EMCee: Improving Multilingual Capability of LLMs via Bridging Knowledge and Reasoning with Extracted Synthetic Multilingual Context
作者: Hamin Koo, Jaehyung Kim
分类: cs.CL, cs.AI
发布日期: 2025-03-07 (更新: 2025-10-17)
备注: under review, 21pages
💡 一句话要点
EMCee:通过提取合成多语言上下文桥接知识与推理,提升LLM的多语言能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多语言模型 大型语言模型 上下文学习 知识融合 低资源语言 合成数据 推理能力
📋 核心要点
- 现有LLM在非英语语言任务中表现不佳,主要原因是其训练数据以英语为中心,缺乏对其他语言和文化的深入理解。
- EMCee通过从LLM中提取合成多语言上下文,并将这些上下文知识与推理结果融合,从而弥补了LLM在多语言知识方面的不足。
- 实验结果表明,EMCee在多个多语言基准测试中显著优于现有方法,尤其是在低资源语言上,性能提升尤为明显。
📝 摘要(中文)
大型语言模型(LLMs)在各种任务中取得了显著进展,但它们严重依赖以英语为中心的训练数据,导致在非英语语言中的性能显著下降。现有的多语言提示方法侧重于将查询改写为英语或增强推理能力,但通常未能纳入某些查询所必需的特定于语言和文化的知识基础。为了解决这个局限性,我们提出了EMCee(提取合成多语言上下文并合并),这是一个简单而有效的框架,通过显式地从LLM本身提取和利用与查询相关的知识来增强LLM的多语言能力。具体而言,EMCee首先提取合成上下文,以揭示LLM中编码的潜在的、特定于语言的知识,然后通过基于判断的选择机制,将这种上下文洞察动态地与面向推理的输出合并。在涵盖不同语言和任务的四个多语言基准上的大量实验表明,EMCee始终优于先前的方法,总体平均相对改进为16.4%,在低资源语言中为31.7%。
🔬 方法详解
问题定义:大型语言模型在处理非英语语言任务时,由于训练数据偏向英语,导致性能显著下降。现有的多语言方法,如将查询翻译成英语或增强推理能力,未能充分利用语言和文化相关的知识,无法有效解决所有问题。因此,需要一种方法来弥补LLM在多语言知识方面的不足,提升其在非英语语言任务中的表现。
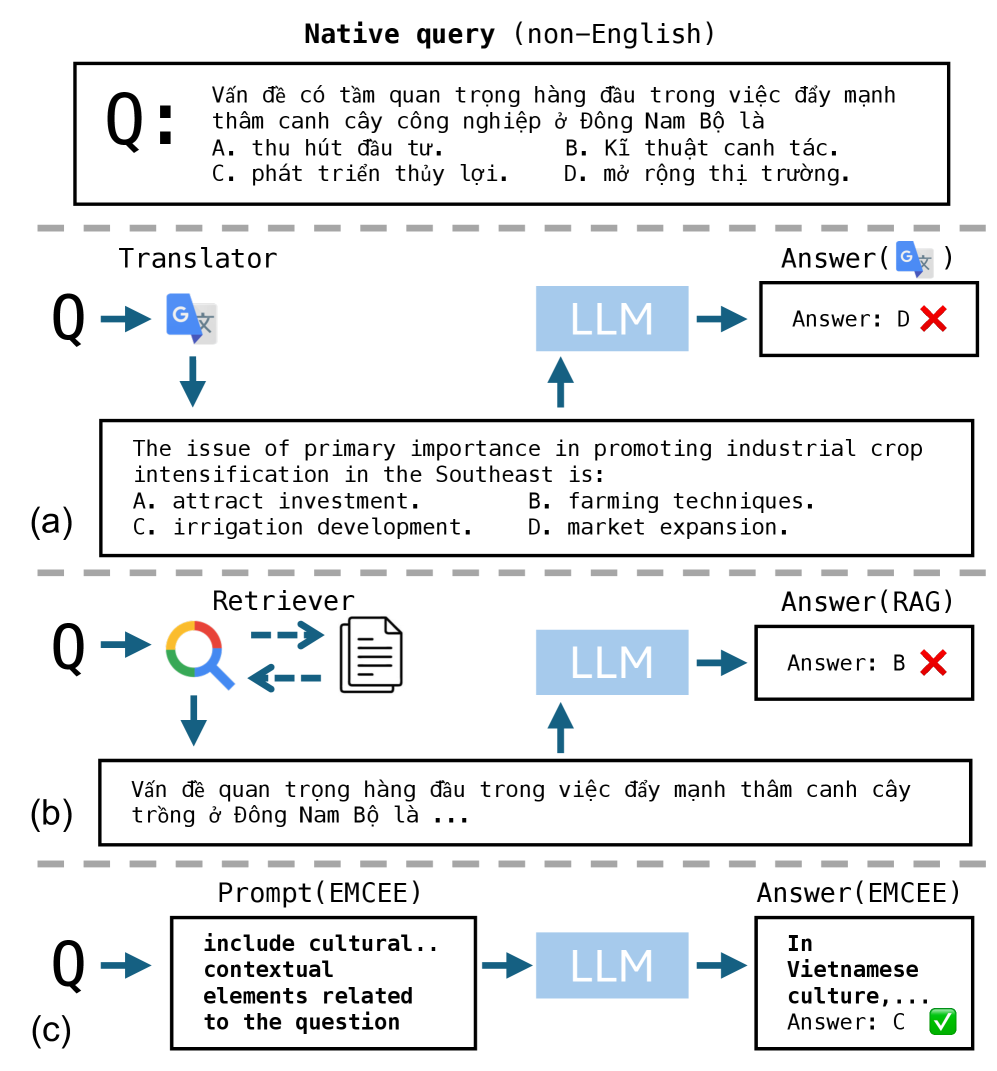
核心思路:EMCee的核心思路是从LLM自身提取潜在的、特定于语言的知识,并将其与推理过程相结合。通过提取合成多语言上下文,EMCee能够挖掘LLM中隐藏的、与查询相关的知识,从而更好地理解和处理非英语语言的查询。这种方法避免了对外部知识库的依赖,充分利用了LLM自身的知识储备。
技术框架:EMCee框架主要包含两个阶段:上下文提取和结果融合。首先,EMCee利用特定的prompt从LLM中提取合成上下文,这些上下文包含了与查询相关的多语言知识。然后,EMCee将提取的上下文与LLM的推理结果进行融合,通过一个基于判断的选择机制,选择最合适的答案。这个选择机制可以根据上下文和推理结果的质量,动态地调整融合策略。
关键创新:EMCee的关键创新在于其显式地从LLM自身提取合成多语言上下文,并将其用于增强推理过程。与以往的方法不同,EMCee不依赖于外部知识库或翻译,而是充分利用了LLM自身的知识储备。此外,EMCee的基于判断的选择机制能够动态地调整融合策略,从而更好地适应不同的查询和语言。
关键设计:EMCee的关键设计包括上下文提取的prompt设计和基于判断的选择机制。上下文提取的prompt需要能够有效地引导LLM生成与查询相关的多语言知识。基于判断的选择机制需要能够准确地评估上下文和推理结果的质量,并选择最合适的答案。具体的prompt设计和选择机制的实现细节在论文中进行了详细描述。
