InftyThink: Breaking the Length Limits of Long-Context Reasoning in Large Language Models
作者: Yuchen Yan, Yongliang Shen, Yang Liu, Jin Jiang, Mengdi Zhang, Jian Shao, Yueting Zhuang
分类: cs.CL, cs.AI
发布日期: 2025-03-09 (更新: 2025-09-26)
备注: Project Page: https://zju-real.github.io/InftyThink Code: https://github.com/ZJU-REAL/InftyThink Dataset: https://huggingface.co/datasets/ZJU-REAL/InftyThink
💡 一句话要点
InftyThink:突破大语言模型长文本推理长度限制,实现无限深度推理
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 长文本推理 大语言模型 迭代推理 中间总结 计算复杂度 数学推理 模型优化
📋 核心要点
- 现有长文本推理方法面临计算量随文本长度平方级增长的瓶颈,且超出预训练长度后性能显著下降。
- InftyThink将长文本推理分解为迭代的短推理片段,辅以中间总结,实现无限推理深度和有界计算成本。
- 实验表明,InftyThink在多个数学推理数据集上提升了性能,并降低了计算成本,无需修改模型架构。
📝 摘要(中文)
大型语言模型在复杂推理任务中表现出色,但当前的长文本推理范式面临计算量随序列长度二次方增长、推理受限于最大上下文边界、以及超出预训练上下文窗口后性能下降等关键限制。现有方法主要压缩推理链,未能解决根本的扩展性问题。为此,我们提出了InftyThink,一种将整体推理转化为迭代过程并进行中间总结的范式。通过将短推理片段与简洁的进度总结交错,我们的方法能够在保持有界计算成本的同时实现无限的推理深度。这产生了一种锯齿状的内存模式,与传统方法相比,显著降低了计算复杂度。此外,我们开发了一种将长文本推理数据集重构为迭代格式的方法,将OpenR1-Math转换为333K个训练实例。在多个模型架构上的实验表明,我们的方法降低了计算成本,同时提高了性能,其中Qwen2.5-Math-7B在MATH500、AIME24和GPQA_diamond基准测试中表现出3-13%的改进。我们的工作挑战了推理深度和计算效率之间的权衡假设,为复杂的推理提供了一种更具可扩展性的方法,而无需修改模型架构。
🔬 方法详解
问题定义:现有大语言模型在长文本推理中面临计算复杂度高、推理长度受限以及超出预训练上下文长度后性能下降的问题。传统的长文本推理方法,例如直接处理整个长文本或压缩推理链,无法从根本上解决计算量随序列长度二次方增长的问题,限制了模型处理更复杂问题的能力。
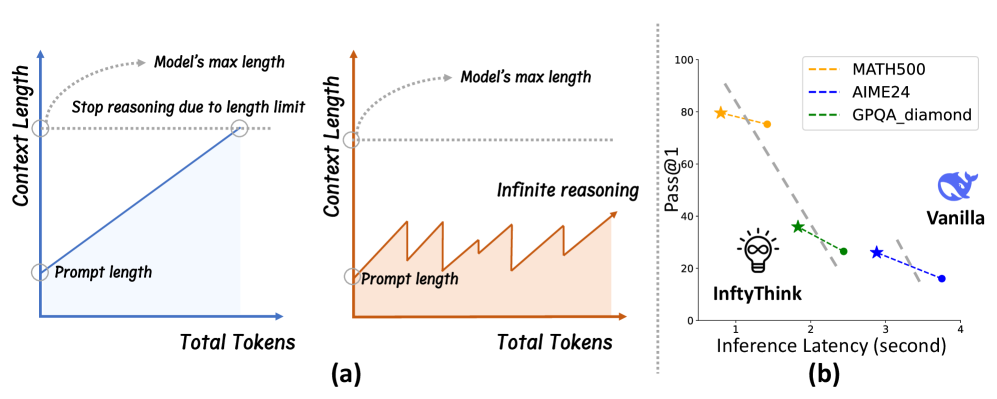
核心思路:InftyThink的核心思路是将原本一次性的长文本推理过程分解为多个迭代的短文本推理步骤,并在每个步骤后进行中间总结。通过这种方式,模型只需要在每个迭代步骤中处理有限长度的文本,从而将计算复杂度降低到线性级别。同时,中间总结可以帮助模型记住之前的推理过程,从而实现无限的推理深度。
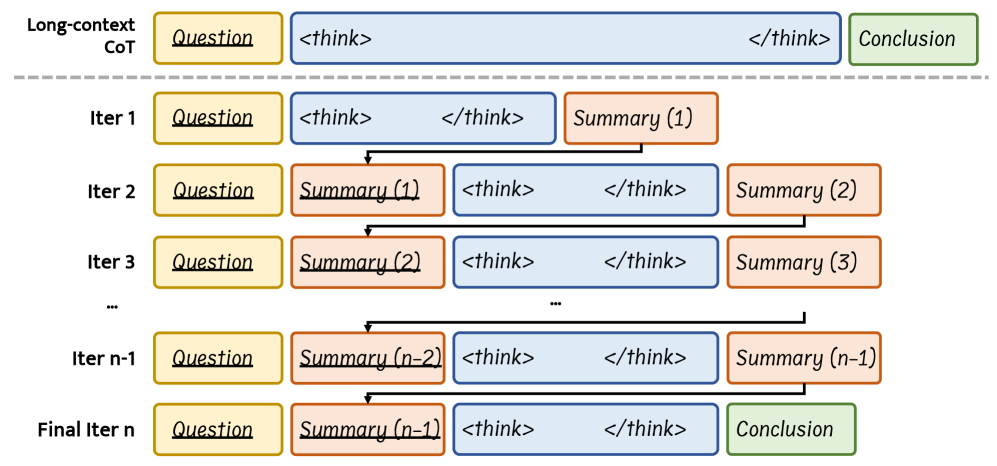
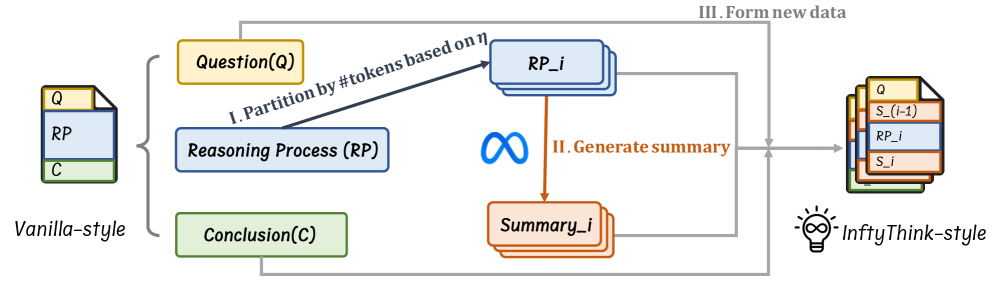
技术框架:InftyThink的整体框架包含以下几个主要模块:1) 推理分割:将原始的长文本推理问题分割成一系列短文本推理子问题。2) 迭代推理:使用大语言模型对每个短文本推理子问题进行推理。3) 中间总结:在每个推理步骤后,对当前的推理结果进行总结,并将总结信息传递到下一个推理步骤。4) 结果整合:将所有推理步骤的结果整合起来,得到最终的推理结果。这种迭代的推理过程形成了一种锯齿状的内存模式,其中内存使用量在每个推理步骤中都会下降,从而降低了计算复杂度。
关键创新:InftyThink的关键创新在于将长文本推理问题分解为迭代的短文本推理子问题,并通过中间总结来保持推理的连贯性。与传统的长文本推理方法相比,InftyThink能够显著降低计算复杂度,并实现无限的推理深度。此外,InftyThink不需要修改模型架构,可以很容易地应用于现有的各种大语言模型。
