UIPE: Enhancing LLM Unlearning by Removing Knowledge Related to Forgetting Targets
作者: Wenyu Wang, Mengqi Zhang, Xiaotian Ye, Zhaochun Ren, Zhumin Chen, Pengjie Ren
分类: cs.CL
发布日期: 2025-03-06
💡 一句话要点
UIPE:通过移除相关知识增强LLM的遗忘学习
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: LLM遗忘学习 知识移除 参数外推 有害信息消除 TOFU基准
📋 核心要点
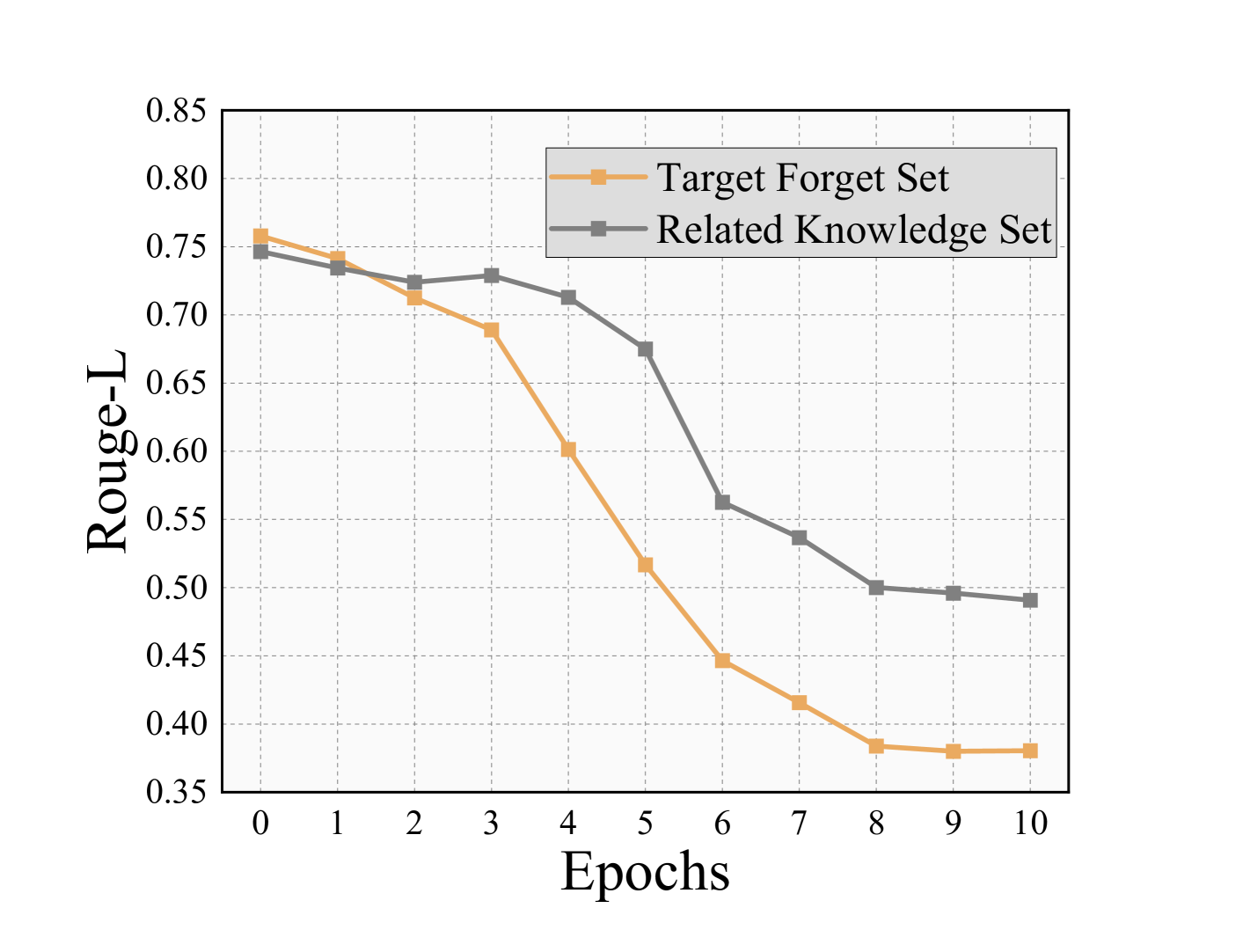
- 现有LLM遗忘学习方法忽略了逻辑相关知识对遗忘效果的影响,导致模型仍能通过推理重建目标内容。
- 论文提出UIPE方法,通过参数外推移除与遗忘目标高度相关的知识,从而增强遗忘学习效果。
- 实验结果表明,UIPE显著提升了主流LLM遗忘学习方法在TOFU基准上的性能表现。
📝 摘要(中文)
大型语言模型(LLMs)在海量数据集上训练时不可避免地会获得有害信息。LLM遗忘学习旨在消除这些有害信息的影响,同时保持模型的整体性能。现有的遗忘学习方法,以基于梯度上升的方法为代表,主要关注于遗忘目标数据,而忽略了逻辑相关知识对遗忘学习效果的关键影响。在本文中,通过理论和实验分析,我们首先证明了次优遗忘学习性能的一个关键原因是模型可以通过与逻辑相关的知识进行推理来重建目标内容。