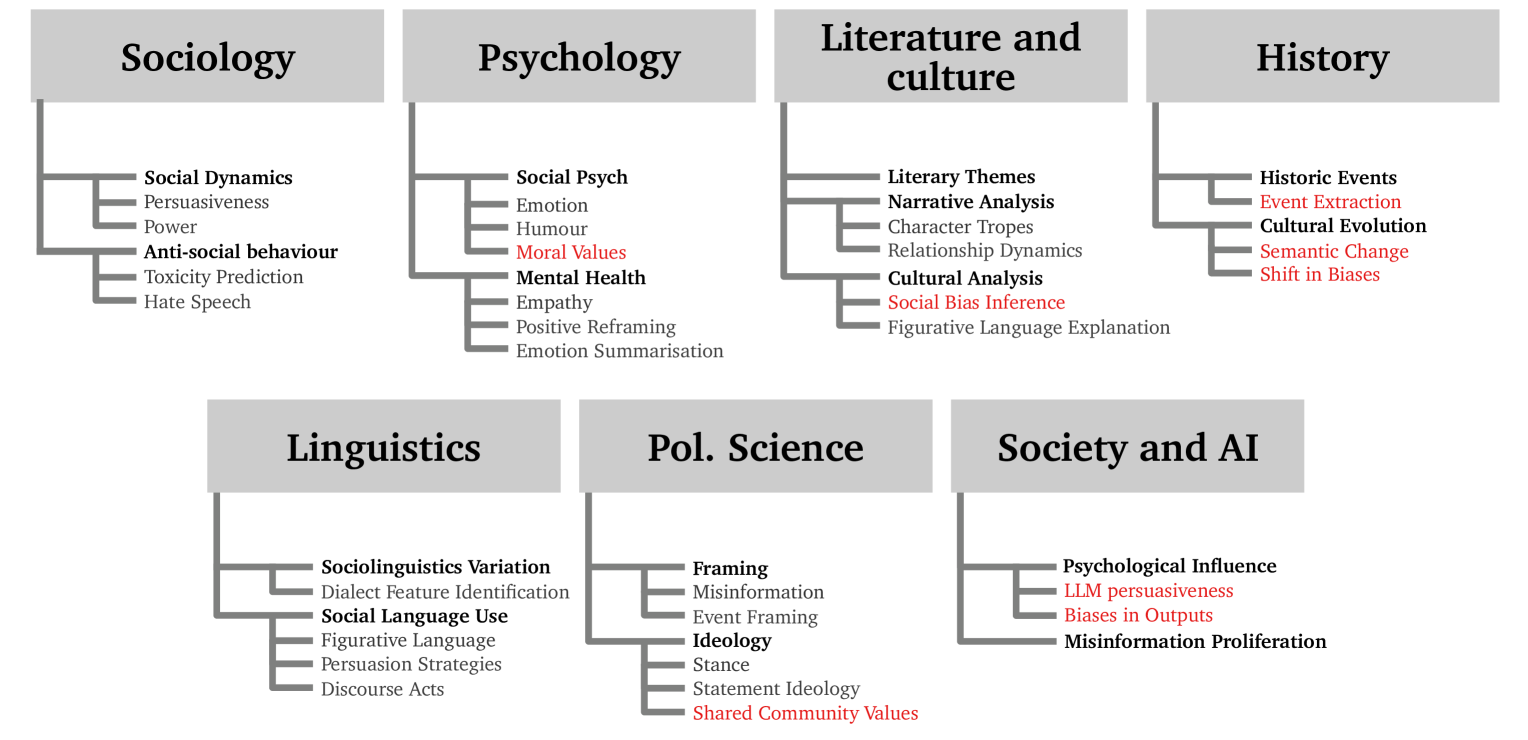
关键词: 计算社会科学 自然语言处理 文本噪声 数据质量 案例研究
📋 核心要点
- 计算社会科学面临文本数据中普遍存在的噪声问题,传统方法通常将其视为有害因素。
- 该研究的核心思想是,某些类型的噪声实际上蕴含着有价值的信息,例如文化差异或个人风格。
- 通过案例研究,论文展示了不同类型的噪声需要不同的处理策略,并强调了细致分析的重要性。
📝 摘要(中文)
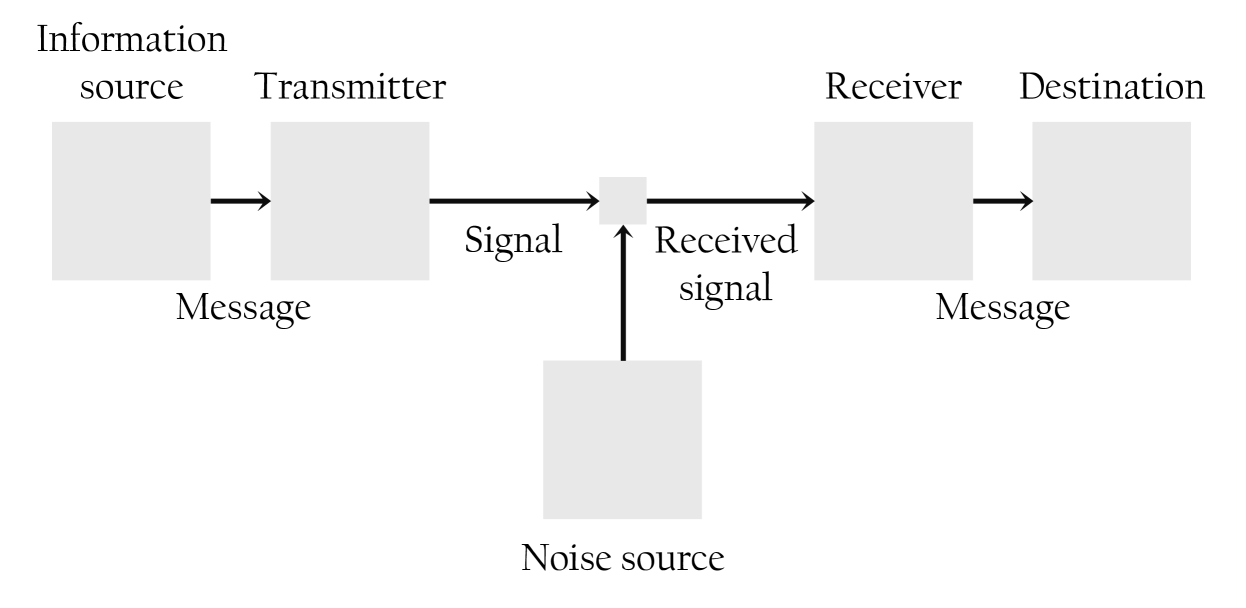
计算社会科学(CSS)是一个新兴领域,其发展得益于研究人员可以前所未有地获取人类生成的内容。然而,由于其理论和数据集的性质,包括高度主观的任务和复杂的非结构化文本语料库,该领域面临着独特的挑战。其中,噪声的普遍存在是一个研究较少的课题。本论文旨在通过一系列相互关联的案例研究来解决文献中的这一空白,这些案例研究考察了CSS中噪声的不同表现形式,包括历史记录OCR处理后的字符级错误、古老的语言、主观和模糊任务的注释不一致,甚至包括大型语言模型在内容生成过程中引入的噪声和偏差。本论文挑战了CSS中噪声本质上有害或无用的传统观念。相反,它认为某些形式的噪声可以编码有意义的信息,这些信息对于推进CSS研究是无价的,例如个人独特的交流风格或数据集和任务的文化依赖性。此外,本论文强调了处理噪声时细微差别的重要性,以及CSS研究人员在遇到噪声时必须考虑的因素,表明不同类型的噪声需要不同的策略。
🔬 方法详解
问题定义:计算社会科学领域依赖大量文本数据,但这些数据往往包含各种噪声,如OCR错误、古语、标注不一致等。传统方法通常简单地将这些噪声视为干扰,试图消除它们,而忽略了噪声可能携带的潜在信息。现有方法缺乏对不同类型噪声的细致区分和针对性处理策略。
核心思路:本研究的核心在于转变对噪声的固有观念,认为某些噪声并非完全有害,而是可能蕴含着有价值的信息。通过分析噪声的来源和特性,可以提取出与社会文化、个体特征等相关的知识。因此,需要针对不同类型的噪声,采取不同的分析和利用策略,而非一概而论地消除。
技术框架:本研究采用案例研究的方法,针对不同类型的噪声进行分析。具体流程包括:1) 识别特定CSS任务中存在的噪声类型;2) 分析噪声的来源和特征,例如OCR错误的模式、古语的语法结构、标注不一致的原因等;3) 设计针对性的分析方法,例如利用统计模型识别OCR错误,利用语言模型分析古语的语义,利用一致性分析方法评估标注质量;4) 提取噪声中蕴含的信息,并将其应用于CSS研究,例如分析历史文献中的语言变迁,识别不同群体的交流风格。
关键创新:本研究的创新之处在于:1) 提出了噪声并非完全有害的观点,强调了噪声中可能蕴含的信息价值;2) 强调了对不同类型噪声进行细致区分和针对性处理的重要性;3) 将噪声分析与具体的CSS任务相结合,展示了噪声分析在实际应用中的价值。
关键设计:由于本研究采用案例研究方法,因此没有统一的技术细节。针对不同的噪声类型,采用了不同的分析方法。例如,对于OCR错误,可以采用基于统计语言模型的纠错方法;对于古语,可以采用基于Transformer的语言模型进行语义理解;对于标注不一致,可以采用基于一致性度量的质量评估方法。关键在于根据噪声的特性选择合适的分析工具和方法。
🖼️ 关键图片

📊 实验亮点
该研究通过案例分析,展示了不同类型的噪声在CSS研究中的潜在价值。例如,通过分析历史文献中的OCR错误,可以推断当时的印刷技术水平;通过分析社交媒体中的拼写错误,可以识别用户的地域来源。这些案例表明,噪声分析可以为CSS研究提供新的数据来源和分析维度。
