S2S-Arena, Evaluating Speech2Speech Protocols on Instruction Following with Paralinguistic Information
作者: Feng Jiang, Zhiyu Lin, Fan Bu, Yuhao Du, Benyou Wang, Haizhou Li
分类: cs.CL, cs.SD, eess.AS
发布日期: 2025-03-07
💡 一句话要点
提出S2S-Arena:一个评估语音到语音模型指令跟随能力及副语言信息的基准
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 语音到语音 指令跟随 副语言信息 基准测试 人工评估
📋 核心要点
- 现有语音到语音模型评估缺乏对副语言信息的考量,无法全面评估模型在真实场景下的表现。
- S2S-Arena基准通过融合TTS和现场录音,构建包含副语言信息的语音数据集,更贴近实际应用。
- 实验表明,级联模型优于联合训练模型,且副语言信息的生成仍是语音模型面临的挑战。
📝 摘要(中文)
大型语言模型(LLMs)的快速发展使语音模型备受关注,特别是支持语音输入和输出的语音到语音(S2S)协议。然而,现有的评估这些模型指令跟随能力的基准主要采用自动的基于文本的评估器,缺乏对语音理解和生成中副语言信息的考虑。为了解决这些问题,我们引入了S2S-Arena,这是一个新颖的竞技场式S2S基准,用于评估真实世界任务中语音输入和语音输出的指令跟随能力以及副语言信息。我们设计了154个融合了TTS和现场录音的样本,涵盖四个领域和21个任务,并以竞技场式的方式手动评估了现有的流行语音模型。实验结果表明:(1)除了GPT-4o的卓越性能外,级联ASR、LLM和TTS的语音模型在文本-语音对齐后优于联合训练的语音到语音协议模型;(2)考虑到副语言信息,语音模型的知识主要取决于LLM骨干,其多语言支持受到语音模块的限制;(3)优秀的语音模型已经可以理解语音输入中的副语言信息,但生成具有适当副语言信息的音频仍然是一个挑战。
🔬 方法详解
问题定义:现有语音到语音(S2S)模型的评估主要依赖于文本评估指标,忽略了语音中包含的丰富的副语言信息(如情感、语调等)。这导致评估结果无法真实反映模型在实际应用中的表现,尤其是在需要理解和生成带有情感色彩的语音指令时。现有方法的痛点在于无法有效评估模型对副语言信息的处理能力。
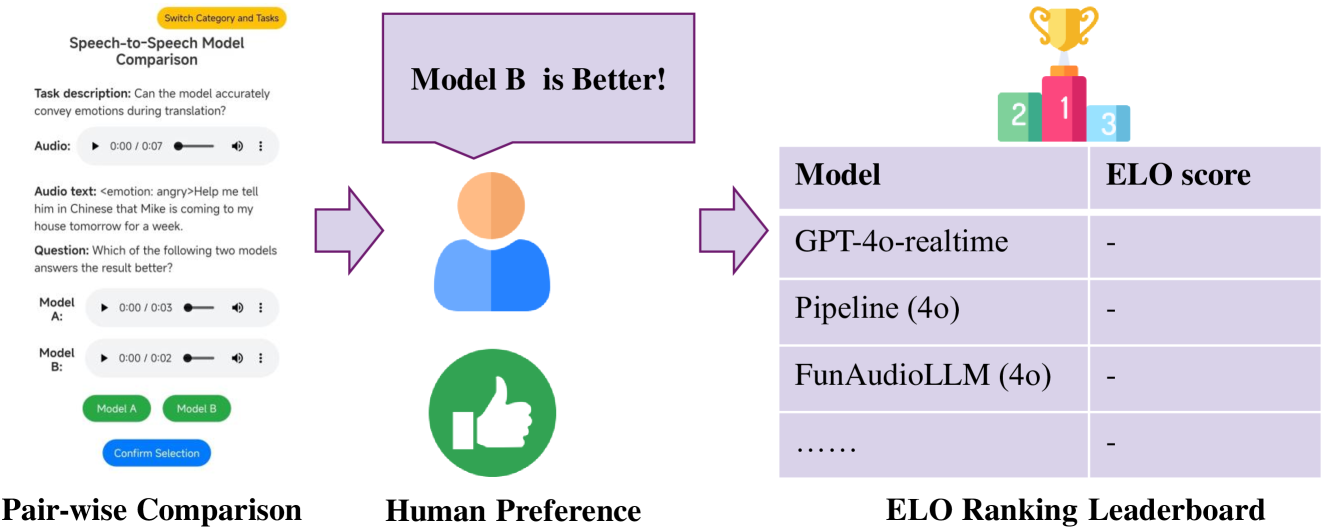
核心思路:S2S-Arena的核心思路是构建一个包含副语言信息的语音数据集,并采用人工评估的方式,更全面地评估S2S模型在指令跟随和副语言信息处理方面的能力。通过引入真实录音和TTS合成语音的融合,模拟真实场景,从而更准确地评估模型的性能。
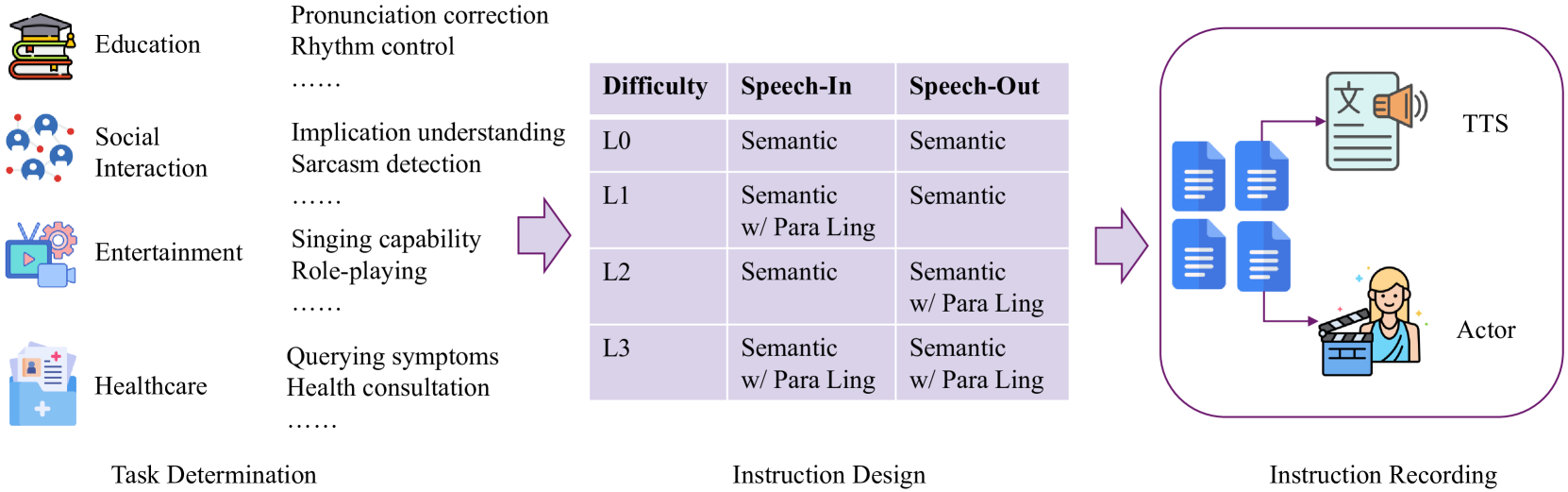
技术框架:S2S-Arena的整体框架包括以下几个主要部分:1) 数据集构建:收集并标注包含副语言信息的语音数据,包括真实录音和TTS合成语音。2) 任务设计:设计一系列需要模型理解并执行的指令跟随任务,涵盖多个领域。3) 模型评估:采用竞技场式的人工评估方法,比较不同模型在指令跟随和副语言信息处理方面的表现。4) 结果分析:分析评估结果,揭示不同模型在副语言信息处理方面的优势和不足。
关键创新:S2S-Arena最重要的技术创新点在于其对副语言信息的关注和人工评估方法的引入。与以往基于文本评估的基准不同,S2S-Arena更注重模型对语音中情感、语调等信息的理解和生成能力。人工评估能够更准确地评估模型在真实场景下的表现,避免了自动评估指标的局限性。
关键设计:S2S-Arena的关键设计包括:1) 数据集的构建,融合了TTS和真人录音,保证了数据的多样性和真实性。2) 任务的设计,涵盖了多个领域和多种类型的指令,能够全面评估模型的指令跟随能力。3) 评估方式,采用人工评估,能够更准确地评估模型对副语言信息的处理能力。4) 样本数量:154个样本,覆盖四个领域和21个任务。
