WildIFEval: Instruction Following in the Wild
作者: Gili Lior, Asaf Yehudai, Ariel Gera, Liat Ein-Dor
分类: cs.CL, cs.AI
发布日期: 2025-03-09 (更新: 2025-10-07)
💡 一句话要点
WildIFEval:提出大规模真实用户指令数据集,评估LLM在复杂约束下的指令遵循能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 指令遵循 大型语言模型 数据集 多重约束 自然语言处理
📋 核心要点
- 现有大型语言模型在遵循用户指令方面表现出色,但在处理具有多重约束的指令时仍面临挑战。
- 本文构建了WildIFEval数据集,包含从真实用户指令中提取的多样化、多约束条件,用于评估LLM的指令遵循能力。
- 实验结果表明,现有LLM在WildIFEval数据集上仍有较大提升空间,且模型性能受约束数量和类型的影响。
📝 摘要(中文)
本文提出了WildIFEval,一个包含7K真实用户指令的大规模数据集,这些指令具有多样化的多重约束条件。与以往数据集不同,WildIFEval涵盖了广泛的词汇和主题约束,这些约束提取自自然的用户指令。我们将这些约束分为八个高级类别,以捕捉它们在真实场景中的分布和动态。利用WildIFEval,我们进行了广泛的实验,以评估领先LLM的指令遵循能力。WildIFEval能够清晰地区分小型和大型模型,并表明所有模型在此类任务上都有很大的改进空间。我们分析了约束的数量和类型对性能的影响,揭示了模型遵循约束行为的有趣模式。我们发布数据集以促进在复杂、真实条件下指令遵循的进一步研究。
🔬 方法详解
问题定义:现有的大型语言模型(LLM)在遵循用户指令方面取得了显著进展,但当指令包含多个约束条件时,性能会显著下降。现有的指令遵循数据集通常规模较小,或者约束条件不够多样化,无法充分反映真实世界用户指令的复杂性。因此,如何评估和提升LLM在复杂约束条件下的指令遵循能力是一个重要的研究问题。
核心思路:本文的核心思路是构建一个大规模、多样化的真实用户指令数据集WildIFEval,该数据集包含从自然用户指令中提取的多重约束条件。通过在该数据集上评估现有LLM的性能,可以更准确地了解模型在复杂约束条件下的指令遵循能力,并为未来的研究提供基准。
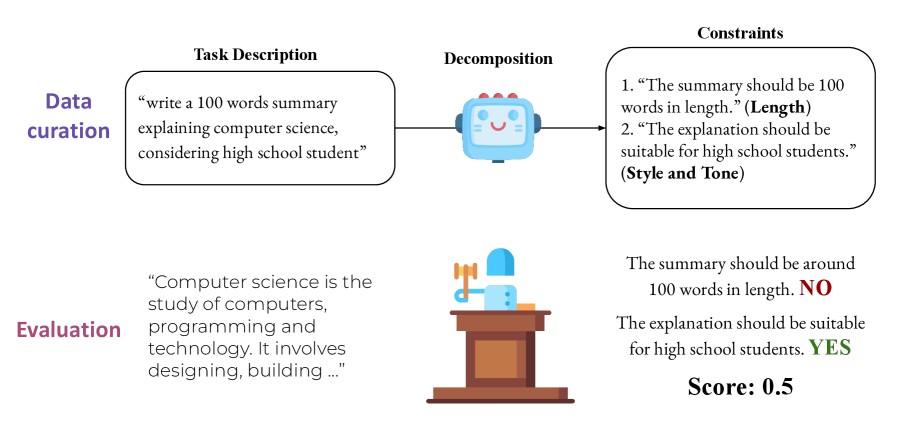
技术框架:WildIFEval数据集的构建流程主要包括以下几个步骤:1) 数据收集:从各种来源收集真实用户指令;2) 约束提取:从指令中提取约束条件,并将其分类为八个高级类别;3) 数据标注:对指令和约束进行标注,确保数据的质量和一致性;4) 数据集划分:将数据集划分为训练集、验证集和测试集。然后,利用WildIFEval数据集,对现有的LLM进行评估,分析模型在不同约束条件下的性能表现。
关键创新:本文的关键创新在于构建了一个大规模、多样化的真实用户指令数据集WildIFEval。与以往的数据集相比,WildIFEval具有以下几个显著的特点:1) 数据规模更大:包含7K条指令;2) 约束条件更丰富:涵盖了广泛的词汇和主题约束;3) 数据来源更真实:提取自自然的用户指令。
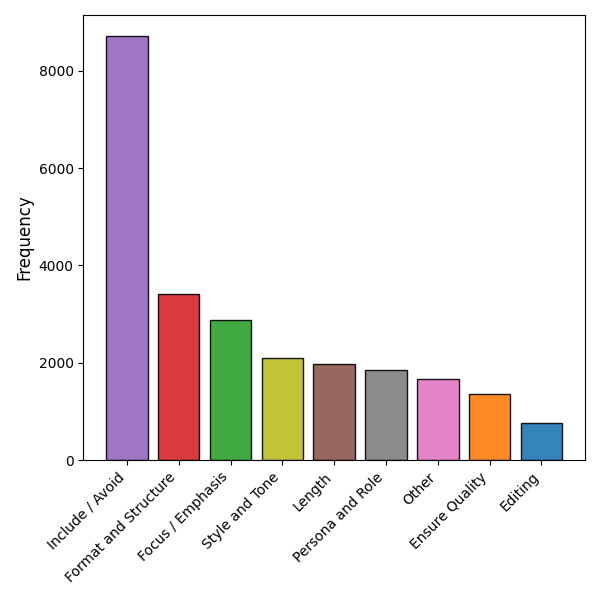
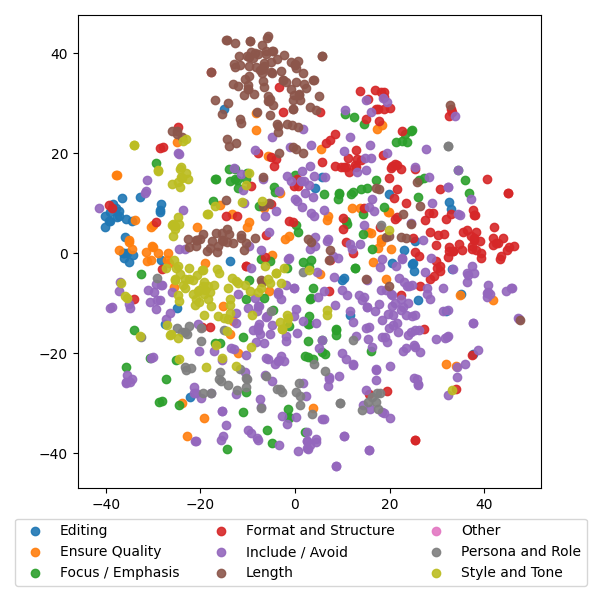
