L1: Controlling How Long A Reasoning Model Thinks With Reinforcement Learning
作者: Pranjal Aggarwal, Sean Welleck
分类: cs.CL, cs.AI, cs.LG
发布日期: 2025-03-06 (更新: 2025-10-03)
备注: Accepted at COLM 2025
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
提出LCPO,通过强化学习控制推理语言模型的思考长度,实现计算成本与准确率的平衡。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 推理语言模型 思维链 长度控制 策略优化 计算成本 准确率 短推理模型
📋 核心要点
- 现有推理语言模型的思维链长度不可控,无法根据需求分配计算资源以达到期望的性能水平。
- 提出长度控制策略优化(LCPO),通过强化学习优化模型准确性,并使其满足用户指定的长度约束。
- 实验表明,LCPO训练的L1模型能在多种任务上平衡计算成本和准确性,且短推理模型性能优于GPT-4o。
📝 摘要(中文)
推理语言模型可以通过“思考更长时间”,即生成更长的思维链序列,来提高测试时的性能,但这会消耗更多计算资源且推理链长度不可控。为了解决这个问题,我们提出了长度控制策略优化(LCPO),这是一种简单的强化学习方法,可以优化模型的准确性并使其满足用户指定的长度约束。我们使用LCPO训练了L1模型,该模型可以生成满足提示中给出的长度约束的输出。L1的长度控制允许在各种任务上平滑地权衡计算成本和准确性,并且优于最先进的S1长度控制方法。此外,我们还发现了使用LCPO训练的模型中一种意想不到的短思维链能力。具体来说,使用LCPO,我们得到了短推理模型(SRM),它表现出与完整长度推理模型相似的推理模式,但可以生成与非推理模型相当的CoT长度。它们表现出显着的性能提升,例如,我们的15亿参数L1模型在相同的推理长度下超过了GPT-4o。总的来说,LCPO能够精确控制推理长度,从而可以对测试时计算和准确性进行细粒度的分配。我们发布了代码和模型。
🔬 方法详解
问题定义:论文旨在解决推理语言模型中思维链长度不可控的问题。现有方法无法根据用户需求调整推理步数,导致计算资源浪费或性能不足。用户无法根据实际情况在计算成本和准确率之间进行权衡。
核心思路:论文的核心思路是利用强化学习,训练一个策略来控制推理语言模型生成的思维链长度。通过奖励模型在满足长度约束的同时提高准确率,从而实现对推理过程的精确控制。这种方法允许用户根据需求指定推理长度,从而优化计算资源的使用。
技术框架:整体框架包括一个推理语言模型(Actor)和一个奖励模型(Reward)。Actor负责生成思维链,Reward根据生成的思维链的长度和准确率给出奖励信号。使用策略梯度算法(如PPO)更新Actor的参数,使其能够生成满足长度约束且准确率高的思维链。具体流程如下:1. 给定输入和长度约束,Actor生成思维链;2. Reward模型评估思维链的长度和准确率,给出奖励;3. 使用奖励信号更新Actor的策略。
关键创新:最重要的创新点在于将强化学习应用于控制推理语言模型的思维链长度。与现有方法相比,LCPO能够直接优化长度约束,从而实现更精确的控制。此外,论文还发现了通过LCPO训练得到的短推理模型(SRM)具有意想不到的性能提升,能够在较短的推理长度下达到甚至超过大型模型的性能。
关键设计:关键设计包括:1. 奖励函数的设计:奖励函数需要平衡长度约束和准确率。论文可能采用了加权和的方式,对长度偏差和准确率分别进行奖励或惩罚。2. 策略梯度算法的选择:论文选择了PPO算法,因为它具有较好的稳定性和收敛性。3. 模型架构:推理语言模型可以使用现有的预训练语言模型,如GPT系列。4. 训练数据:需要包含输入、期望输出和长度约束的数据集。
🖼️ 关键图片
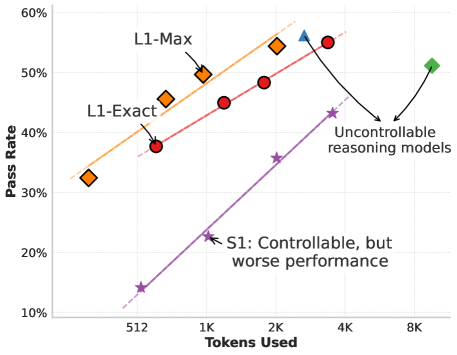

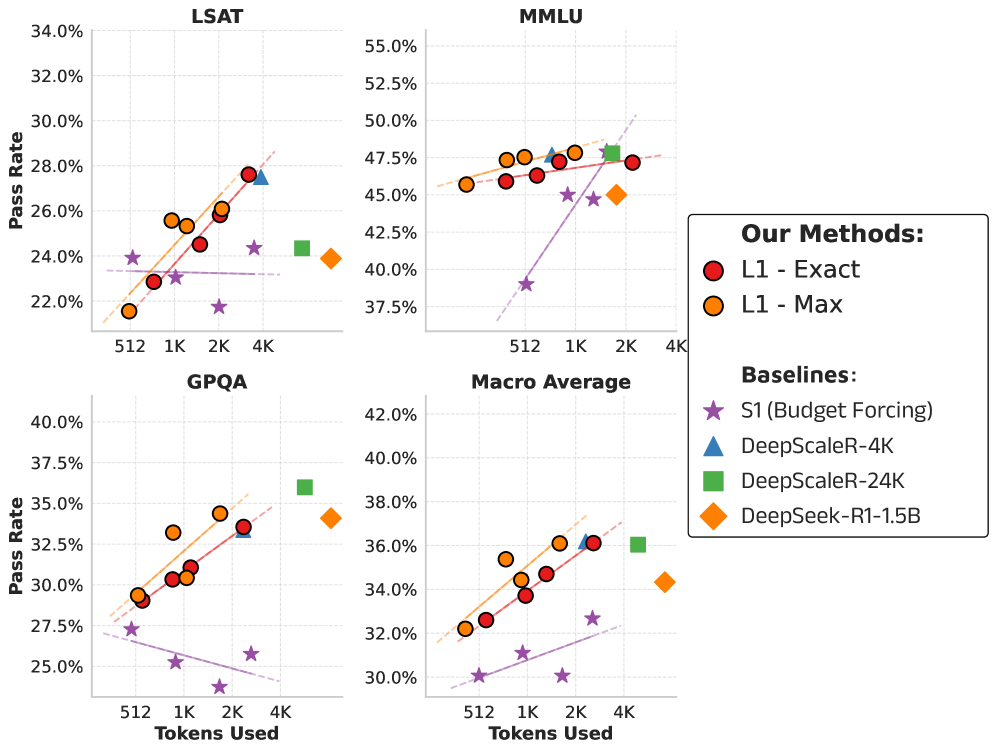
