IDEA Prune: An Integrated Enlarge-and-Prune Pipeline in Generative Language Model Pretraining
作者: Yixiao Li, Xianzhi Du, Ajay Jaiswal, Tao Lei, Tuo Zhao, Chong Wang, Jianyu Wang
分类: cs.CL, cs.AI, cs.LG
发布日期: 2025-03-07
💡 一句话要点
提出IDEA Prune,一种生成语言模型预训练中集成的放大-剪枝流水线,提升剪枝模型性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 语言模型剪枝 结构化剪枝 模型压缩 预训练 放大模型 余弦退火 迭代剪枝
📋 核心要点
- 现有剪枝方法忽略了放大模型预训练的重要性,导致剪枝后的模型性能受限。
- 提出集成的放大-剪枝流水线,在统一的学习率调度下进行放大模型训练、剪枝和恢复。
- 实验结果表明,该方法不仅提升了token效率,还显著提高了剪枝后模型的性能。
📝 摘要(中文)
大型语言模型的快速发展对在有限的推理预算内实现高效且可部署的模型提出了更高的要求。相比于从头开始训练目标大小的模型,结构化剪枝流水线在token效率方面展现出潜力。本文提倡将放大模型预训练纳入剪枝流程,这在以往的研究中经常被忽略。我们将放大-剪枝流水线作为一个集成系统进行研究,以解决两个关键问题:预训练一个永远不会被部署的放大模型是否值得?如何优化整个流水线以获得更好的剪枝模型?我们提出了一种集成的放大-剪枝流水线,它在单个余弦退火学习率调度下结合了放大模型训练、剪枝和恢复。此外,我们还提出了一种新颖的迭代结构化剪枝方法,用于逐步移除参数。该方法有助于减轻朴素放大-剪枝流水线中学习率上升导致的知识损失,并能够有效地在幸存神经元之间重新分配模型容量,从而促进平滑压缩和性能提升。我们在将2.8B模型压缩到1.3B,并使用高达2T tokens进行预训练的实验中,证明了该集成方法不仅提供了关于放大模型预训练的token效率的见解,而且实现了剪枝模型的卓越性能。
