Delusions of Large Language Models
作者: Hongshen Xu, Zixv yang, Zichen Zhu, Kunyao Lan, Zihan Wang, Mengyue Wu, Ziwei Ji, Lu Chen, Pascale Fung, Kai Yu
分类: cs.CL, cs.AI
发布日期: 2025-03-09
💡 一句话要点
揭示大语言模型幻觉新形态:高置信度幻觉(Delusion)及其缓解策略
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 幻觉 Delusion 高置信度 检索增强生成
📋 核心要点
- 现有大语言模型存在幻觉问题,但高置信度的错误输出(Delusion)更难检测和纠正,严重影响模型可靠性。
- 论文核心在于识别并分析LLM的Delusion现象,探究其成因,并提出相应的缓解策略,提升模型可靠性。
- 实验表明Delusion普遍存在且难以通过微调或自我反思消除,检索增强生成和多智能体辩论可有效缓解Delusion。
📝 摘要(中文)
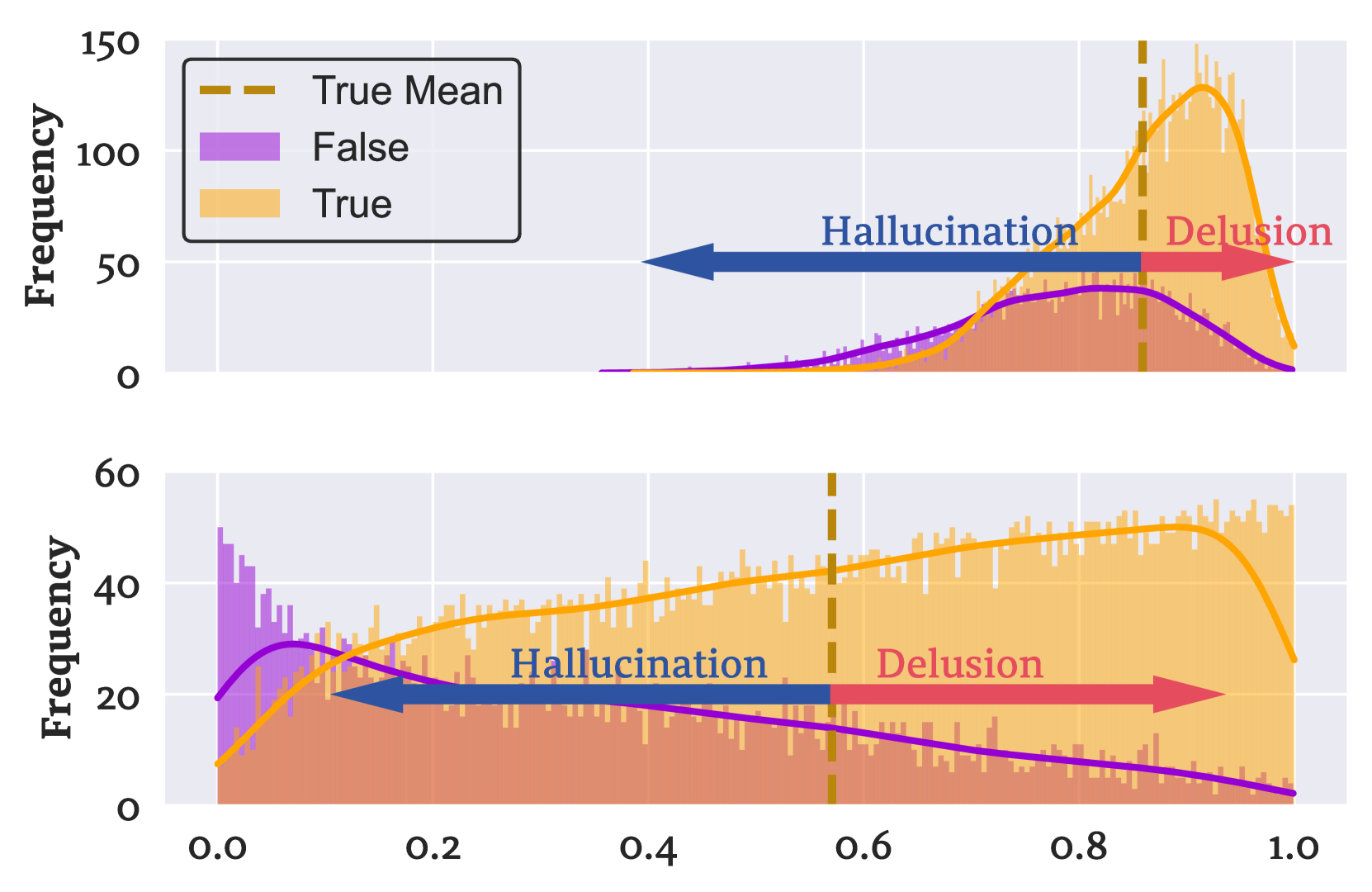
大型语言模型(LLM)经常生成在事实上不正确但看似合理的输出,这种现象被称为幻觉。本文识别出一种更隐蔽的现象,即LLM妄想(delusion),定义为高置信度幻觉,即置信度异常高的不正确输出,这使得它们更难被检测和缓解。与普通幻觉不同,妄想在低不确定性的情况下持续存在,对模型的可靠性构成重大挑战。通过对不同模型系列和大小在多个问答任务上的实证分析,我们表明妄想是普遍存在的,并且与幻觉不同。LLM在妄想情况下表现出较低的诚实度,并且更难通过微调或自我反思来纠正。我们将妄想的形成与训练动态和数据集噪声联系起来,并探索诸如检索增强生成和多智能体辩论等缓解策略来减轻妄想。通过系统地研究LLM妄想的性质、普遍性和缓解方法,我们的研究深入了解了这种现象的根本原因,并概述了改进模型可靠性的未来方向。