关键设计:WildIFEval数据集中的约束条件被分为八个高级类别,包括:时间约束、地点约束、数量约束、质量约束、格式约束、主题约束、用户约束和逻辑约束。这种分类方式有助于分析不同类型的约束对模型性能的影响。此外,数据集还提供了指令的详细标注信息,包括约束的类型、数量和位置等,方便研究人员进行更深入的分析。
🖼️ 关键图片
📊 实验亮点
实验结果表明,WildIFEval数据集能够有效区分不同规模的LLM,并且所有模型在处理多重约束指令时仍有较大的提升空间。研究发现,模型性能受到约束数量和类型的影响,例如,模型在处理时间约束和地点约束时表现相对较好,而在处理逻辑约束时表现较差。这些发现为未来的模型改进提供了重要的指导。
🎯 应用场景
该研究成果可应用于提升智能助手、搜索引擎等应用在复杂用户指令下的理解和执行能力。通过WildIFEval数据集,可以训练和评估更强大的指令遵循模型,从而提高用户体验和应用效率。未来,该数据集可以扩展到更多领域,例如机器人控制、自动驾驶等,促进人工智能技术在实际场景中的应用。
📄 摘要(原文)
Recent LLMs have shown remarkable success in following user instructions, yet handling instructions with multiple constraints remains a significant challenge. In this work, we introduce WildIFEval - a large-scale dataset of 7K real user instructions with diverse, multi-constraint conditions. Unlike prior datasets, our collection spans a broad lexical and topical spectrum of constraints, extracted from natural user instructions. We categorize these constraints into eight high-level classes to capture their distribution and dynamics in real-world scenarios. Leveraging WildIFEval, we conduct extensive experiments to benchmark the instruction-following capabilities of leading LLMs. WildIFEval clearly differentiates between small and large models, and demonstrates that all models have a large room for improvement on such tasks. We analyze the effects of the number and type of constraints on performance, revealing interesting patterns of model constraint-following behavior. We release our dataset to promote further research on instruction-following under complex, realistic conditions.