Rewarding Curse: Analyze and Mitigate Reward Modeling Issues for LLM Reasoning
作者: Jiachun Li, Pengfei Cao, Yubo Chen, Jiexin Xu, Huaijun Li, Xiaojian Jiang, Kang Liu, Jun Zhao
分类: cs.CL, cs.AI
发布日期: 2025-03-07
备注: 18 pages, 21 figures
💡 一句话要点
针对LLM推理中奖励模型问题的分析与缓解方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 思维链 提示学习 推理能力 信息增益
📋 核心要点
- 现有方法缺乏对影响CoT推理性能的关键因素的深入分析,尤其是在有效性和忠实性方面。
- 该论文提出一种新算法,通过从问题中回忆额外信息来增强CoT生成,并基于信息增益评估CoT。
- 实验结果表明,该方法能够有效提升CoT的忠实性和有效性,从而改善LLM的推理能力。
📝 摘要(中文)
思维链(CoT)提示在不同的推理任务中表现出不同的性能。先前的工作试图评估它,但未能对影响CoT的模式进行深入分析。本文从有效性和忠实性的角度研究CoT的性能。对于有效性,我们确定了影响CoT在性能改进方面的关键因素,包括问题难度、信息增益和信息流。对于忠实性,我们通过对问题、CoT和答案之间的信息交互进行联合分析来解释不忠实的CoT问题。结果表明,当LLM预测答案时,它可以从问题中回忆起CoT中缺失的正确信息,从而导致问题。最后,我们提出了一种新的算法来缓解这个问题,其中我们从问题中回忆额外的信息来增强CoT的生成,并根据它们的信息增益来评估CoT。