DB-Explore: Automated Database Exploration and Instruction Synthesis for Text-to-SQL
作者: Haoyuan Ma, Yongliang Shen, Hengwei Liu, Wenqi Zhang, Haolei Xu, Qiuying Peng, Jun Wang, Weiming Lu
分类: cs.CL
发布日期: 2025-03-06 (更新: 2025-05-21)
💡 一句话要点
DB-Explore:通过数据库探索与指令合成增强Text-to-SQL模型的数据库理解能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: Text-to-SQL 数据库探索 指令合成 大型语言模型 知识蒸馏
📋 核心要点
- 现有Text-to-SQL系统在处理复杂数据库结构和领域特定查询时表现不佳,主要原因是它们侧重于逻辑推理和SQL语法,而忽略了对数据库的全面理解。
- DB-Explore通过自动探索和指令合成,系统地将LLMs与数据库知识对齐。它构建数据库图,挖掘结构模式和语义知识,并合成指令以微调LLMs。
- 实验结果表明,DB-Explore在SPIDER和BIRD基准测试上取得了显著的性能提升,并且基于Qwen2.5-Coder-7B的实现超越了多个GPT-4驱动的系统。
📝 摘要(中文)
本文提出了一种名为DB-Explore的新框架,旨在通过自动探索和指令合成,使大型语言模型(LLMs)更好地理解数据库知识,从而提升Text-to-SQL系统的性能。DB-Explore构建数据库图来捕获复杂的关系模式,利用GPT-4系统地挖掘结构模式和语义知识,并合成指令以提炼这些知识,从而高效地微调LLMs。该框架通过多样化的抽样策略和自动指令生成,实现了对数据库的全面理解,弥合了数据库结构和语言模型之间的差距。在SPIDER和BIRD基准测试上的实验验证了DB-Explore的有效性,在BIRD上实现了67.0%的执行准确率,在SPIDER上实现了87.8%的执行准确率。基于Qwen2.5-Coder-7B的开源实现以极低的计算成本实现了最先进的结果,优于几种基于GPT-4的Text-to-SQL系统。
🔬 方法详解
问题定义:现有的Text-to-SQL系统,尤其是基于大型语言模型的系统,在处理复杂数据库和领域相关的查询时,性能会显著下降。主要原因是这些系统更关注SQL语法的正确性和逻辑推理能力,而忽略了对数据库模式和语义的深入理解,导致无法准确地将自然语言查询映射到正确的SQL语句。
核心思路:DB-Explore的核心思路是通过自动化的数据库探索和指令合成,让LLM能够更好地理解数据库的结构和语义信息。通过构建数据库图,并利用GPT-4等大型语言模型来挖掘数据库中的模式和知识,然后将这些知识提炼成指令,用于微调LLM,从而提高其Text-to-SQL的能力。这种方法的核心在于将数据库理解作为Text-to-SQL任务的一个重要组成部分,而不是仅仅依赖于LLM的通用知识。
