This Is Your Doge, If It Please You: Exploring Deception and Robustness in Mixture of LLMs
作者: Lorenz Wolf, Sangwoong Yoon, Ilija Bogunovic
分类: cs.CL, cs.AI
发布日期: 2025-03-07
备注: 35 pages, 9 figures, 16 tables
💡 一句话要点
揭示LLM混合架构的欺骗脆弱性,并提出防御机制以提升鲁棒性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: LLM混合架构 欺骗攻击 鲁棒性 无监督防御 安全性 AlpacaEval QuALITY
📋 核心要点
- 现有LLM混合架构(MoA)在安全性与可靠性评估方面存在不足,易受恶意Agent的欺骗攻击。
- 论文核心在于分析欺骗Agent对MoA性能的影响,并设计无监督防御机制来提升其鲁棒性。
- 实验表明,引入单个欺骗Agent即可显著降低MoA性能,而提出的防御机制能够有效恢复性能。
📝 摘要(中文)
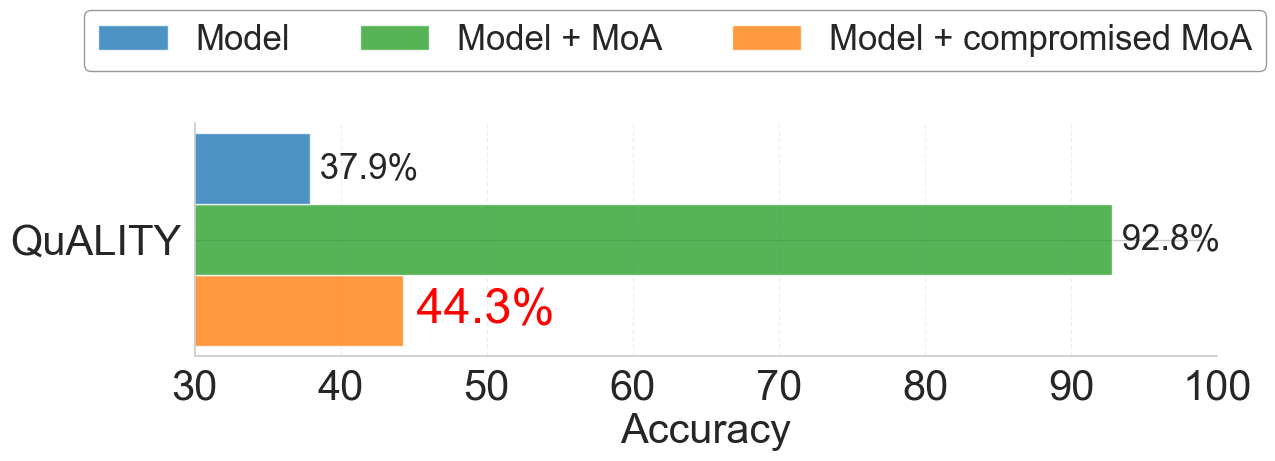
本文首次全面研究了LLM混合Agent(MoA)架构在面对恶意欺骗Agent时的鲁棒性。MoA架构通过在推理时利用多个LLM的协作,在AlpacaEval 2.0等基准测试中取得了最先进的性能。研究揭示了欺骗信息的传播、模型大小和信息可用性等因素对MoA的影响,并发现了其关键漏洞。例如,在AlpacaEval 2.0上,将单个精心设计的欺骗Agent引入到包含6个LLM Agent的3层MoA中,可将LLaMA 3.1-70B模型的长度控制胜率(LC WR)从49.2%降低到37.9%。在QuALITY多项选择理解任务中,准确率也大幅下降了48.5%。受威尼斯总督选举投票过程的启发,本文提出了一系列无监督防御机制,可以恢复大部分损失的性能。
🔬 方法详解
问题定义:论文旨在解决LLM混合Agent架构(MoA)在面对恶意欺骗Agent时存在的脆弱性问题。现有方法缺乏对MoA安全性和可靠性的全面评估,尤其是在对抗故意提供误导性信息的Agent时。这种脆弱性可能导致MoA在实际应用中产生错误或有害的结果。
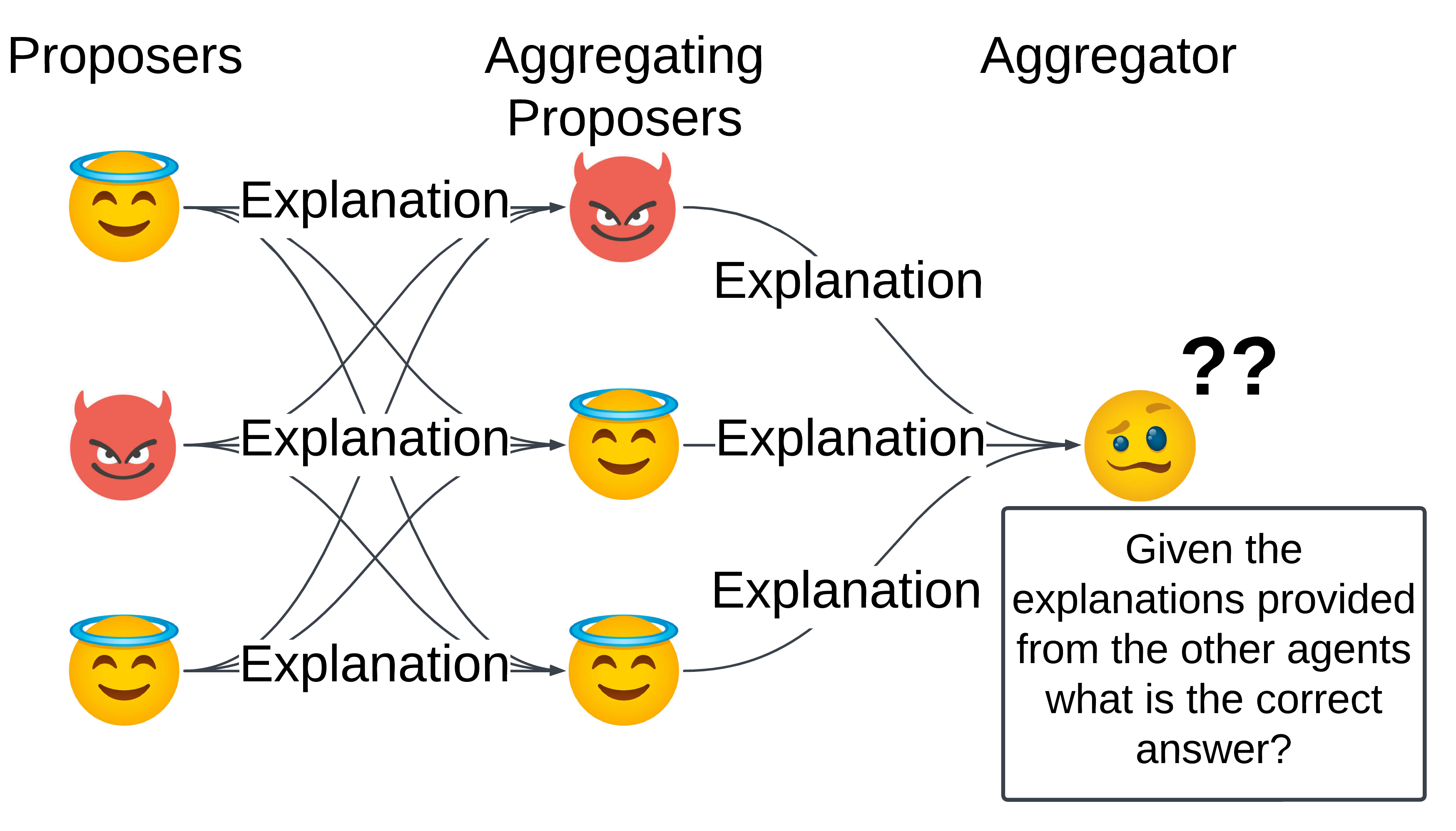
