MRCEval: A Comprehensive, Challenging and Accessible Machine Reading Comprehension Benchmark
作者: Shengkun Ma, Hao Peng, Lei Hou, Juanzi Li
分类: cs.CL, cs.AI
发布日期: 2025-03-10
备注: Under review
💡 一句话要点
提出MRCEval,一个全面、有挑战性且易于访问的机器阅读理解评测基准。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 机器阅读理解 自然语言理解 评测基准 大型语言模型 阅读理解能力
📋 核心要点
- 现有MRC数据集侧重于阅读理解的特定方面,缺乏对模型综合能力的全面评估。
- MRCEval利用大型语言模型生成高质量多项选择题,并作为评判器,构建了一个更全面的评估基准。
- 实验结果表明,即使是最先进的LLM在MRCEval基准上仍然面临挑战,表明阅读理解仍有提升空间。
📝 摘要(中文)
机器阅读理解(MRC)是评估自然语言理解能力的关键任务。现有的MRC数据集主要评估阅读理解(RC)的特定方面,缺乏一个全面的MRC基准。为了填补这一空白,我们首先引入了一种新的分类法,对RC所需的核心能力进行分类。基于此,我们构建了MRCEval,一个利用先进的大型语言模型(LLM)作为样本生成器和选择判断器的MRC基准。MRCEval是一个全面、有挑战性且易于访问的基准,旨在彻底评估LLM的RC能力,涵盖13种不同的RC技能,总共包含2.1K个高质量的多项选择题。我们对28个广泛使用的开源和专有模型进行了广泛的评估,强调即使在LLM时代,MRC仍然面临着巨大的挑战。
🔬 方法详解
问题定义:现有的机器阅读理解(MRC)数据集通常只关注阅读理解的某些特定方面,例如实体识别、关系抽取等,缺乏一个能够全面评估模型阅读理解能力的基准。这使得我们难以准确评估模型在各种阅读理解任务上的表现,也阻碍了MRC领域的发展。
核心思路:MRCEval的核心思路是构建一个覆盖多种阅读理解技能的综合性评测基准。通过设计一个包含多种题型和难度级别的测试集,并利用大型语言模型(LLM)辅助生成和筛选高质量的测试样本,从而更全面地评估模型的阅读理解能力。
技术框架:MRCEval的构建主要包含以下几个阶段: 1. 能力分类:定义了13种不同的阅读理解技能,例如常识推理、文本蕴含、指代消解等。 2. 样本生成:利用LLM生成多项选择题,每个问题都针对特定的阅读理解技能。 3. 样本筛选:利用LLM作为评判器,对生成的样本进行筛选,确保样本的质量和难度。 4. 基准测试:使用MRCEval评估各种开源和专有模型的阅读理解能力。
关键创新:MRCEval的关键创新在于其综合性和利用LLM辅助构建数据集的方法。与以往的MRC数据集相比,MRCEval覆盖了更广泛的阅读理解技能,能够更全面地评估模型的阅读理解能力。此外,利用LLM生成和筛选样本可以大大提高数据集的构建效率和质量。
关键设计:MRCEval包含2.1K个多项选择题,涵盖13种不同的阅读理解技能。每个问题都包含一个上下文段落和一个问题,以及四个候选答案。数据集的难度经过精心设计,既包含简单的问题,也包含需要复杂推理才能解决的问题。在利用LLM生成样本时,使用了多种prompting技巧来控制生成样本的质量和多样性。在利用LLM筛选样本时,使用了多种指标来评估样本的质量,例如问题的清晰度、答案的正确性等。
