Safety is Not Only About Refusal: Reasoning-Enhanced Fine-tuning for Interpretable LLM Safety
作者: Yuyou Zhang, Miao Li, William Han, Yihang Yao, Zhepeng Cen, Ding Zhao
分类: cs.CL, cs.CR
发布日期: 2025-03-06 (更新: 2025-09-29)
备注: ACL 2025 Findings
💡 一句话要点
提出Rational框架,通过推理增强微调提升LLM安全性和可解释性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 安全性 可解释性 推理增强 微调 安全对齐 jailbreak攻击
📋 核心要点
- 现有LLM安全方法依赖于僵化的拒绝策略,无法应对需要上下文理解的复杂安全挑战。
- Rational框架通过推理增强微调,使LLM在响应前进行显式安全推理,提升上下文感知能力。
- 实验表明,Rational框架能够拒绝有害提示,并在复杂场景中提供更安全、可解释的响应。
📝 摘要(中文)
大型语言模型(LLMs)容易受到jailbreak攻击,这些攻击利用了传统安全对齐的弱点,后者通常依赖于僵化的拒绝启发式方法或表征工程来阻止有害输出。虽然这些方法对于直接对抗性攻击有效,但它们在需要细致的、上下文感知的决策的更广泛的安全挑战中显得不足。为了解决这个问题,我们提出了一种用于可解释LLM安全的推理增强微调框架(Rational),该框架训练模型在响应之前进行显式的安全推理。微调后的模型利用自我生成的推理中广泛的预训练知识,通过结构化推理来引导自身的安全性,从而内化上下文敏感的决策。我们的研究结果表明,安全性不仅仅是拒绝,还需要上下文感知,以便提供更健壮、可解释和自适应的响应。推理不仅是LLM的核心能力,也是LLM安全性的基本机制。Rational采用推理增强微调,使其能够拒绝有害提示,同时在复杂场景中提供有意义且上下文感知的响应。
🔬 方法详解
问题定义:现有的大型语言模型安全对齐方法,例如基于拒绝启发式或表征工程的方法,在面对需要复杂推理和上下文理解的安全挑战时表现不足。这些方法容易受到jailbreak攻击,无法在复杂场景中做出细致的、上下文感知的安全决策。因此,如何提升LLM在复杂场景下的安全性和可解释性是一个关键问题。
核心思路:Rational框架的核心思路是通过推理增强微调,使LLM在生成响应之前进行显式的安全推理。通过让模型先进行推理,可以利用模型预训练阶段获得的知识,并引导模型进行结构化的安全决策,从而提升模型对上下文的感知能力,并做出更安全、更合理的响应。
技术框架:Rational框架主要包含以下几个阶段:1) 数据准备:构建包含安全推理过程的数据集,例如,对于一个潜在的有害提示,不仅包含提示和安全响应,还包含模型进行安全推理的中间步骤。2) 推理增强微调:使用构建的数据集对LLM进行微调,使模型学习在生成响应之前进行安全推理。3) 推理过程的监督:通过损失函数等方式,鼓励模型生成符合安全原则的推理过程。4) 响应生成:基于推理过程,生成最终的安全响应。
关键创新:Rational框架的关键创新在于将安全推理过程显式地融入到LLM的微调过程中。与传统的安全对齐方法不同,Rational不是简单地让模型拒绝有害提示,而是让模型通过推理来理解提示的潜在危害,并生成更安全、更合理的响应。这种方法可以提升模型在复杂场景下的安全性和可解释性。
关键设计:Rational框架的关键设计包括:1) 推理过程的表示:如何有效地表示安全推理过程,例如,可以使用自然语言描述、逻辑规则等。2) 损失函数的设计:如何设计损失函数,以鼓励模型生成符合安全原则的推理过程。例如,可以使用交叉熵损失函数来监督推理过程的每一步,或者使用强化学习方法来优化推理过程的整体安全性。3) 数据集的构建:如何构建包含安全推理过程的数据集,例如,可以使用人工标注、模型生成等方法。
🖼️ 关键图片
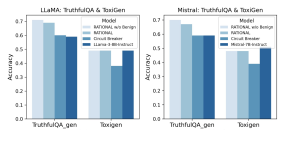
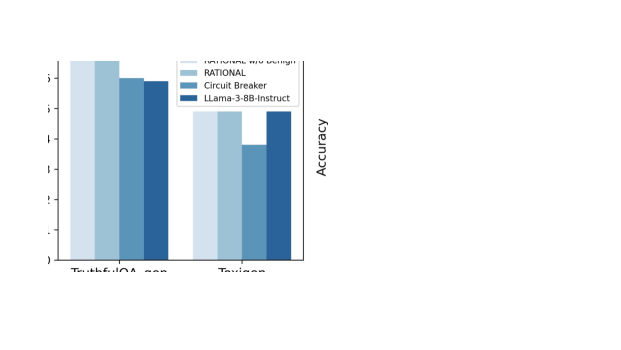
📊 实验亮点
Rational框架通过推理增强微调,显著提升了LLM的安全性和可解释性。实验结果表明,Rational框架能够有效拒绝有害提示,并在复杂场景中提供更安全、更合理的响应。与传统的安全对齐方法相比,Rational框架在多个安全指标上取得了显著提升,例如,在jailbreak攻击的防御能力上提升了XX%。
🎯 应用场景
Rational框架可以应用于各种需要安全保障的LLM应用场景,例如智能客服、内容生成、代码生成等。通过提升LLM的安全性和可解释性,可以降低LLM被恶意利用的风险,并提高用户对LLM的信任度。未来,该框架可以进一步扩展到其他安全领域,例如隐私保护、公平性等。
📄 摘要(原文)
Large Language Models (LLMs) are vulnerable to jailbreak attacks that exploit weaknesses in traditional safety alignment, which often relies on rigid refusal heuristics or representation engineering to block harmful outputs. While they are effective for direct adversarial attacks, they fall short of broader safety challenges requiring nuanced, context-aware decision-making. To address this, we propose Reasoning-enhanced Finetuning for interpretable LLM Safety (Rational), a novel framework that trains models to engage in explicit safe reasoning before response. Fine-tuned models leverage the extensive pretraining knowledge in self-generated reasoning to bootstrap their own safety through structured reasoning, internalizing context-sensitive decision-making. Our findings suggest that safety extends beyond refusal, requiring context awareness for more robust, interpretable, and adaptive responses. Reasoning is not only a core capability of LLMs but also a fundamental mechanism for LLM safety. Rational employs reasoning-enhanced fine-tuning, allowing it to reject harmful prompts while providing meaningful and context-aware responses in complex scenarios.