🎯 应用场景
该研究成果可应用于历史文献分析、社交媒体舆情分析、用户行为模式挖掘等领域。通过深入理解和有效利用文本数据中的噪声,可以更准确地把握社会动态、文化变迁和个体特征,为社会科学研究提供新的视角和方法。未来,该研究思路可推广到其他类型的数据分析中,例如图像、音频等。
📄 摘要(原文)
Computational Social Science (CSS) is an emerging field driven by the unprecedented availability of human-generated content for researchers. This field, however, presents a unique set of challenges due to the nature of the theories and datasets it explores, including highly subjective tasks and complex, unstructured textual corpora. Among these challenges, one of the less well-studied topics is the pervasive presence of noise. This thesis aims to address this gap in the literature by presenting a series of interconnected case studies that examine different manifestations of noise in CSS. These include character-level errors following the OCR processing of historical records, archaic language, inconsistencies in annotations for subjective and ambiguous tasks, and even noise and biases introduced by large language models during content generation. This thesis challenges the conventional notion that noise in CSS is inherently harmful or useless. Rather, it argues that certain forms of noise can encode meaningful information that is invaluable for advancing CSS research, such as the unique communication styles of individuals or the culture-dependent nature of datasets and tasks. Further, this thesis highlights the importance of nuance in dealing with noise and the considerations CSS researchers must address when encountering it, demonstrating that different types of noise require distinct strategies.