为了解决这个问题,我们提出了一种通过参数外推改进遗忘学习的方法(UIPE),该方法可以移除与遗忘目标高度相关的知识。实验结果表明,UIPE显著提高了各种主流LLM遗忘学习方法在TOFU基准上的性能。
🔬 方法详解
问题定义:论文旨在解决LLM遗忘学习中,由于模型可以通过逻辑相关的知识推理重建遗忘目标,导致遗忘效果不佳的问题。现有方法主要集中于直接遗忘目标数据,忽略了相关知识的影响,导致遗忘效果受限。
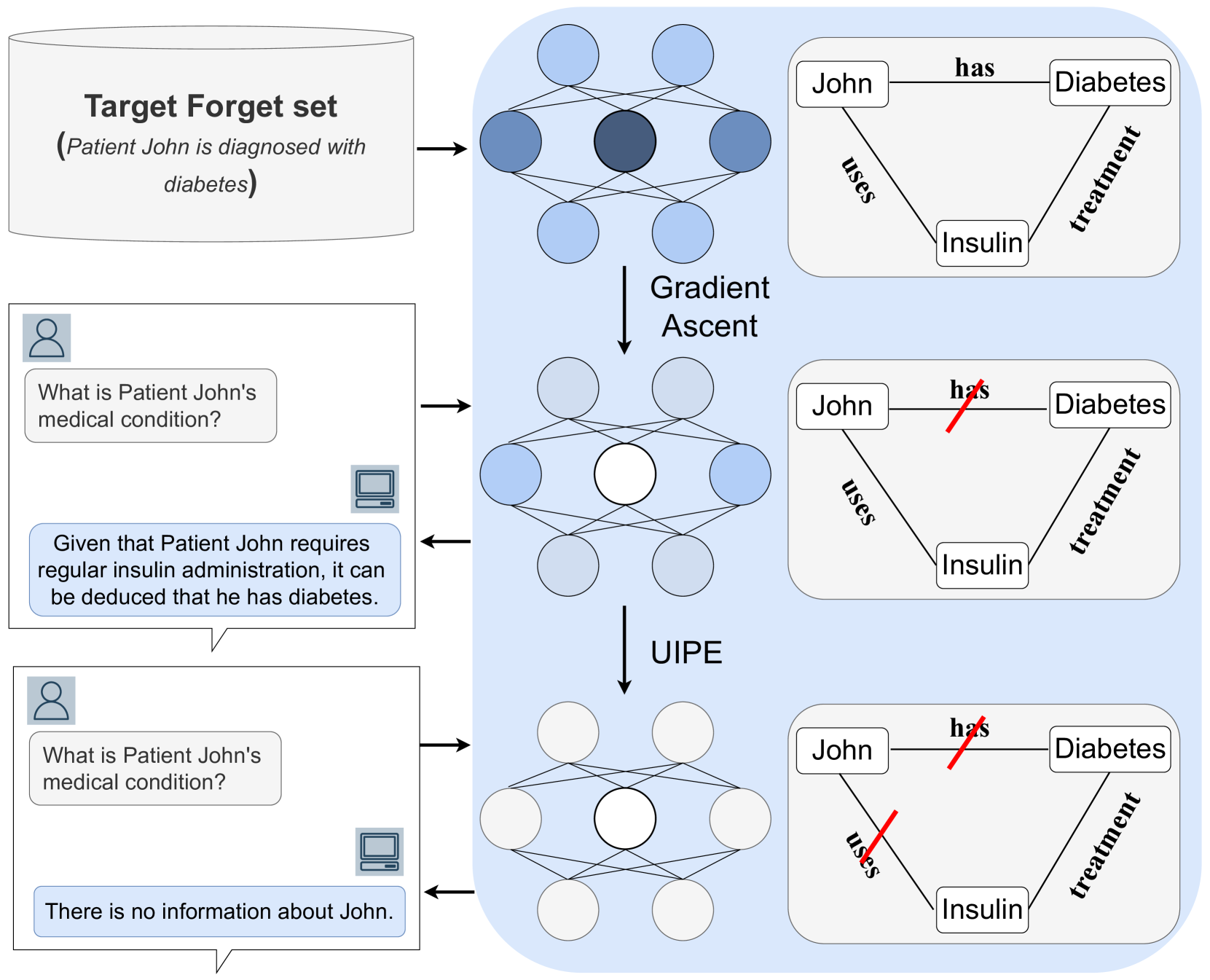
核心思路:论文的核心思路是通过移除与遗忘目标高度相关的知识来增强遗忘学习的效果。具体而言,通过识别并消除那些能够帮助模型重建遗忘目标的信息,从而从根本上阻止模型进行推理和重建。
技术框架:UIPE方法的核心在于参数外推。首先,确定需要遗忘的目标数据。然后,识别与该目标数据相关的知识。接着,通过参数外推技术,调整模型参数,使得模型不再能够利用这些相关知识来推断或重建遗忘目标。这个过程可以迭代进行,以进一步增强遗忘效果。
关键创新:UIPE的关键创新在于它不仅仅关注于直接遗忘目标数据,而是更加关注于移除与目标数据相关的知识。这种方法能够更彻底地消除有害信息的影响,并防止模型通过推理重新学习到这些信息。与现有方法相比,UIPE更加注重知识层面的遗忘,而不仅仅是数据层面的遗忘。
关键设计:UIPE方法中,参数外推的具体实现方式是关键。论文可能采用了某种形式的梯度上升或对抗训练,以最大化模型在遗忘目标上的损失,同时最小化在其他数据上的损失。具体的损失函数设计和优化算法的选择会直接影响到UIPE的性能。此外,如何有效地识别与遗忘目标相关的知识也是一个重要的设计考虑。