大量的实验表明,我们的方法提高了CoT的忠实性和有效性。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在使用思维链(CoT)提示进行推理时,CoT的有效性和忠实性问题。现有方法未能充分分析影响CoT性能的关键因素,导致CoT在不同推理任务中表现不稳定,甚至出现不忠实的情况,即CoT推理过程错误,但最终答案正确。
核心思路:论文的核心思路是深入分析影响CoT有效性的因素(问题难度、信息增益、信息流),并揭示CoT不忠实的原因(LLM从问题中回忆信息弥补CoT的不足)。基于此,提出一种新的算法,通过增强CoT的信息量和评估CoT的信息增益,来提高CoT的有效性和忠实性。
技术框架:该算法主要包含两个阶段:1) CoT增强阶段:从原始问题中提取额外信息,并将其融入到CoT的生成过程中,从而丰富CoT的信息量,提高其有效性。2) CoT评估阶段:基于信息增益评估CoT的质量,选择信息增益最高的CoT作为最终的推理过程,从而提高CoT的忠实性。
关键创新:该论文的关键创新在于:1) 深入分析了影响CoT有效性和忠实性的关键因素,为后续研究提供了理论基础。2) 提出了一种新的CoT增强和评估算法,能够有效提高CoT的有效性和忠实性,从而改善LLM的推理能力。3) 结合信息增益来评估CoT的质量,是一种新颖的思路,能够更准确地衡量CoT对最终答案的贡献。
关键设计:CoT增强阶段,如何从问题中提取相关信息,可能涉及到关键词提取、语义相似度计算等技术。CoT评估阶段,信息增益的计算方式,需要定义合适的指标来衡量CoT对答案的贡献。具体的损失函数和网络结构未知,需要参考论文细节。