🖼️ 关键图片

📊 实验亮点
实验结果表明,级联的ASR、LLM和TTS模型在文本-语音对齐后,性能优于联合训练的S2S模型。同时,研究发现优秀的语音模型已经可以理解语音输入中的副语言信息,但生成具有适当副语言信息的音频仍然是一个挑战。GPT-4o 在该基准上表现出卓越的性能。
🎯 应用场景
S2S-Arena的研究成果可应用于智能助手、语音交互机器人、情感语音合成等领域。通过提升模型对副语言信息的理解和生成能力,可以使语音交互更加自然、流畅和富有情感,从而改善用户体验,并为更高级的人机交互应用奠定基础。
📄 摘要(原文)
The rapid development of large language models (LLMs) has brought significant attention to speech models, particularly recent progress in speech2speech protocols supporting speech input and output. However, the existing benchmarks adopt automatic text-based evaluators for evaluating the instruction following ability of these models lack consideration for paralinguistic information in both speech understanding and generation. To address these issues, we introduce S2S-Arena, a novel arena-style S2S benchmark that evaluates instruction-following capabilities with paralinguistic information in both speech-in and speech-out across real-world tasks. We design 154 samples that fused TTS and live recordings in four domains with 21 tasks and manually evaluate existing popular speech models in an arena-style manner. The experimental results show that: (1) in addition to the superior performance of GPT-4o, the speech model of cascaded ASR, LLM, and TTS outperforms the jointly trained model after text-speech alignment in speech2speech protocols; (2) considering paralinguistic information, the knowledgeability of the speech model mainly depends on the LLM backbone, and the multilingual support of that is limited by the speech module; (3) excellent speech models can already understand the paralinguistic information in speech input, but generating appropriate audio with paralinguistic information is still a challenge.