AdaSpec: Adaptive Speculative Decoding for Fast, SLO-Aware Large Language Model Serving
作者: Kaiyu Huang, Hao Wu, Zhubo Shi, Han Zou, Minchen Yu, Qingjiang Shi
分类: cs.CL
发布日期: 2025-03-07 (更新: 2026-01-12)
备注: This paper is accepted by ACM SoCC 2025
期刊: In ACM Symposium on Cloud Computing (SoCC '25), November 19-21, 2025, Online, USA
🔗 代码/项目: GITHUB
💡 一句话要点
AdaSpec:自适应推测解码,加速LLM服务并满足SLO
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 推测解码 服务等级目标 自适应策略 低延迟推理
📋 核心要点
- 现有推测解码方法难以适应动态工作负载和系统环境,导致性能下降和违反服务等级目标(SLO)。
- AdaSpec通过理论模型分析和预测不同场景下推测策略的效率,动态调整推测策略以适应实时负载。
- 实验表明,AdaSpec在满足SLO的同时,相比现有技术实现了高达66%的推理速度提升。
📝 摘要(中文)
云端大型语言模型(LLM)服务在实现低推理延迟和满足服务等级目标(SLO)方面面临挑战,尤其是在动态请求模式下。推测解码通过利用轻量级模型进行草稿生成,并使用LLM进行验证,成为加速LLM推理的一种有效技术。然而,现有的推测解码解决方案通常无法适应波动的工作负载和动态系统环境,导致性能下降和SLO违规。本文提出了AdaSpec,一个高效的LLM推理系统,可以根据实时请求负载和系统配置动态调整推测策略。AdaSpec提出了一个理论模型来分析和预测不同场景下推测策略的效率。此外,它还实现了智能草稿和验证算法,以最大限度地提高性能,同时确保高SLO达成率。在真实LLM服务跟踪上的实验结果表明,AdaSpec始终满足SLO,并实现了显著的性能提升,与最先进的推测推理系统相比,速度提高了高达66%。源代码已在https://github.com/cerebellumking/AdaSpec公开。
🔬 方法详解
问题定义:论文旨在解决云端LLM服务中,现有推测解码方法无法有效适应动态请求负载和系统环境,导致推理延迟高、难以满足服务等级目标(SLO)的问题。现有方法的痛点在于推测策略是静态的,无法根据实际情况进行调整,导致效率低下甚至性能下降。
核心思路:AdaSpec的核心思路是根据实时请求负载和系统配置,动态地调整推测策略。通过建立理论模型来分析和预测不同推测策略在不同场景下的效率,从而选择最优的推测策略。这种自适应的方法能够更好地应对动态变化的环境,提高推理效率并保证SLO。
技术框架:AdaSpec的整体框架包含以下几个主要模块:1) 负载监控模块:实时监控请求负载和系统资源利用率。2) 策略评估模块:基于理论模型,评估不同推测策略的效率。3) 策略选择模块:根据策略评估结果,选择最优的推测策略。4) 推测解码模块:采用选定的推测策略进行LLM推理。5) SLO监控模块:实时监控SLO达成情况,并根据需要调整推测策略。
关键创新:AdaSpec最重要的技术创新点在于其自适应的推测策略选择机制。与现有方法采用静态推测策略不同,AdaSpec能够根据实时环境动态调整推测策略,从而更好地适应动态变化的环境。此外,AdaSpec提出的理论模型能够准确地预测不同推测策略的效率,为策略选择提供了理论依据。
关键设计:AdaSpec的关键设计包括:1) 理论模型:用于分析和预测不同推测策略的效率,模型考虑了请求负载、系统资源、模型大小等因素。2) 策略选择算法:根据理论模型的预测结果,选择最优的推测策略,算法需要权衡推理速度和SLO达成率。3) 智能草稿和验证算法:优化草稿模型的生成和LLM的验证过程,以提高推测解码的效率。
