Keeping Yourself is Important in Downstream Tuning Multimodal Large Language Model
作者: Wenke Huang, Jian Liang, Xianda Guo, Yiyang Fang, Guancheng Wan, Xuankun Rong, Chi Wen, Zekun Shi, Qingyun Li, Didi Zhu, Yanbiao Ma, Ke Liang, Bin Yang, He Li, Jiawei Shao, Mang Ye, Bo Du
分类: cs.CL, cs.AI
发布日期: 2025-03-06
🔗 代码/项目: GITHUB
💡 一句话要点
系统性评测多模态大语言模型微调策略,解决任务专精和知识遗忘问题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 微调策略 任务专精 知识遗忘 基准测试 选择性微调 增量微调 重参数化微调
📋 核心要点
- 现有MLLM微调方法在下游任务中存在任务专精和知识遗忘问题,限制了模型性能。
- 论文系统性地回顾并分类了MLLM微调方法,包括选择性、增量和重参数化微调三种范式。
- 通过基准测试,论文建立了标准化的评估分析和系统的微调原则,并指出了未来研究方向。
📝 摘要(中文)
多模态大语言模型(MLLMs)集成了视觉和语言推理能力,可以处理图像描述和视觉问答等复杂任务。虽然MLLMs展现了卓越的通用性,但在特定应用上的表现仍然受限。针对下游任务微调MLLMs面临两个关键挑战:任务专精,即预训练和目标数据集之间的分布差异限制了目标性能;以及开放世界稳定性,即灾难性遗忘会抹去模型的通用知识。本文系统地回顾了MLLM微调方法的最新进展,将其分为三种范式:(I)选择性微调,(II)增量微调,以及(III)重参数化微调。此外,本文还对这些微调策略在流行的MLLM架构和不同的下游任务上进行了基准测试,以建立标准化的评估分析和系统的微调原则。最后,本文强调了该领域中的几个开放性挑战,并提出了未来的研究方向。为了促进这个快速发展领域的持续进步,我们提供了一个公共存储库,持续跟踪相关进展:https://github.com/WenkeHuang/Awesome-MLLM-Tuning。
🔬 方法详解
问题定义:论文旨在解决多模态大语言模型(MLLMs)在下游任务微调过程中遇到的两个主要问题:一是“任务专精”,即模型在特定任务上微调后,性能提升的同时,对其他任务的泛化能力下降;二是“开放世界稳定性”,即模型在微调过程中容易发生灾难性遗忘,丢失了预训练阶段学到的通用知识。现有方法往往难以在提升特定任务性能的同时,保持模型的通用性和稳定性。
核心思路:论文的核心思路是对现有的MLLM微调方法进行系统性的分类、评估和分析,从而为选择合适的微调策略提供指导。通过对不同微调范式(选择性微调、增量微调和重参数化微调)的优缺点进行分析,帮助研究人员和开发者更好地理解各种方法的适用场景和潜在问题,从而在实际应用中做出更明智的选择。
技术框架:论文的技术框架主要包括三个部分:首先,对现有的MLLM微调方法进行文献综述,并将其归纳为三种范式;其次,构建一个基准测试平台,在不同的MLLM架构和下游任务上对这些微调策略进行评估;最后,对实验结果进行分析,总结出系统的微调原则,并指出该领域未来的研究方向。
关键创新:论文的关键创新在于对MLLM微调方法进行了系统性的分类和评估,并提出了相应的微调原则。与以往的研究相比,本文更加注重对不同微调策略的优缺点进行对比分析,从而为实际应用提供更具指导性的建议。此外,论文还提供了一个公共存储库,持续跟踪该领域的最新进展,为研究人员和开发者提供了一个便捷的资源平台。