🖼️ 关键图片
📊 实验亮点
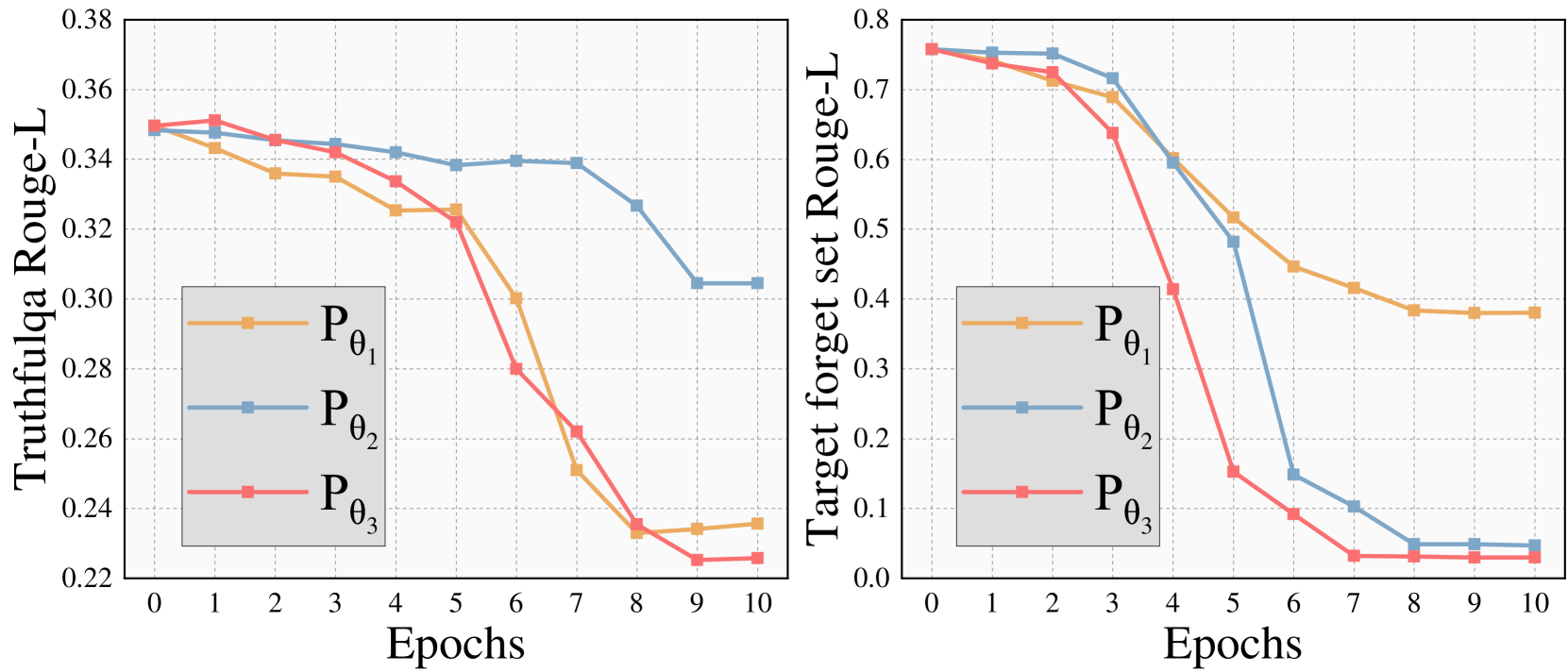
实验结果表明,UIPE方法显著提升了现有LLM遗忘学习方法在TOFU基准上的性能。具体而言,UIPE能够有效降低模型在遗忘目标上的准确率,同时保持模型在其他任务上的性能。相比于基线方法,UIPE在遗忘效果和模型性能之间取得了更好的平衡。
🎯 应用场景
该研究成果可应用于各种需要消除LLM中不良信息的场景,例如:移除模型中的偏见、审查不当内容、保护用户隐私等。通过更有效地遗忘有害信息,可以提升LLM的安全性和可靠性,使其更适用于各种实际应用,例如智能客服、内容生成、教育辅助等。
📄 摘要(原文)
Large Language Models (LLMs) inevitably acquire harmful information during training on massive datasets. LLM unlearning aims to eliminate the influence of such harmful information while maintaining the model's overall performance. Existing unlearning methods, represented by gradient ascent-based approaches, primarily focus on forgetting target data while overlooking the crucial impact of logically related knowledge on the effectiveness of unlearning. In this paper, through both theoretical and experimental analyses, we first demonstrate that a key reason for the suboptimal unlearning performance is that models can reconstruct the target content through reasoning with logically related knowledge. To address this issue, we propose Unlearning Improvement via Parameter Extrapolation (UIPE), a method that removes knowledge highly correlated with the forgetting targets. Experimental results show that UIPE significantly enhances the performance of various mainstream LLM unlearning methods on the TOFU benchmark.