🖼️ 关键图片
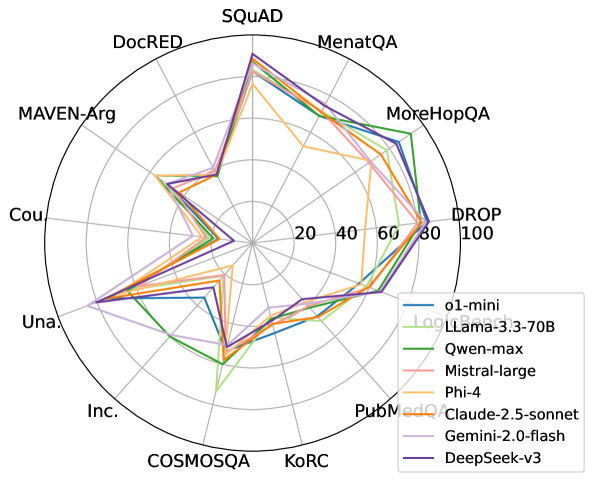
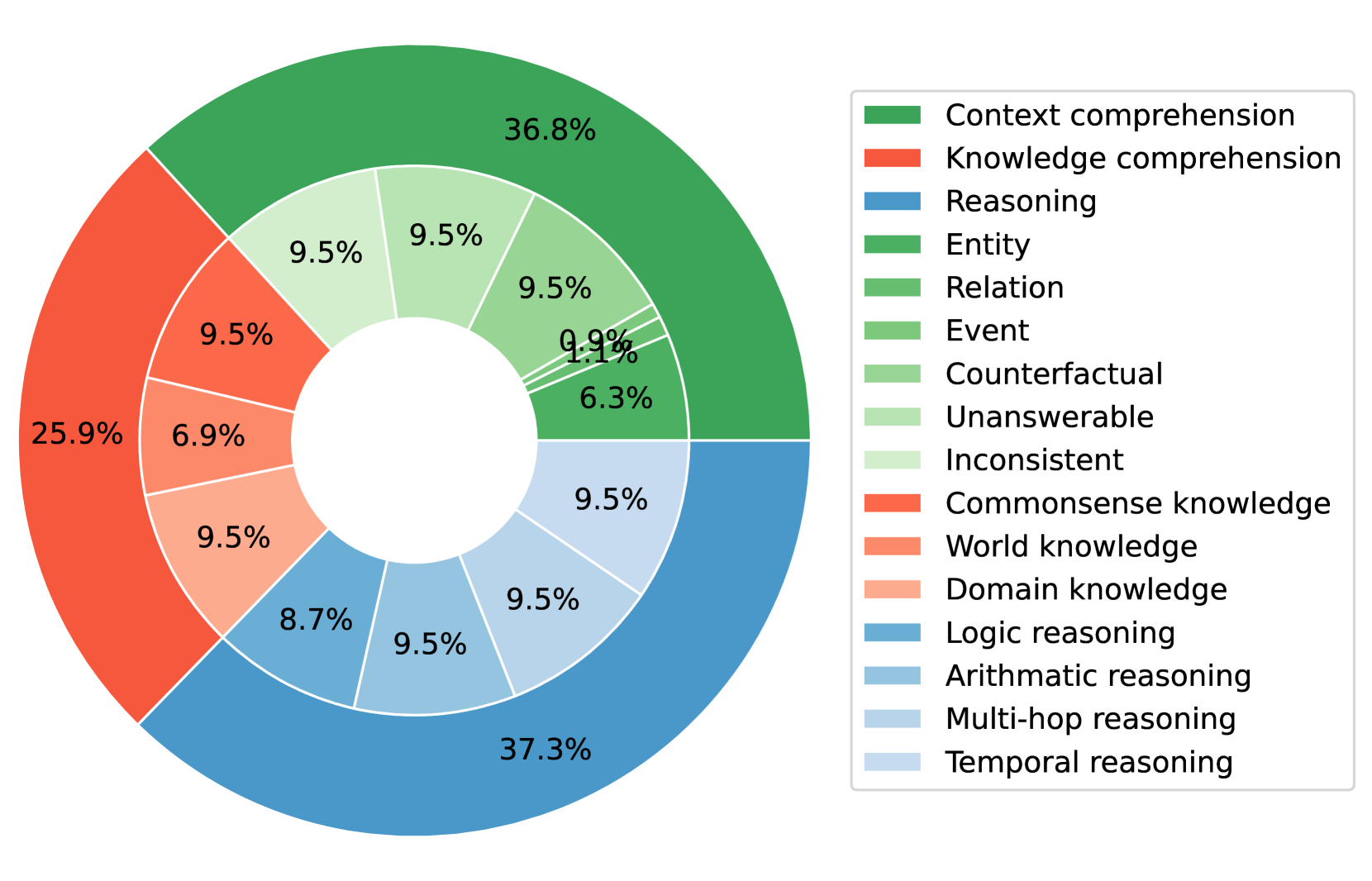
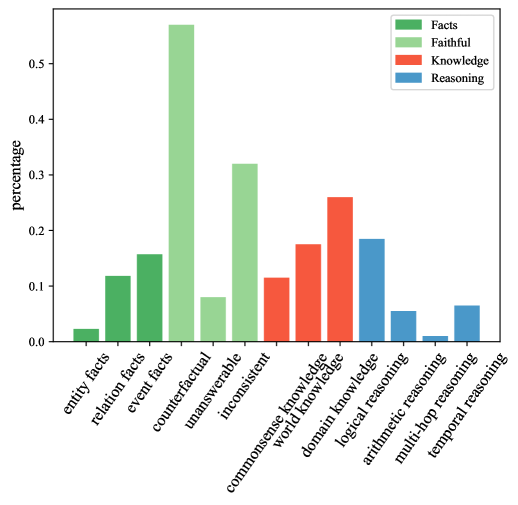
📊 实验亮点
在MRCEval基准上,对28个广泛使用的开源和专有模型进行了评估。实验结果表明,即使是最先进的LLM在MRCEval上仍然面临挑战,平均准确率低于80%。这表明,即使在LLM时代,机器阅读理解仍然是一个具有挑战性的研究领域,仍有很大的提升空间。部分模型在特定类型的阅读理解技能上表现较好,但在其他技能上表现较差,表明模型在不同技能上的泛化能力存在差异。
🎯 应用场景
MRCEval可用于评估和比较不同机器阅读理解模型的性能,推动MRC技术的发展。该基准能够帮助研究人员更好地了解模型的优势和不足,从而开发出更强大的阅读理解模型。此外,MRCEval还可以应用于教育领域,用于评估学生的阅读理解能力,并为个性化学习提供支持。
📄 摘要(原文)
Machine Reading Comprehension (MRC) is an essential task in evaluating natural language understanding. Existing MRC datasets primarily assess specific aspects of reading comprehension (RC), lacking a comprehensive MRC benchmark. To fill this gap, we first introduce a novel taxonomy that categorizes the key capabilities required for RC. Based on this taxonomy, we construct MRCEval, an MRC benchmark that leverages advanced Large Language Models (LLMs) as both sample generators and selection judges. MRCEval is a comprehensive, challenging and accessible benchmark designed to assess the RC capabilities of LLMs thoroughly, covering 13 distinct RC skills with a total of 2.1K high-quality multi-choice questions. We perform an extensive evaluation of 28 widely used open-source and proprietary models, highlighting that MRC continues to present significant challenges even in the era of LLMs.