🔬 方法详解
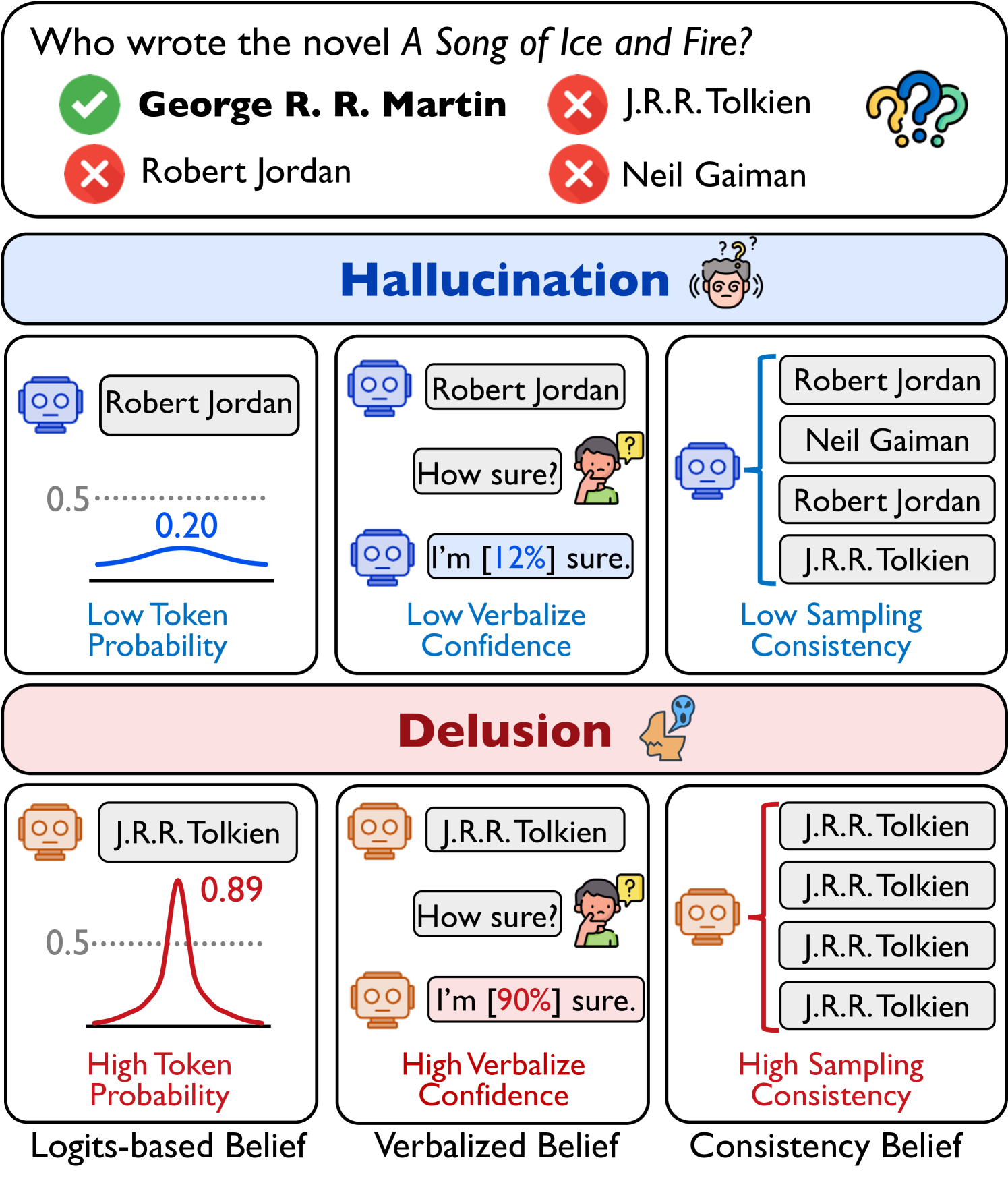
问题定义:论文旨在解决大语言模型中一种更隐蔽的幻觉现象,即“Delusion”。与普通的幻觉相比,Delusion指的是模型以极高的置信度输出错误信息,使得这种错误更难以被发现和纠正。现有方法难以有效识别和缓解这种高置信度的错误,严重影响了LLM在实际应用中的可靠性。
核心思路:论文的核心思路是深入分析Delusion的成因,将其与训练数据和模型训练过程联系起来。通过实验验证Delusion的普遍性和顽固性,并探索不同的缓解策略,例如检索增强生成和多智能体辩论,以降低模型产生Delusion的可能性。
技术框架:论文的研究框架主要包括以下几个阶段:1) 定义并区分Delusion和普通幻觉;2) 通过实验评估不同LLM中Delusion的普遍性;3) 分析Delusion与模型训练动态和数据集噪声之间的关系;4) 探索缓解Delusion的策略,包括检索增强生成和多智能体辩论。
关键创新:论文最重要的创新在于识别并定义了LLM的Delusion现象,并将其与模型的置信度联系起来。与以往关注普通幻觉的研究不同,本文关注的是高置信度的错误输出,这使得问题更加复杂和具有挑战性。此外,论文还探索了Delusion的成因和缓解策略,为未来的研究提供了新的方向。
