Sketch-of-Thought: Efficient LLM Reasoning with Adaptive Cognitive-Inspired Sketching
作者: Simon A. Aytes, Jinheon Baek, Sung Ju Hwang
分类: cs.CL, cs.AI, cs.LG
发布日期: 2025-03-07 (更新: 2025-10-24)
备注: EMNLP 2025
💡 一句话要点
提出Sketch-of-Thought,通过认知启发式草图方法提升LLM推理效率并减少token使用。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 思维链 认知启发式 推理优化 提示工程
📋 核心要点
- 现有CoT推理方法中间输出冗长,计算开销大,限制了LLM的效率。
- SoT框架结合认知启发式推理和语言约束,通过精简的“草图”式表达减少token使用。
- 实验表明,SoT在多个推理任务中显著减少token,并在部分任务中提升了准确率。
📝 摘要(中文)
大型语言模型(LLMs)的最新进展通过思维链(Chain-of-Thought, CoT)提示实现了强大的推理能力,CoT提示可以逐步解决问题,但中间输出通常过于冗长,导致计算开销增加。我们提出了Sketch-of-Thought(SoT),这是一种提示框架,它将认知启发式推理范式与语言约束相结合,以减少token使用,同时保持推理准确性。SoT被设计为一种灵活的模块化方法,并实例化为三种范式——概念链、分块符号主义和专家词典——每种范式都针对不同的推理任务量身定制,并在测试时由轻量级路由模型动态选择。在跨越多个领域、语言和模态的18个推理数据集上,SoT实现了高达84%的token减少,而准确性损失最小。在数学和多跳推理等任务中,它甚至在缩短输出的同时提高了准确性。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)在使用Chain-of-Thought (CoT) 进行推理时,中间步骤输出过于冗长,导致计算成本过高的问题。现有的CoT方法虽然能够提升推理能力,但其冗余的表达方式限制了LLM的效率和可扩展性。
核心思路:论文的核心思路是借鉴认知科学中的“草图”概念,即人类在解决问题时并非总是进行详尽的思考,而是会先构建一个简略的思维框架或草图。SoT框架旨在引导LLM生成更简洁、更高效的中间推理步骤,从而在减少token使用的同时,保持甚至提升推理准确性。
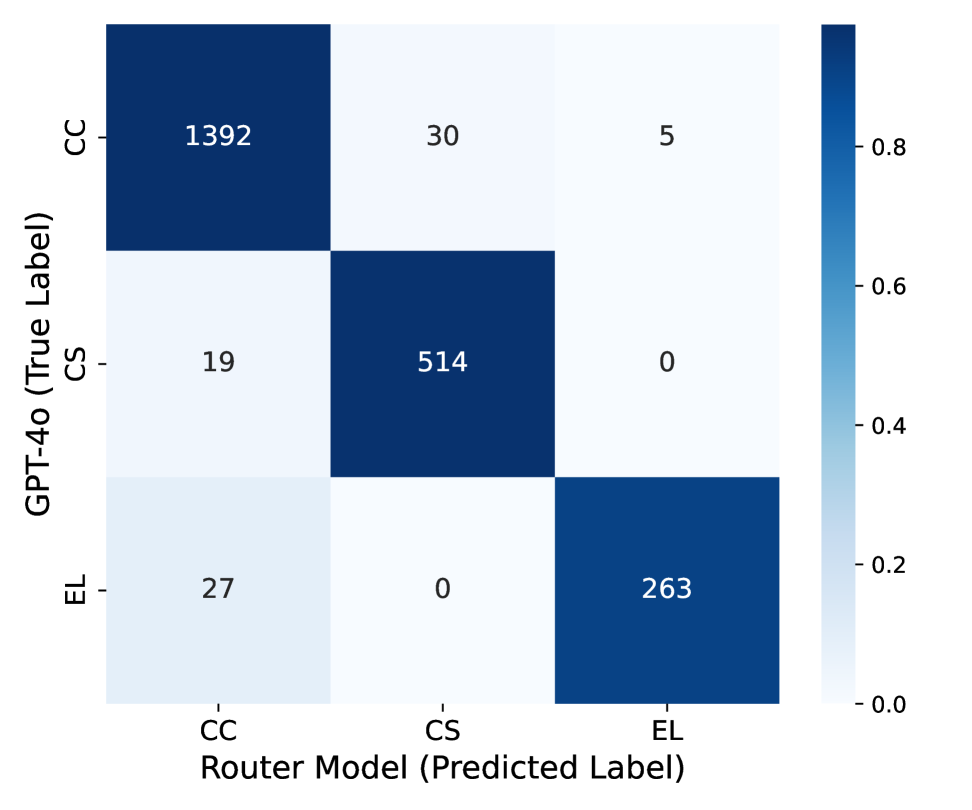
技术框架:SoT框架包含以下几个主要模块:1) 认知启发式范式库:包含多种认知启发式推理策略,如概念链、分块符号主义和专家词典。每种策略针对不同的推理任务设计。2) 轻量级路由模型:根据输入问题的特点,动态选择最合适的认知启发式范式。3) 语言约束模块:通过提示工程等手段,约束LLM生成简洁的输出。整体流程是,给定一个推理问题,路由模型选择合适的范式,然后LLM在该范式的指导下生成精简的推理步骤,最终得到答案。
关键创新:SoT的关键创新在于将认知科学的理论与LLM的推理过程相结合,提出了一种新的提示框架。与传统的CoT方法相比,SoT不是简单地让LLM生成详细的推理过程,而是引导其构建一个精简的“草图”,从而减少了token的使用。此外,动态路由机制使得SoT能够根据不同的任务自适应地选择合适的推理策略。
