Knowledge Updating? No More Model Editing! Just Selective Contextual Reasoning
作者: Guoxiu He, Xin Song, Aixin Sun
分类: cs.CL, cs.AI
发布日期: 2025-03-07
💡 一句话要点
提出选择性上下文推理(SCR),无需模型编辑即可更新LLM知识。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 知识更新 模型编辑 上下文推理 知识库
📋 核心要点
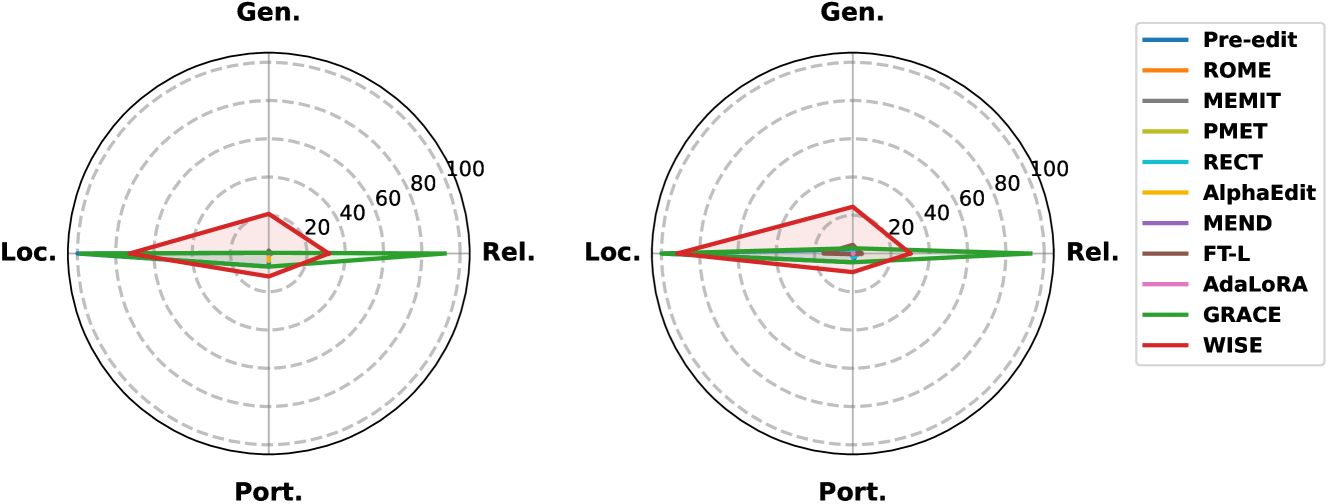
- 现有模型编辑方法在更新LLM知识时,容易对模型中广泛分布的知识产生副作用,且在多跳推理和持续知识更新方面表现不佳。
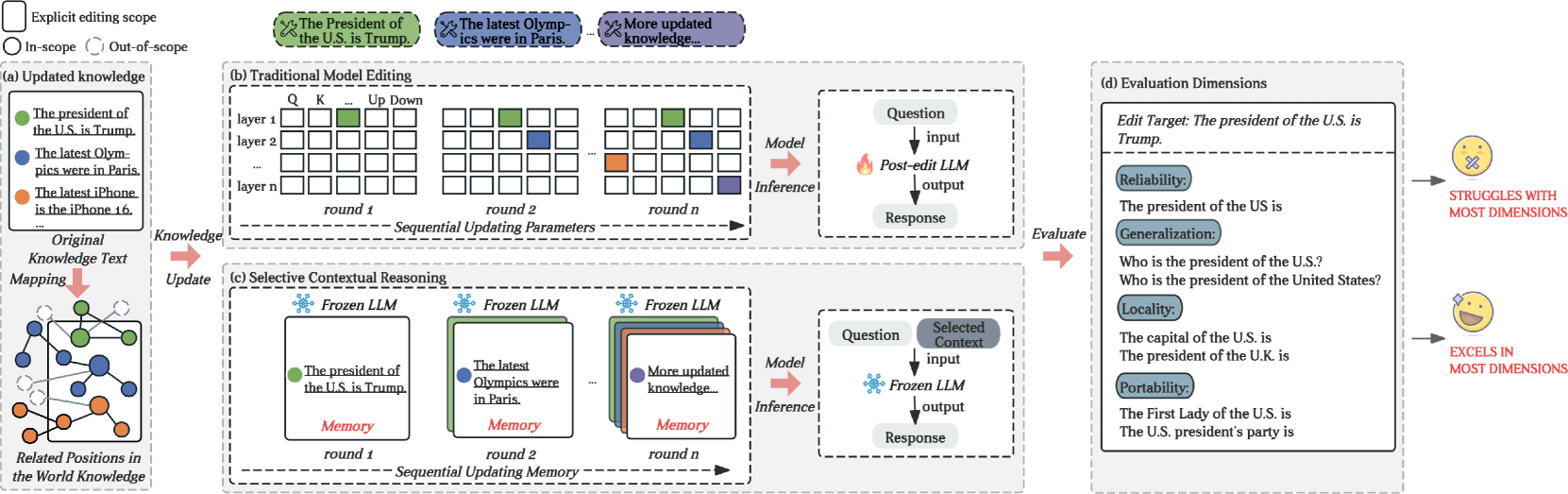
- 论文提出选择性上下文推理(SCR)方法,该方法不修改模型参数,而是利用LLM的上下文推理能力,结合外部知识库进行知识更新。
- 实验结果表明,SCR在知识更新方面优于十种流行的模型编辑方法,证明了上下文推理在知识更新方面的有效性和效率。
📝 摘要(中文)
随着现实世界知识的演变,大型语言模型(LLM)中嵌入的信息可能会变得过时、不足或错误。模型编辑已成为一种以最小的计算成本和参数更改来更新LLM知识的重要方法。这种方法通常识别并调整与新获取的知识相关的特定模型参数。然而,现有方法往往低估了参数修改可能对广泛分布的知识产生的负面影响。更关键的是,编辑后的LLM经常在多跳推理和连续知识更新方面遇到困难。尽管各种研究已经讨论了这些缺点,但缺乏全面的评估。在本文中,我们从可靠性、泛化性、局部性和可移植性四个维度评估了十种模型编辑方法。结果证实,所有十种流行的模型编辑方法在多个维度上都显示出明显的缺点,表明模型编辑不太有希望。然后,我们提出了一种名为选择性上下文推理(SCR)的简单方法来进行知识更新。SCR不修改模型参数,而是利用LLM固有的上下文推理能力,使用更新的知识片段。在SCR下,LLM首先评估传入的查询是否属于外部知识库的范围。如果是,则将相关的外部知识文本上下文化以增强推理;否则,直接回答查询。我们针对两个反事实数据集和三个骨干LLM,将SCR与十种模型编辑方法进行了评估。实验结果证实了上下文推理在知识更新方面的有效性和效率。
🔬 方法详解
问题定义:现有模型编辑方法试图通过修改LLM的参数来更新知识,但这种修改可能会破坏模型中已有的知识,导致可靠性、泛化性和局部性等问题。此外,模型编辑方法在处理多跳推理和持续知识更新时也存在困难。因此,如何高效且安全地更新LLM的知识是一个重要的研究问题。
核心思路:论文的核心思路是利用LLM的上下文学习能力,而不是直接修改模型参数。通过将外部知识库中的相关信息作为上下文提供给LLM,引导LLM进行推理和回答问题。这种方法避免了对模型参数的直接修改,从而降低了破坏已有知识的风险。
技术框架:SCR方法包含两个主要阶段:知识范围判断和上下文推理。首先,判断输入的查询是否属于外部知识库的范围。如果属于,则从知识库中检索相关的知识片段。然后,将检索到的知识片段与原始查询一起作为上下文输入到LLM中,利用LLM的上下文推理能力生成答案。如果查询不属于知识库范围,则直接由LLM回答。
关键创新:SCR的关键创新在于它避免了对LLM参数的直接修改,而是通过上下文学习的方式来更新知识。这种方法更加安全和高效,并且可以更好地保持LLM的已有知识。此外,SCR还引入了知识范围判断机制,可以有效地利用外部知识库,提高知识更新的准确性。
关键设计:SCR的关键设计包括:1) 如何有效地判断查询是否属于知识库的范围;2) 如何从知识库中检索最相关的知识片段;3) 如何将检索到的知识片段与原始查询进行有效的组合,以最大化LLM的上下文推理能力。具体的实现细节(例如,知识范围判断的具体算法、知识检索的相似度度量方法、上下文组合的方式)在论文中可能有所描述,但摘要中未明确提及。
🖼️ 关键图片
📊 实验亮点
论文对十种流行的模型编辑方法进行了全面的评估,发现它们在可靠性、泛化性、局部性和可移植性等方面都存在明显的缺点。实验结果表明,SCR方法在知识更新方面优于这些模型编辑方法,证明了上下文推理在知识更新方面的有效性和效率。具体的性能数据和提升幅度在摘要中未明确提及,需要在论文中查找。
🎯 应用场景