🔬 方法详解
问题定义:现有的大型语言模型剪枝方法通常忽略了放大模型预训练阶段的重要性,或者没有将放大、剪枝和恢复过程作为一个整体进行优化。这导致剪枝后的模型性能提升有限,无法充分发挥剪枝的潜力。此外,简单的放大-剪枝流水线在学习率上升时容易造成知识损失,影响模型性能。
核心思路:本文的核心思路是将放大模型预训练、剪枝和恢复过程整合到一个统一的流水线中,并采用一种迭代结构化剪枝方法,以减轻知识损失并促进模型容量的有效重新分配。通过这种集成的方式,可以更好地利用放大模型预训练的优势,并优化整个剪枝过程,从而获得性能更优的剪枝模型。
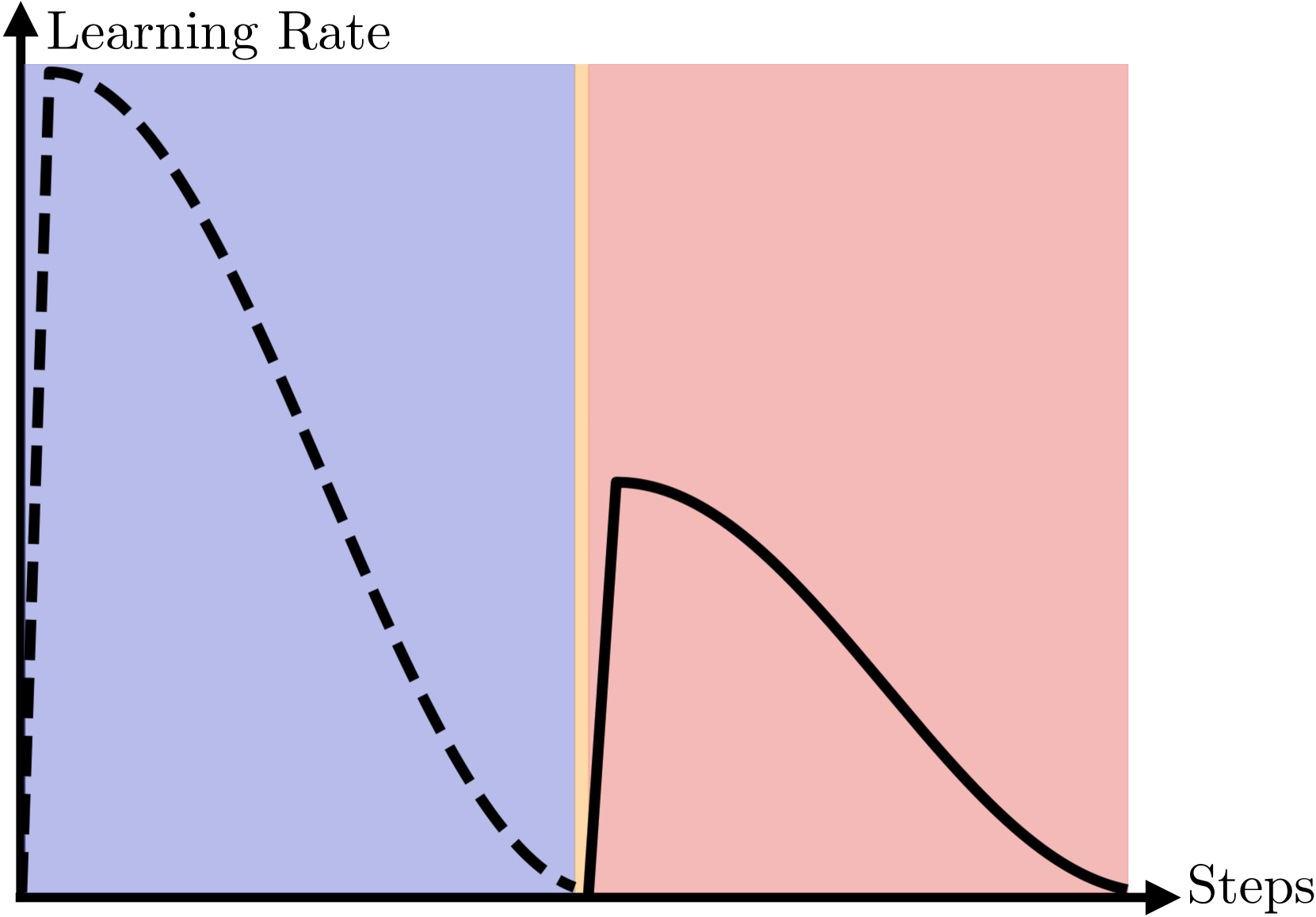
技术框架:该方法包含三个主要阶段:1) 放大模型训练:首先训练一个比目标大小更大的模型。2) 迭代结构化剪枝:采用一种新颖的迭代结构化剪枝方法,逐步移除模型中的参数。3) 恢复训练:在剪枝后,对模型进行恢复训练,以弥补剪枝带来的性能损失。整个流水线采用单个余弦退火学习率调度,以协调各个阶段的学习过程。
关键创新:该方法的主要创新点在于:1) 将放大模型预训练、剪枝和恢复整合到一个统一的流水线中,作为一个整体进行优化。2) 提出了一种迭代结构化剪枝方法,可以逐步移除参数,减轻知识损失,并促进模型容量的有效重新分配。3) 使用单个余弦退火学习率调度来协调各个阶段的学习过程。
关键设计:迭代结构化剪枝方法通过逐步移除模型中的权重,避免一次性大量剪枝造成的性能损失。余弦退火学习率调度在放大阶段使用较小的学习率,在剪枝和恢复阶段逐渐增大,以促进模型的稳定性和性能提升。具体的剪枝比例和学习率调整策略需要根据具体的模型和数据集进行调整。
🖼️ 关键图片
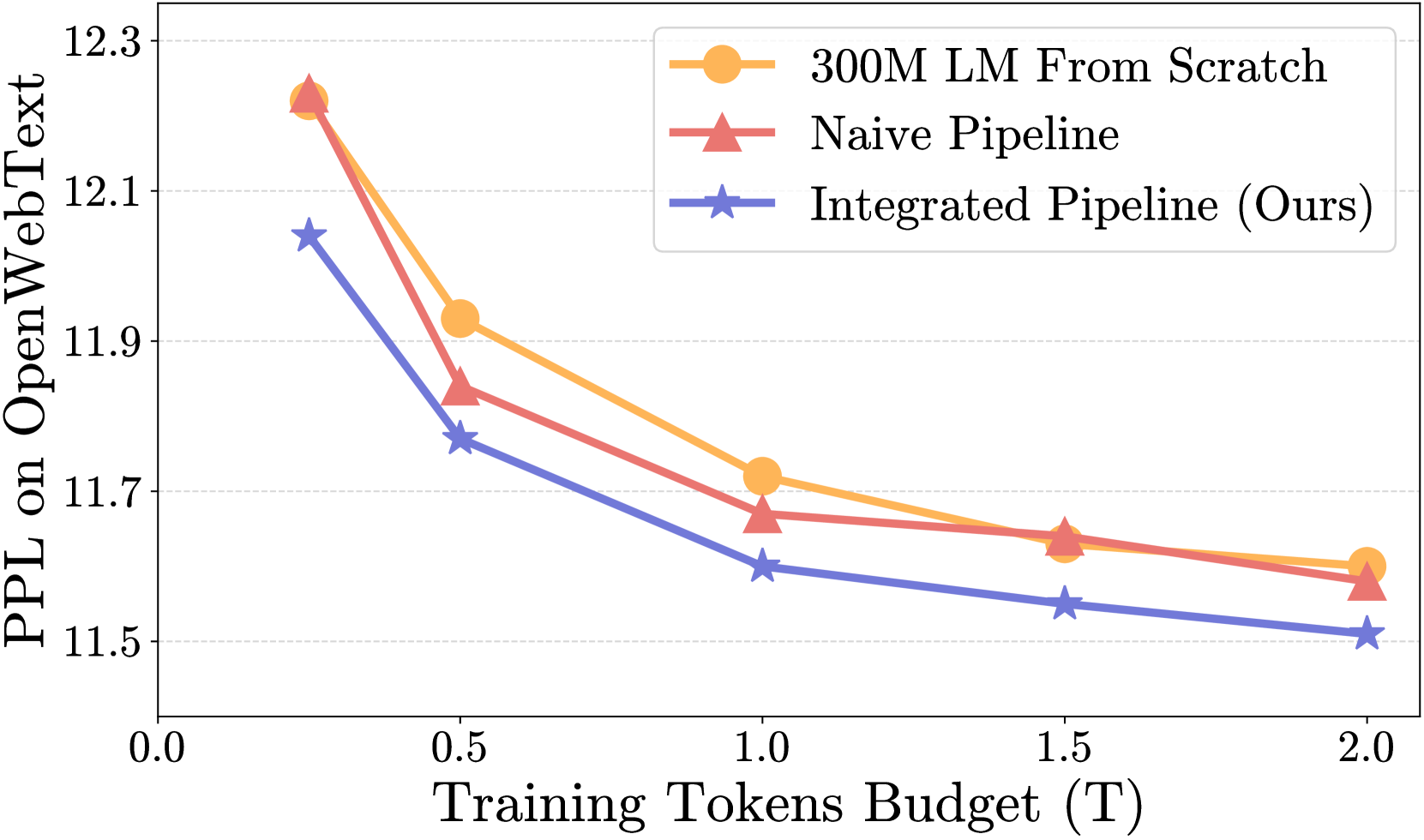