关键设计:论文中,三种认知启发式范式是关键设计。概念链通过连接关键概念来简化推理过程;分块符号主义使用符号来表示复杂的概念或关系,减少了文本的冗余;专家词典则利用特定领域的专业术语来提高推理的效率。路由模型的设计目标是轻量级和高效,可以使用简单的分类器或回归模型来实现。具体的参数设置和损失函数等细节在论文中可能没有详细描述,需要进一步查阅论文原文或相关代码。
🖼️ 关键图片

📊 实验亮点
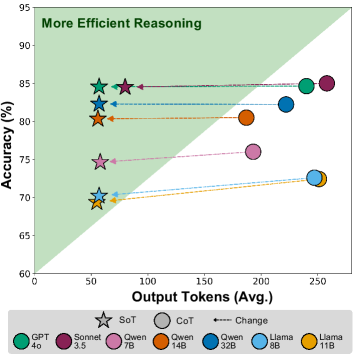
实验结果表明,SoT在18个推理数据集上实现了显著的token减少,最高可达84%,同时保持了推理准确性。在数学和多跳推理等任务中,SoT甚至在缩短输出的同时提高了准确性。例如,在某些数据集上,SoT的准确率比CoT提高了几个百分点,同时token使用量减少了50%以上。这些结果表明,SoT是一种有效的LLM推理优化方法。
🎯 应用场景
Sketch-of-Thought (SoT) 具有广泛的应用前景,可用于提升各种需要复杂推理的LLM应用效率,例如智能客服、自动编程、科学研究等。通过降低计算成本和提高推理速度,SoT 有助于在资源受限的环境中部署LLM,并促进LLM在实际场景中的大规模应用。未来,SoT 可以进一步扩展到更多领域和模态,并与其他优化技术相结合,以实现更高效、更智能的LLM推理。
📄 摘要(原文)
Recent advances in large language models (LLMs) have enabled strong reasoning capabilities through Chain-of-Thought (CoT) prompting, which elicits step-by-step problem solving, but often at the cost of excessive verbosity in intermediate outputs, leading to increased computational overhead. We propose Sketch-of-Thought (SoT), a prompting framework that integrates cognitively inspired reasoning paradigms with linguistic constraints to reduce token usage while preserving reasoning accuracy. SoT is designed as a flexible, modular approach and is instantiated with three paradigms--Conceptual Chaining, Chunked Symbolism, and Expert Lexicons--each tailored to distinct reasoning tasks and selected dynamically at test-time by a lightweight routing model. Across 18 reasoning datasets spanning multiple domains, languages, and modalities, SoT achieves token reductions of up to 84% with minimal accuracy loss. In tasks such as mathematical and multi-hop reasoning, it even improves accuracy while shortening outputs.