该研究成果可应用于需要持续更新知识的LLM应用场景,例如智能客服、知识问答系统、智能助手等。通过SCR方法,可以高效地将最新的知识融入到LLM中,提高LLM的回答质量和准确性,从而提升用户体验。此外,该方法还可以用于构建更加可靠和可信赖的LLM系统。
📄 摘要(原文)
As real-world knowledge evolves, the information embedded within large language models (LLMs) can become outdated, inadequate, or erroneous. Model editing has emerged as a prominent approach for updating LLMs' knowledge with minimal computational costs and parameter changes. This approach typically identifies and adjusts specific model parameters associated with newly acquired knowledge. However, existing methods often underestimate the adverse effects that parameter modifications can have on broadly distributed knowledge. More critically, post-edit LLMs frequently struggle with multi-hop reasoning and continuous knowledge updates. Although various studies have discussed these shortcomings, there is a lack of comprehensive evaluation. In this paper, we provide an evaluation of ten model editing methods along four dimensions: reliability, generalization, locality, and portability. Results confirm that all ten popular model editing methods show significant shortcomings across multiple dimensions, suggesting model editing is less promising. We then propose a straightforward method called Selective Contextual Reasoning (SCR), for knowledge updating. SCR does not modify model parameters but harnesses LLM's inherent contextual reasoning capabilities utilizing the updated knowledge pieces. Under SCR, an LLM first assesses whether an incoming query falls within the scope of an external knowledge base. If it does, the relevant external knowledge texts are contextualized to enhance reasoning; otherwise, the query is answered directly. We evaluate SCR against the ten model editing methods on two counterfactual datasets with three backbone LLMs. Empirical results confirm the effectiveness and efficiency of contextual reasoning for knowledge updating.