关键设计:InftyThink的关键设计包括:1) 推理分割策略:如何将原始的长文本推理问题分割成合适的短文本推理子问题。2) 中间总结方法:如何有效地总结当前的推理结果,并将总结信息传递到下一个推理步骤。3) 迭代次数:需要进行多少次迭代才能得到最终的推理结果。论文中提出了一种将OpenR1-Math数据集转化为迭代格式的方法,并使用Qwen2.5-Math-7B模型进行了实验。具体的参数设置和损失函数等技术细节在论文中没有详细描述,属于未知信息。
🖼️ 关键图片
📊 实验亮点
实验结果表明,InftyThink在MATH500、AIME24和GPQA_diamond等数学推理基准测试中,使用Qwen2.5-Math-7B模型取得了3-13%的性能提升。同时,该方法显著降低了计算成本,验证了其在长文本推理方面的有效性和优越性。这些结果表明,InftyThink挑战了推理深度和计算效率之间的权衡假设,为复杂的推理提供了一种更具可扩展性的方法。
🎯 应用场景
InftyThink具有广泛的应用前景,可以应用于需要长文本推理的各种领域,例如数学问题求解、代码生成、法律文本分析、医学诊断等。该方法能够有效降低计算成本,提高推理效率,并突破现有模型的长度限制,从而使得大语言模型能够处理更加复杂的现实世界问题。未来,InftyThink有望成为长文本推理领域的重要技术手段。
📄 摘要(原文)
Advanced reasoning in large language models has achieved remarkable performance on challenging tasks, but the prevailing long-context reasoning paradigm faces critical limitations: quadratic computational scaling with sequence length, reasoning constrained by maximum context boundaries, and performance degradation beyond pre-training context windows. Existing approaches primarily compress reasoning chains without addressing the fundamental scaling problem. To overcome these challenges, we introduce InftyThink, a paradigm that transforms monolithic reasoning into an iterative process with intermediate summarization. By interleaving short reasoning segments with concise progress summaries, our approach enables unbounded reasoning depth while maintaining bounded computational costs. This creates a characteristic sawtooth memory pattern that significantly reduces computational complexity compared to traditional approaches. Furthermore, we develop a methodology for reconstructing long-context reasoning datasets into our iterative format, transforming OpenR1-Math into 333K training instances. Experiments across multiple model architectures demonstrate that our approach reduces computational costs while improving performance, with Qwen2.5-Math-7B showing 3-13% improvements across MATH500, AIME24, and GPQA_diamond benchmarks. Our work challenges the assumed trade-off between reasoning depth and computational efficiency, providing a more scalable approach to complex reasoning without architectural modifications.