关键设计:论文的关键设计包括:(1)对微调方法进行分类,形成清晰的知识体系;(2)构建全面的基准测试,覆盖多种MLLM架构和下游任务;(3)采用标准化的评估指标,对不同微调策略的性能进行客观比较;(4)提供开源代码和数据集,方便其他研究人员复现和扩展研究成果。
🖼️ 关键图片

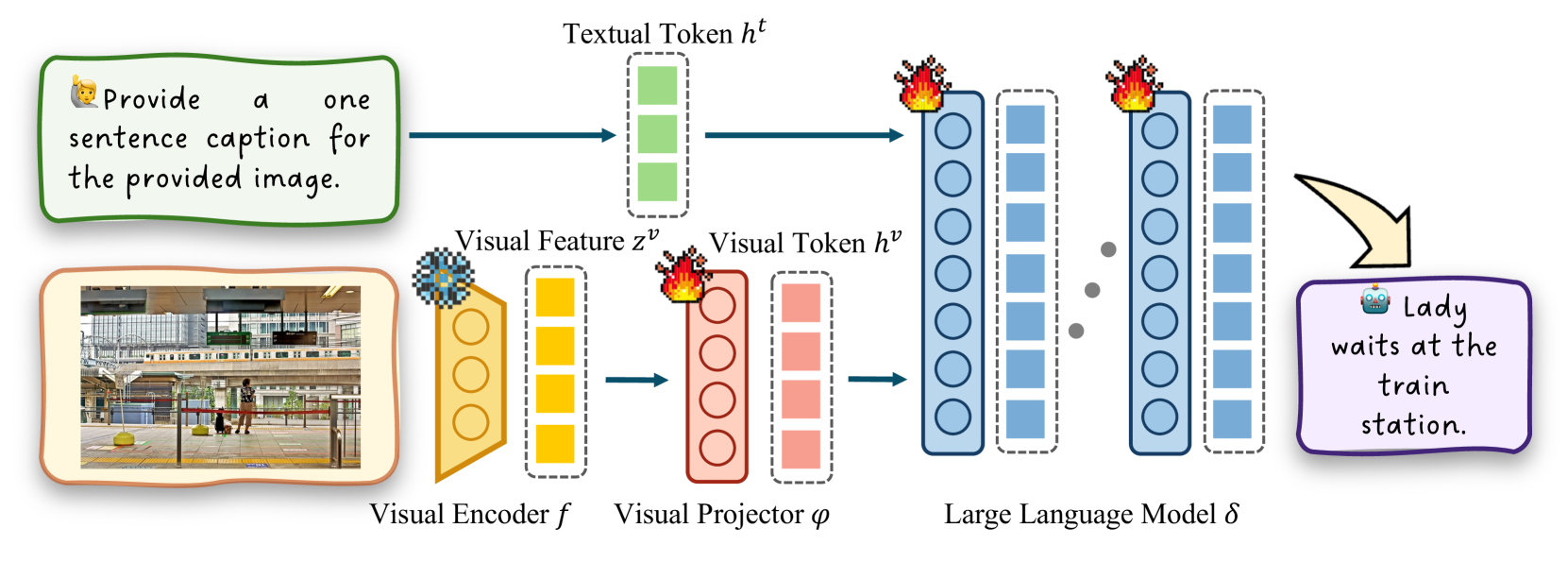

📊 实验亮点
论文通过在多个MLLM架构和下游任务上进行基准测试,系统地评估了不同微调策略的性能。实验结果表明,不同的微调策略在不同的任务上表现各异,选择合适的微调策略可以显著提升模型性能。例如,在某些任务上,选择性微调可以有效避免灾难性遗忘,而在另一些任务上,增量微调可以更好地适应目标数据集的分布。
🎯 应用场景
该研究成果可广泛应用于图像描述、视觉问答、机器人导航、智能助手等领域。通过选择合适的微调策略,可以提升MLLM在特定任务上的性能,同时保持模型的通用性和稳定性,从而提高相关应用的智能化水平和用户体验。未来的研究可以进一步探索更加高效和鲁棒的微调方法,以应对更加复杂和多样化的应用场景。
📄 摘要(原文)
Multi-modal Large Language Models (MLLMs) integrate visual and linguistic reasoning to address complex tasks such as image captioning and visual question answering. While MLLMs demonstrate remarkable versatility, MLLMs appears limited performance on special applications. But tuning MLLMs for downstream tasks encounters two key challenges: Task-Expert Specialization, where distribution shifts between pre-training and target datasets constrain target performance, and Open-World Stabilization, where catastrophic forgetting erases the model general knowledge. In this work, we systematically review recent advancements in MLLM tuning methodologies, classifying them into three paradigms: (I) Selective Tuning, (II) Additive Tuning, and (III) Reparameterization Tuning. Furthermore, we benchmark these tuning strategies across popular MLLM architectures and diverse downstream tasks to establish standardized evaluation analysis and systematic tuning principles. Finally, we highlight several open challenges in this domain and propose future research directions. To facilitate ongoing progress in this rapidly evolving field, we provide a public repository that continuously tracks developments: https://github.com/WenkeHuang/Awesome-MLLM-Tuning.