📊 实验亮点
实验结果表明,LCPO能够有效地控制推理语言模型的思维链长度,并在各种任务上实现了计算成本和准确率的平衡。例如,L1模型在满足长度约束的同时,优于最先进的S1方法。更令人惊讶的是,通过LCPO训练得到的短推理模型(SRM)在较短的推理长度下,性能甚至超过了GPT-4o,展示了LCPO在提高推理效率方面的巨大潜力。
🎯 应用场景
该研究成果可应用于各种需要权衡计算成本和准确率的场景,例如:资源受限的移动设备上的智能助手、需要快速响应的实时决策系统、以及对推理过程可解释性有要求的领域。通过控制推理长度,可以根据实际需求动态调整模型的性能和计算开销,提高资源利用率和用户体验。
📄 摘要(原文)
Reasoning language models have shown an uncanny ability to improve performance at test-time by ``thinking longer''-that is, by generating longer chain-of-thought sequences and hence using more compute. However, the length of their chain-of-thought reasoning is not controllable, making it impossible to allocate test-time compute to achieve a desired level of performance. We introduce Length Controlled Policy Optimization (LCPO), a simple reinforcement learning method that optimizes for accuracy and adherence to user-specified length constraints. We use LCPO to train L1, a reasoning language model that produces outputs satisfying a length constraint given in its prompt. L1's length control allows for smoothly trading off computational cost and accuracy on a wide range of tasks, and outperforms the state-of-the-art S1 method for length control. Furthermore, we uncover an unexpected short chain-of-thought capability in models trained with LCPO. Specifically, using LCPO we derive Short Reasoning Models (SRMs), that exhibit similar reasoning patterns as full-length reasoning models, but can generate CoT lengths comparable to non-reasoning models. They demonstrate significant performance gains, for instance, our 1.5B L1 model surpasses GPT-4o at equal reasoning lengths. Overall, LCPO enables precise control over reasoning length, allowing for fine-grained allocation of test-time compute and accuracy. We release code and models at https://www.cmu-l3.github.io/l1