🖼️ 关键图片
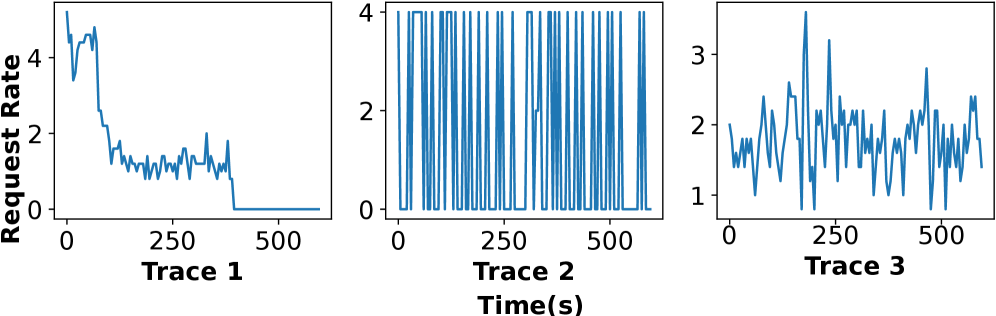
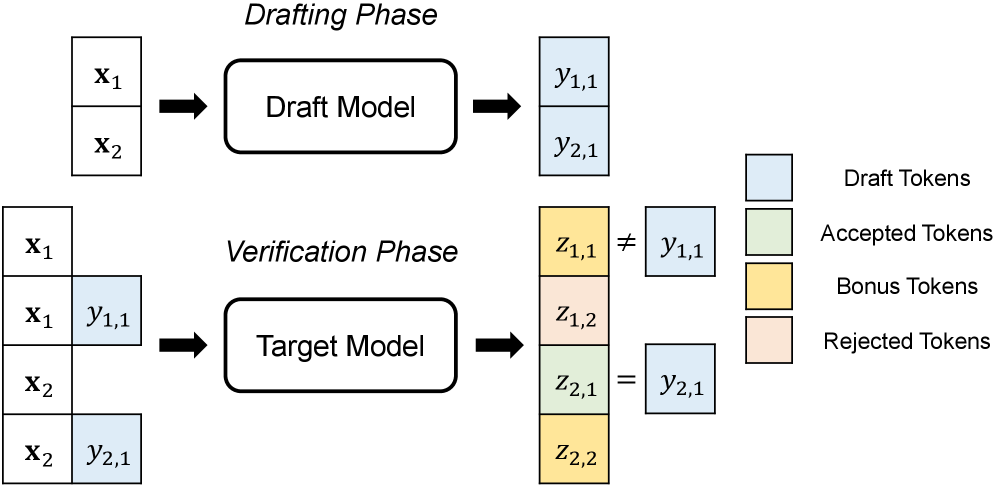
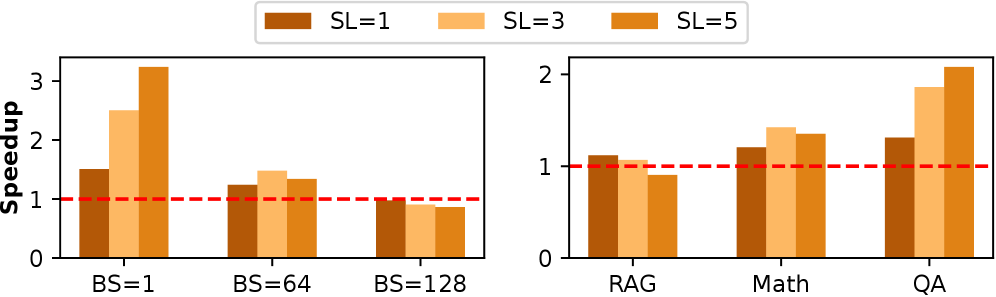
📊 实验亮点
实验结果表明,AdaSpec在真实LLM服务跟踪上始终满足SLO,并实现了显著的性能提升。与最先进的推测推理系统相比,AdaSpec的速度提高了高达66%。这些结果验证了AdaSpec的有效性和优越性,表明其在实际应用中具有很大的潜力。
🎯 应用场景
AdaSpec可应用于各种云端LLM服务,例如智能客服、文本生成、机器翻译等。通过自适应的推测解码,可以显著降低推理延迟,提高服务质量,并更好地满足用户的需求。该研究对于提升LLM服务的效率和用户体验具有重要的实际价值,并可能推动LLM在更多领域的应用。
📄 摘要(原文)
Cloud-based Large Language Model (LLM) services often face challenges in achieving low inference latency and meeting Service Level Objectives (SLOs) under dynamic request patterns. Speculative decoding, which exploits lightweight models for drafting and LLMs for verification, has emerged as a compelling technique to accelerate LLM inference. However, existing speculative decoding solutions often fail to adapt to fluctuating workloads and dynamic system environments, resulting in impaired performance and SLO violations. In this paper, we introduce AdaSpec, an efficient LLM inference system that dynamically adjusts speculative strategies according to real-time request loads and system configurations. AdaSpec proposes a theoretical model to analyze and predict the efficiency of speculative strategies across diverse scenarios. Additionally, it implements intelligent drafting and verification algorithms to maximize performance while ensuring high SLO attainment. Experimental results on real-world LLM service traces demonstrate that AdaSpec consistently meets SLOs and achieves substantial performance improvements, delivering up to 66% speedup compared to state-of-the-art speculative inference systems. The source code is publicly available at https://github.com/cerebellumking/AdaSpec