🖼️ 关键图片
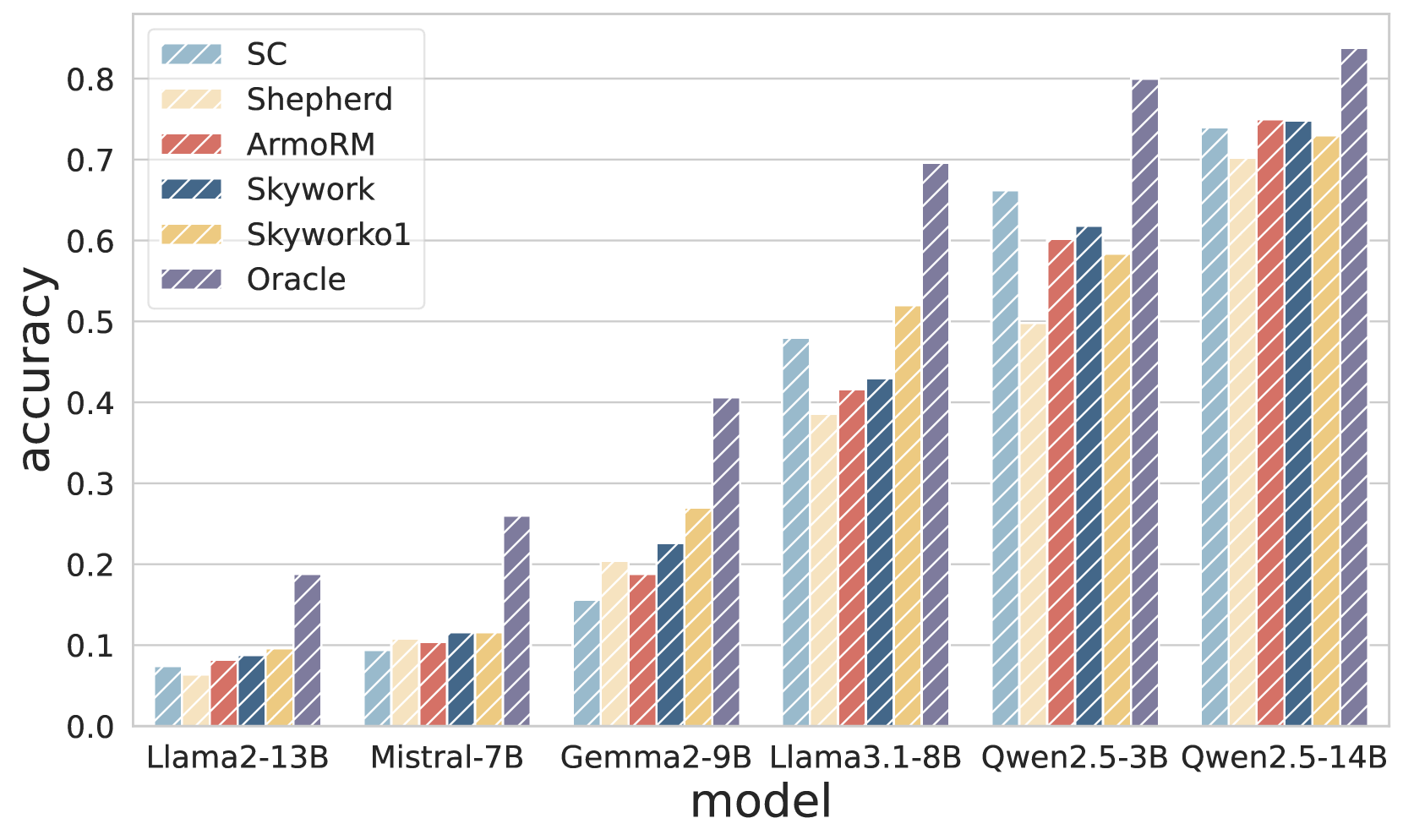
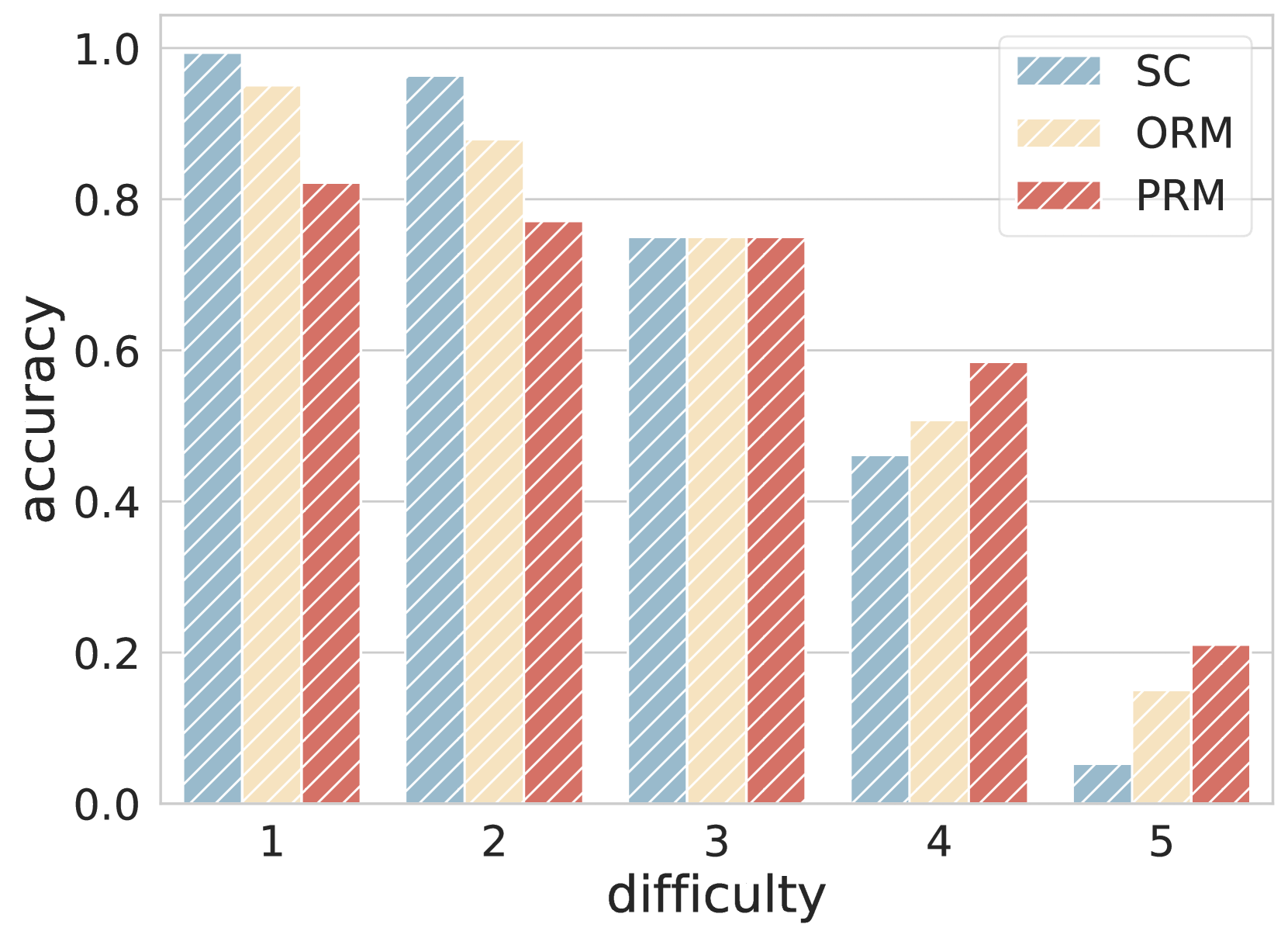
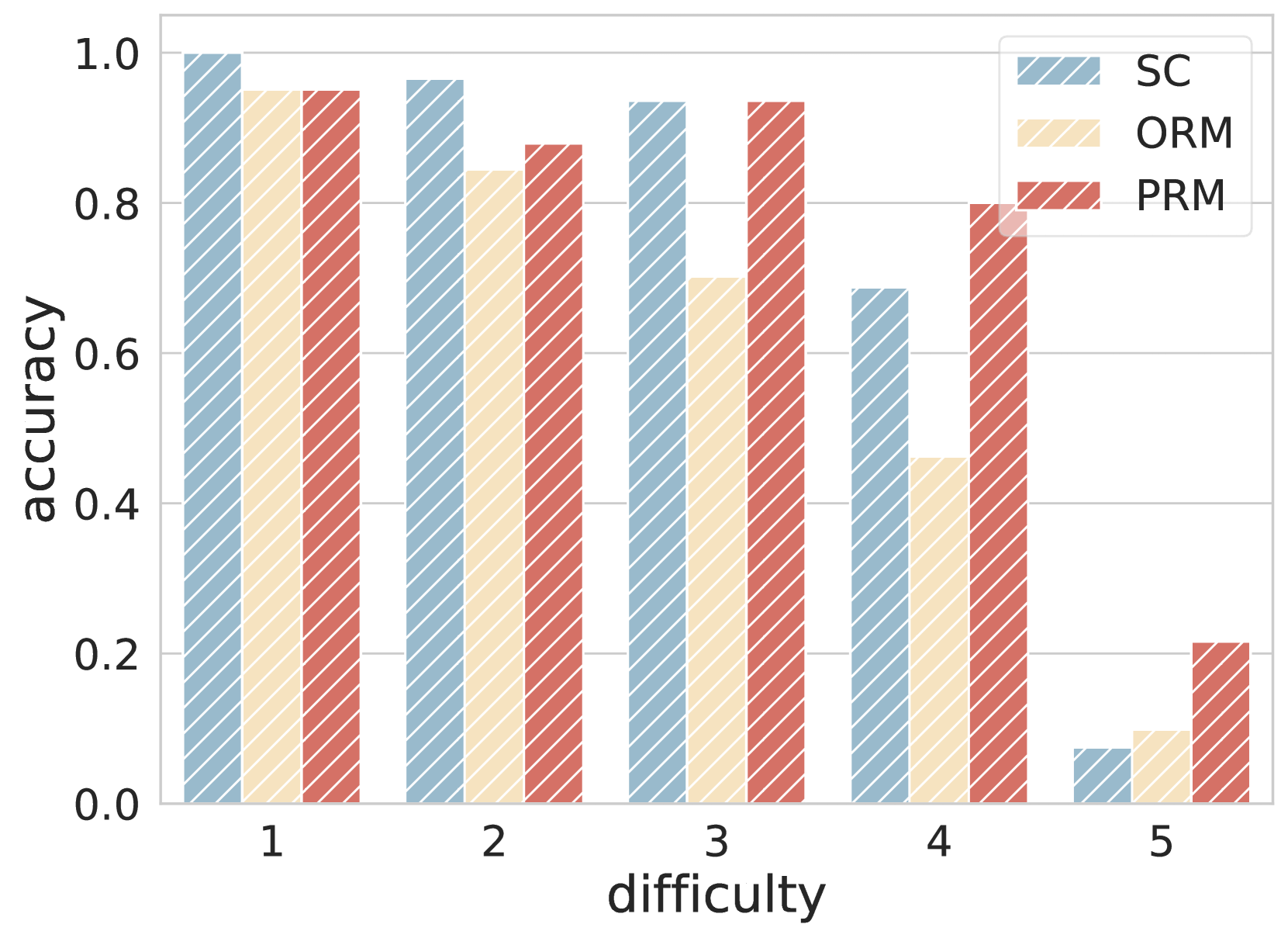
📊 实验亮点
论文通过实验验证了所提出算法的有效性,结果表明该算法能够显著提高CoT的忠实性和有效性。具体的性能数据和对比基线未知,需要参考论文细节。但整体而言,该研究为提升LLM的推理能力提供了一种新的思路和方法。
🎯 应用场景
该研究成果可应用于各种需要LLM进行复杂推理的场景,例如问答系统、知识图谱推理、代码生成等。通过提高CoT的有效性和忠实性,可以提升LLM在这些应用中的性能和可靠性,使其能够更好地服务于实际应用。
📄 摘要(原文)
Chain-of-thought (CoT) prompting demonstrates varying performance under different reasoning tasks. Previous work attempts to evaluate it but falls short in providing an in-depth analysis of patterns that influence the CoT. In this paper, we study the CoT performance from the perspective of effectiveness and faithfulness. For the former, we identify key factors that influence CoT effectiveness on performance improvement, including problem difficulty, information gain, and information flow. For the latter, we interpret the unfaithful CoT issue by conducting a joint analysis of the information interaction among the question, CoT, and answer. The result demonstrates that, when the LLM predicts answers, it can recall correct information missing in the CoT from the question, leading to the problem. Finally, we propose a novel algorithm to mitigate this issue, in which we recall extra information from the question to enhance the CoT generation and evaluate CoTs based on their information gain. Extensive experiments demonstrate that our approach enhances both the faithfulness and effectiveness of CoT.