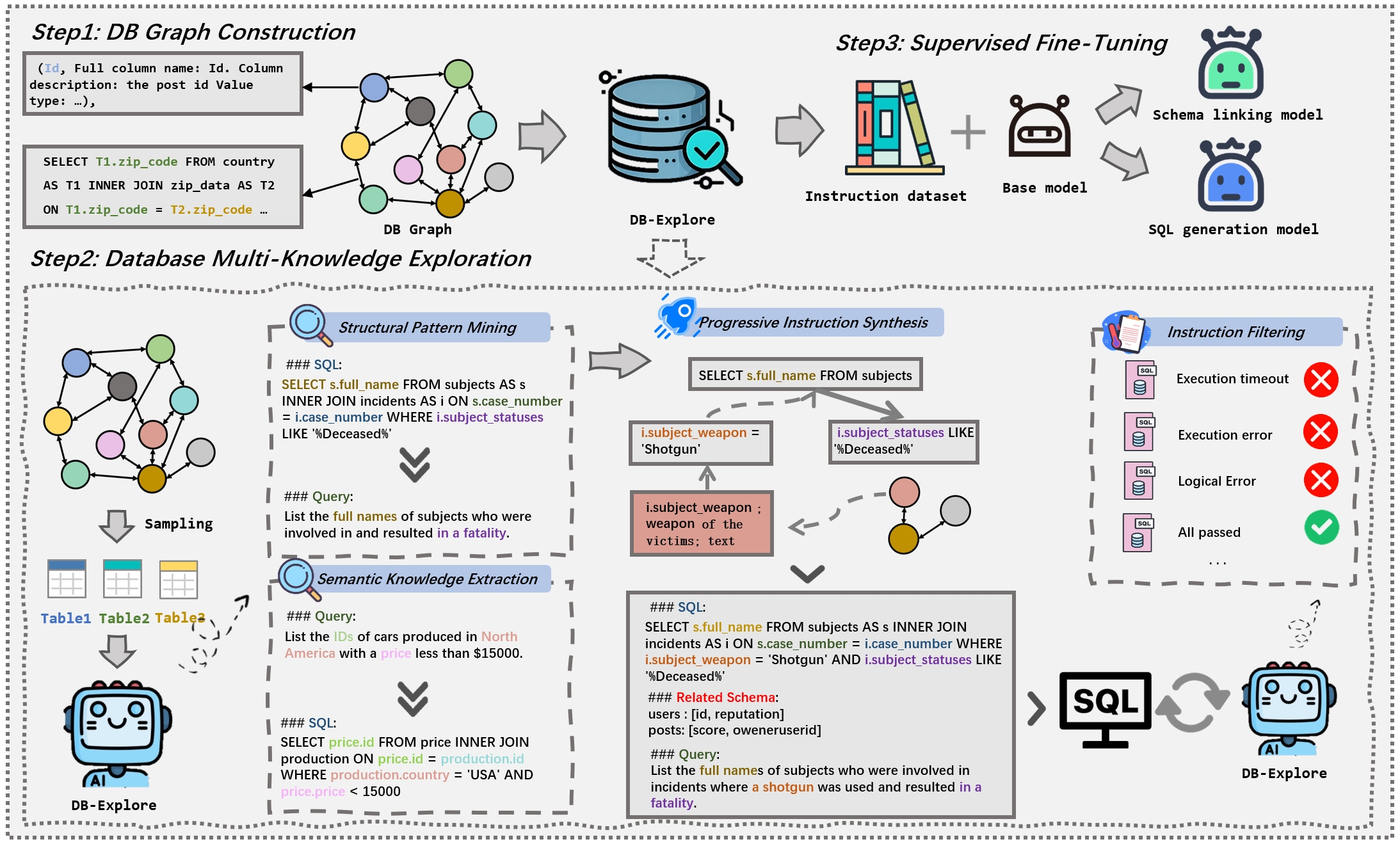
技术框架:DB-Explore框架主要包含以下几个阶段:1) 数据库图构建:将数据库的schema信息转换为图结构,节点表示表和列,边表示表之间的关系。2) 知识挖掘:利用GPT-4等LLM,基于数据库图,自动挖掘数据库中的结构模式和语义知识。例如,可以生成关于表之间关系的描述,或者关于列的语义信息的描述。3) 指令合成:将挖掘到的知识转化为指令,用于指导LLM进行微调。这些指令可以是问答形式,也可以是其他形式,目的是让LLM学习如何理解数据库的结构和语义。4) 模型微调:使用合成的指令对LLM进行微调,使其能够更好地理解数据库,从而提高Text-to-SQL的准确率。
关键创新:DB-Explore的关键创新在于它将数据库理解作为Text-to-SQL任务的一个核心环节,并提出了一个自动化的框架来实现这一目标。与以往的方法相比,DB-Explore不再仅仅依赖于LLM的通用知识,而是通过自动化的探索和指令合成,让LLM能够学习到特定数据库的知识,从而提高Text-to-SQL的准确率。此外,DB-Explore还提出了一种新的指令合成方法,可以有效地将数据库知识转化为LLM可以理解的形式。
关键设计:DB-Explore的关键设计包括:1) 数据库图的构建方式,如何有效地表示数据库的schema信息。2) 知识挖掘策略,如何利用LLM来挖掘数据库中的结构模式和语义知识。3) 指令合成方法,如何将挖掘到的知识转化为LLM可以理解的形式。4) 微调策略,如何有效地利用合成的指令来微调LLM。论文中可能还涉及一些超参数的设置,例如学习率、batch size等,这些参数的选择也会影响最终的性能。
🖼️ 关键图片
📊 实验亮点
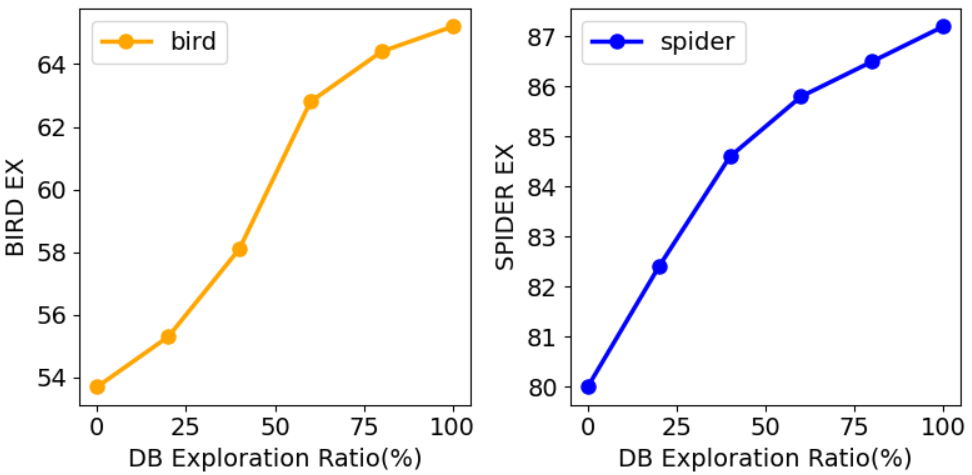
DB-Explore在SPIDER和BIRD基准测试上取得了显著的性能提升。在BIRD数据集上,DB-Explore实现了67.0%的执行准确率,在SPIDER数据集上实现了87.8%的执行准确率。更重要的是,基于Qwen2.5-Coder-7B的开源实现,DB-Explore以极低的计算成本超越了多个基于GPT-4的Text-to-SQL系统,展示了其高效性和实用性。
🎯 应用场景
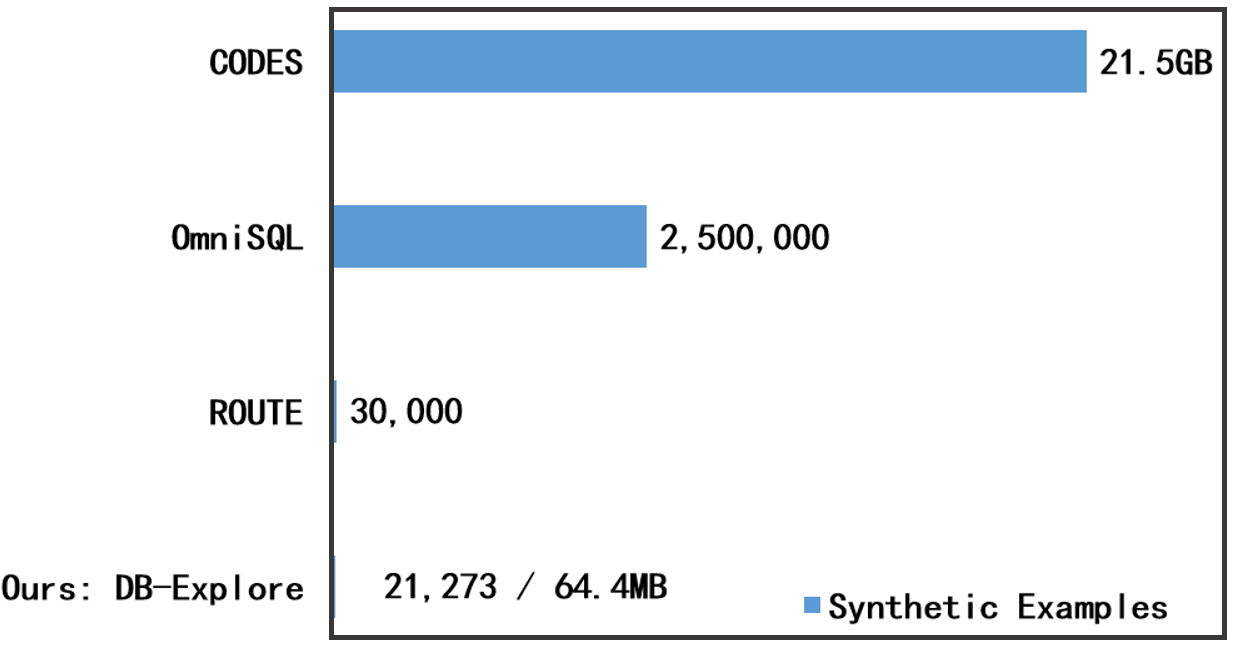
DB-Explore具有广泛的应用前景,可以应用于各种需要将自然语言查询转换为SQL语句的场景,例如智能客服、数据分析、商业智能等。通过自动化的数据库探索和指令合成,DB-Explore可以显著降低Text-to-SQL系统的开发成本,并提高其准确率和鲁棒性。未来,DB-Explore还可以扩展到其他类型的数据库和查询语言,例如NoSQL数据库和GraphQL。
📄 摘要(原文)
Recent text-to-SQL systems powered by large language models (LLMs) have demonstrated remarkable performance in translating natural language queries into SQL. However, these systems often struggle with complex database structures and domain-specific queries, as they primarily focus on enhancing logical reasoning and SQL syntax while overlooking the critical need for comprehensive database understanding. To address this limitation, we propose DB-Explore, a novel framework that systematically aligns LLMs with database knowledge through automated exploration and instruction synthesis. DB-Explore constructs database graphs to capture complex relational schemas, leverages GPT-4 to systematically mine structural patterns and semantic knowledge, and synthesizes instructions to distill this knowledge for efficient fine-tuning of LLMs. Our framework enables comprehensive database understanding through diverse sampling strategies and automated instruction generation, bridging the gap between database structures and language models. Experiments conducted on the SPIDER and BIRD benchmarks validate the effectiveness of DB-Explore, achieving an execution accuracy of 67.0% on BIRD and 87.8% on SPIDER. Notably, our open-source implementation based on Qwen2.5-Coder-7B achieves state-of-the-art results at minimal computational cost, outperforming several GPT-4-driven Text-to-SQL systems.