核心思路:论文的核心思路是分析欺骗Agent如何影响MoA的决策过程,并设计相应的防御机制来减轻这种影响。通过模拟欺骗攻击并评估其对MoA性能的影响,可以识别关键的漏洞。然后,利用无监督学习方法,例如基于Agent输出一致性的过滤或加权,来识别和抑制欺骗Agent的影响。
技术框架:论文的技术框架主要包括以下几个阶段:1) 构建MoA架构,包含多个LLM Agent;2) 设计欺骗Agent,使其能够故意提供误导性信息;3) 评估欺骗Agent对MoA性能的影响,使用AlpacaEval 2.0和QuALITY等基准测试;4) 提出无监督防御机制,例如基于Agent输出一致性的过滤或加权;5) 评估防御机制的有效性,比较在有无防御机制的情况下MoA的性能。
关键创新:论文最重要的技术创新点在于首次全面研究了MoA在面对欺骗Agent时的鲁棒性,并提出了有效的无监督防御机制。与现有方法不同,该研究不仅关注MoA的性能,还关注其安全性,并提出了具体的解决方案来应对欺骗攻击。
关键设计:论文的关键设计包括:1) 精心设计的欺骗Agent,能够根据指令提供误导性信息;2) 基于Agent输出一致性的过滤机制,用于识别和抑制欺骗Agent的影响;3) 基于Agent输出加权的机制,用于降低欺骗Agent的权重,提高可信Agent的权重;4) 使用AlpacaEval 2.0和QuALITY等基准测试来评估MoA的性能和防御机制的有效性。具体的参数设置和网络结构等技术细节在论文中进行了详细描述(未知)。
🖼️ 关键图片

📊 实验亮点
实验结果表明,引入单个欺骗Agent可以将LLaMA 3.1-70B模型在AlpacaEval 2.0上的长度控制胜率(LC WR)从49.2%降低到37.9%,在QuALITY数据集上准确率下降48.5%。提出的无监督防御机制能够有效恢复大部分损失的性能,显著提升MoA的鲁棒性。这些结果表明,MoA架构存在潜在的安全风险,需要采取相应的防御措施。
🎯 应用场景
该研究成果可应用于各种需要LLM协作的场景,例如智能客服、内容创作、决策支持等。通过提高LLM混合架构的鲁棒性,可以减少恶意信息的影响,提高系统的可靠性和安全性,从而为用户提供更准确、更可信的服务。未来,该研究可以扩展到更复杂的欺骗场景和更强大的防御机制。
📄 摘要(原文)
Mixture of large language model (LLMs) Agents (MoA) architectures achieve state-of-the-art performance on prominent benchmarks like AlpacaEval 2.0 by leveraging the collaboration of multiple LLMs at inference time. Despite these successes, an evaluation of the safety and reliability of MoA is missing. We present the first comprehensive study of MoA's robustness against deceptive LLM agents that deliberately provide misleading responses. We examine factors like the propagation of deceptive information, model size, and information availability, and uncover critical vulnerabilities. On AlpacaEval 2.0, the popular LLaMA 3.1-70B model achieves a length-controlled Win Rate (LC WR) of 49.2% when coupled with 3-layer MoA (6 LLM agents). However, we demonstrate that introducing only a $\textit{single}$ carefully-instructed deceptive agent into the MoA can reduce performance to 37.9%, effectively nullifying all MoA gains. On QuALITY, a multiple-choice comprehension task, the impact is also severe, with accuracy plummeting by a staggering 48.5%. Inspired in part by the historical Doge of Venice voting process, designed to minimize influence and deception, we propose a range of unsupervised defense mechanisms that recover most of the lost performance.