🖼️ 关键图片

📊 实验亮点
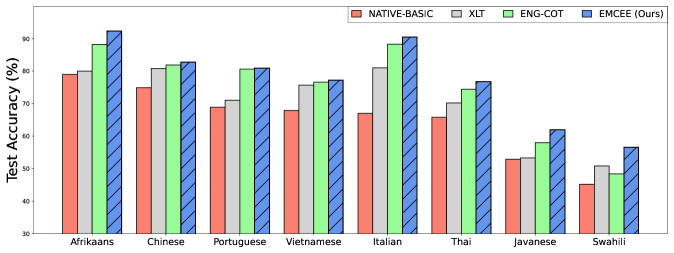
EMCee在四个多语言基准测试中取得了显著的性能提升,总体平均相对改进为16.4%,在低资源语言中更是达到了31.7%。这些结果表明,EMCee能够有效地提升LLM的多语言能力,尤其是在缺乏训练数据的低资源语言上。与现有方法相比,EMCee具有更强的泛化能力和更高的效率。
🎯 应用场景
EMCee具有广泛的应用前景,可以应用于机器翻译、跨语言信息检索、多语言问答等领域。通过提升LLM的多语言能力,EMCee可以帮助用户更好地访问和利用各种语言的信息资源,促进不同语言和文化之间的交流与理解。此外,EMCee还可以应用于低资源语言的处理,帮助这些语言更好地融入数字世界。
📄 摘要(原文)
Large Language Models (LLMs) have achieved impressive progress across a wide range of tasks, yet their heavy reliance on English-centric training data leads to significant performance degradation in non-English languages. While existing multilingual prompting methods emphasize reformulating queries into English or enhancing reasoning capabilities, they often fail to incorporate the language- and culture-specific grounding that is essential for some queries. To address this limitation, we propose EMCee (Extracting synthetic Multilingual Context and merging), a simple yet effective framework that enhances the multilingual capabilities of LLMs by explicitly extracting and utilizing query-relevant knowledge from the LLM itself. In particular, EMCee first extracts synthetic context to uncover latent, language-specific knowledge encoded within the LLM, and then dynamically merges this contextual insight with reasoning-oriented outputs through a judgment-based selection mechanism. Extensive experiments on four multilingual benchmarks covering diverse languages and tasks demonstrate that EMCee consistently outperforms prior approaches, achieving an average relative improvement of 16.4% overall and 31.7% in low-resource languages.