关键设计:论文的关键设计包括:1) 使用多种问答任务和数据集来评估Delusion的普遍性;2) 设计实验来分析Delusion与模型训练动态和数据集噪声之间的关系;3) 采用检索增强生成(RAG)来提供更准确的上下文信息,从而减少Delusion的产生;4) 使用多智能体辩论来促进不同观点之间的交流和验证,从而提高模型输出的可靠性。
🖼️ 关键图片
📊 实验亮点
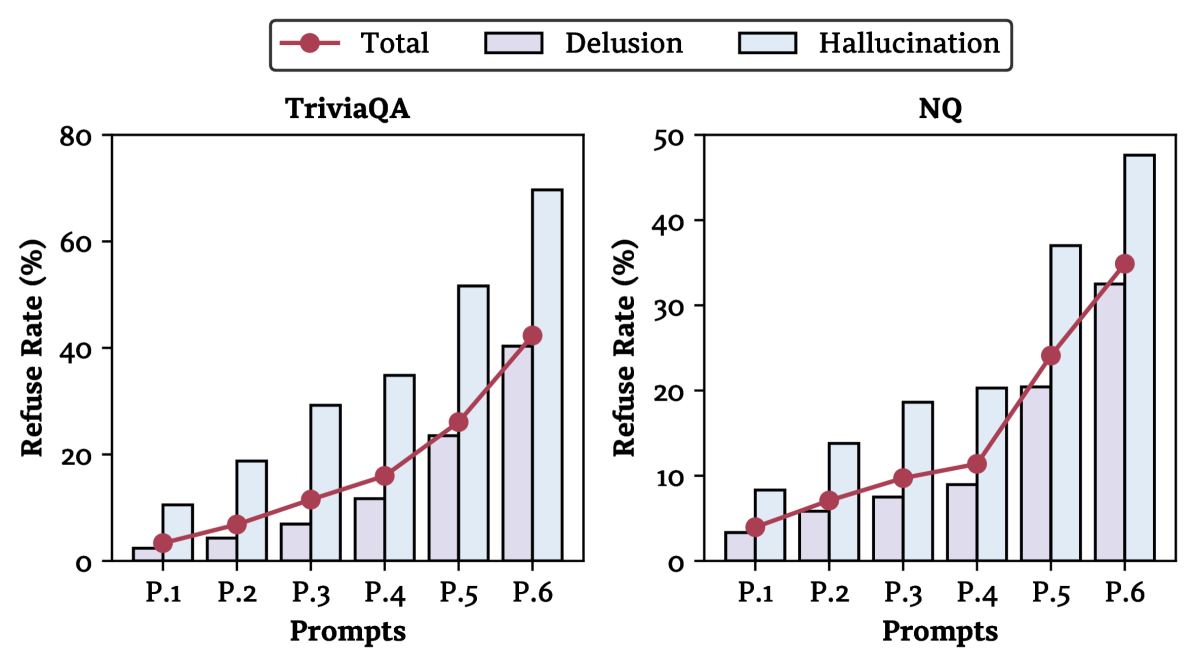
实验结果表明,Delusion现象在不同模型系列和大小的LLM中普遍存在,且难以通过微调或自我反思来消除。检索增强生成(RAG)和多智能体辩论等方法可以有效缓解Delusion,显著提升模型的可靠性。例如,RAG方法通过提供更准确的上下文信息,降低了模型产生错误信息的概率。
🎯 应用场景
该研究成果可应用于提升大语言模型在各个领域的可靠性,例如智能客服、医疗诊断、金融分析等。通过降低模型产生高置信度错误信息的风险,可以提高用户对模型的信任度,并减少因错误信息造成的损失。未来,该研究可以推动开发更安全、更可靠的大语言模型。
📄 摘要(原文)
Large Language Models often generate factually incorrect but plausible outputs, known as hallucinations. We identify a more insidious phenomenon, LLM delusion, defined as high belief hallucinations, incorrect outputs with abnormally high confidence, making them harder to detect and mitigate. Unlike ordinary hallucinations, delusions persist with low uncertainty, posing significant challenges to model reliability. Through empirical analysis across different model families and sizes on several Question Answering tasks, we show that delusions are prevalent and distinct from hallucinations. LLMs exhibit lower honesty with delusions, which are harder to override via finetuning or self reflection. We link delusion formation with training dynamics and dataset noise and explore mitigation strategies such as retrieval augmented generation and multi agent debating to mitigate delusions. By systematically investigating the nature, prevalence, and mitigation of LLM delusions, our study provides insights into the underlying causes of this phenomenon and outlines future directions for improving model reliability.