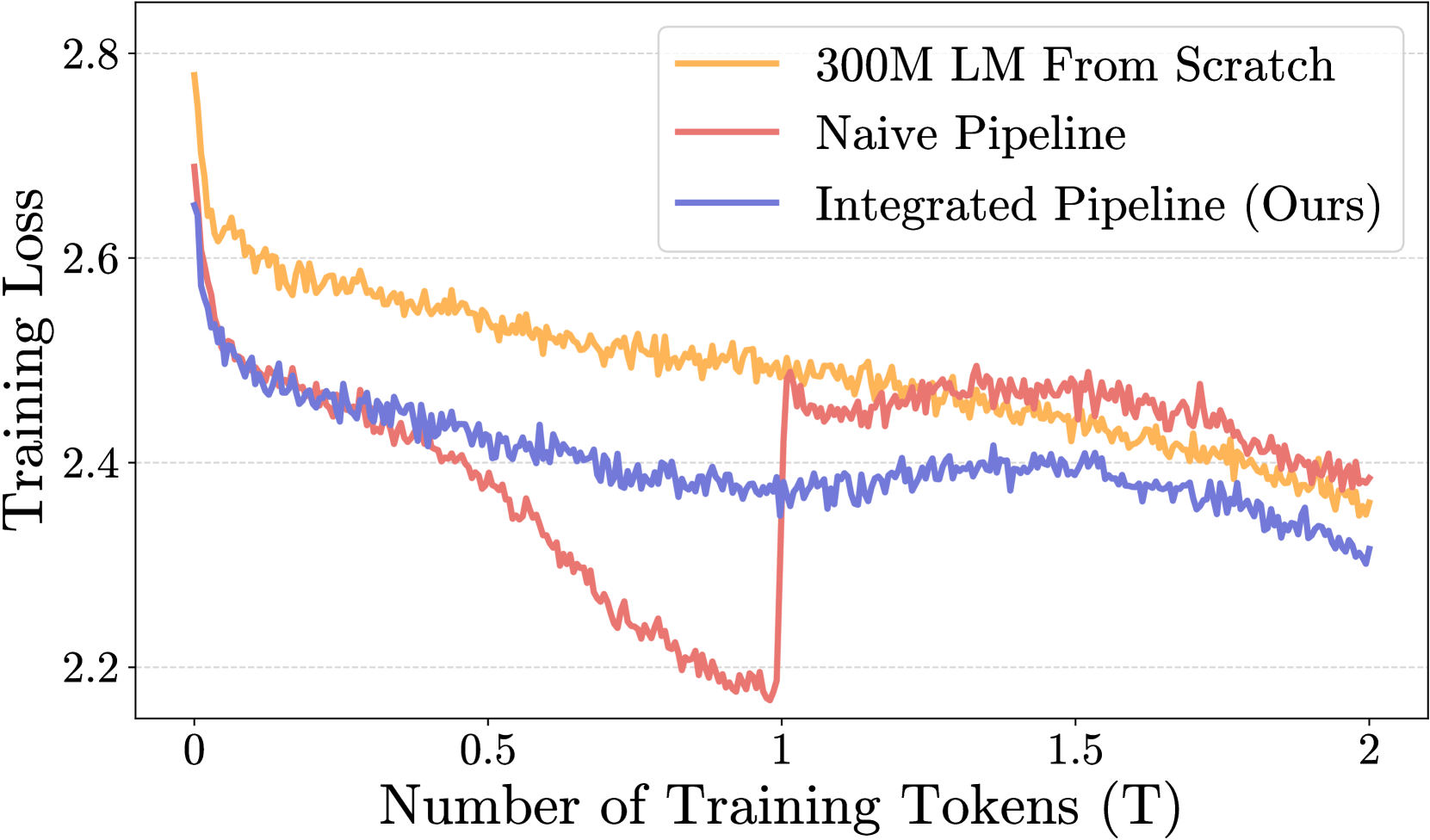
📊 实验亮点
实验结果表明,该方法可以将2.8B模型压缩到1.3B,同时保持甚至提升模型性能。与传统的剪枝方法相比,该方法在预训练任务上取得了显著的性能提升,证明了集成放大-剪枝流水线的有效性。
🎯 应用场景
该研究成果可应用于各种需要高效部署的大型语言模型场景,例如移动设备、边缘计算和资源受限的环境。通过剪枝,可以在不显著降低模型性能的前提下,减小模型大小,降低计算成本,从而实现更广泛的应用。
📄 摘要(原文)
Recent advancements in large language models have intensified the need for efficient and deployable models within limited inference budgets. Structured pruning pipelines have shown promise in token efficiency compared to training target-size models from scratch. In this paper, we advocate incorporating enlarged model pretraining, which is often ignored in previous works, into pruning. We study the enlarge-and-prune pipeline as an integrated system to address two critical questions: whether it is worth pretraining an enlarged model even when the model is never deployed, and how to optimize the entire pipeline for better pruned models. We propose an integrated enlarge-and-prune pipeline, which combines enlarge model training, pruning, and recovery under a single cosine annealing learning rate schedule. This approach is further complemented by a novel iterative structured pruning method for gradual parameter removal. The proposed method helps to mitigate the knowledge loss caused by the rising learning rate in naive enlarge-and-prune pipelines and enable effective redistribution of model capacity among surviving neurons, facilitating smooth compression and enhanced performance. We conduct comprehensive experiments on compressing 2.8B models to 1.3B with up to 2T tokens in pretraining. It demonstrates the integrated approach not only provides insights into the token efficiency of enlarged model pretraining but also achieves superior performance of pruned models.