Revisiting the Othello World Model Hypothesis
作者: Yifei Yuan, Anders Søgaard
分类: cs.CL
发布日期: 2025-03-06
备注: ICLR World Models Workshop
💡 一句话要点
通过扩展实验,为语言模型具备黑白棋世界模型能力提供更强证据
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 语言模型 世界模型 黑白棋 表征学习 无监督学习
📋 核心要点
- 现有研究对语言模型是否能学习黑白棋世界模型存在争议,需要更全面的实验验证。
- 论文通过分析黑白棋棋盘状态序列,训练语言模型预测下一步走法,以此评估模型是否具备黑白棋世界模型。
- 实验结果表明,多种语言模型不仅学会了下黑白棋,还能推断出棋盘布局,且模型间学习到的特征相似度高。
📝 摘要(中文)
本文重新审视了黑白棋世界模型的假设。Li等人(2023)使用黑白棋作为测试用例,研究GPT-2诱导世界模型的能力,Nanda等人(2023b)对此进行了跟进。本文简要讨论了原始实验,并通过更全面的探测将其扩展到更多语言模型。具体来说,我们分析了黑白棋棋盘状态序列,并训练模型根据之前的走法预测下一步走法。我们评估了七个语言模型(GPT-2、T5、Bart、Flan-T5、Mistral、LLaMA-2和Qwen2.5)在黑白棋任务上的表现,并得出结论:这些模型不仅学会了下黑白棋,而且还诱导出了黑白棋棋盘的布局。我们发现所有模型在无监督 grounding 中都达到了高达 99% 的准确率,并且它们学习到的棋盘特征表现出高度相似性。这为黑白棋世界模型假设提供了比以往工作更强的证据。
🔬 方法详解
问题定义:现有研究,如Li et al. (2023)和Nanda et al. (2023b),探索了语言模型学习黑白棋世界模型的能力,但存在模型种类较少、探测不够全面的问题。本文旨在通过更广泛的模型和更深入的分析,为语言模型具备黑白棋世界模型提供更强的证据。现有方法的痛点在于缺乏对多种模型的系统性评估,以及对模型学习到的棋盘表征的深入理解。
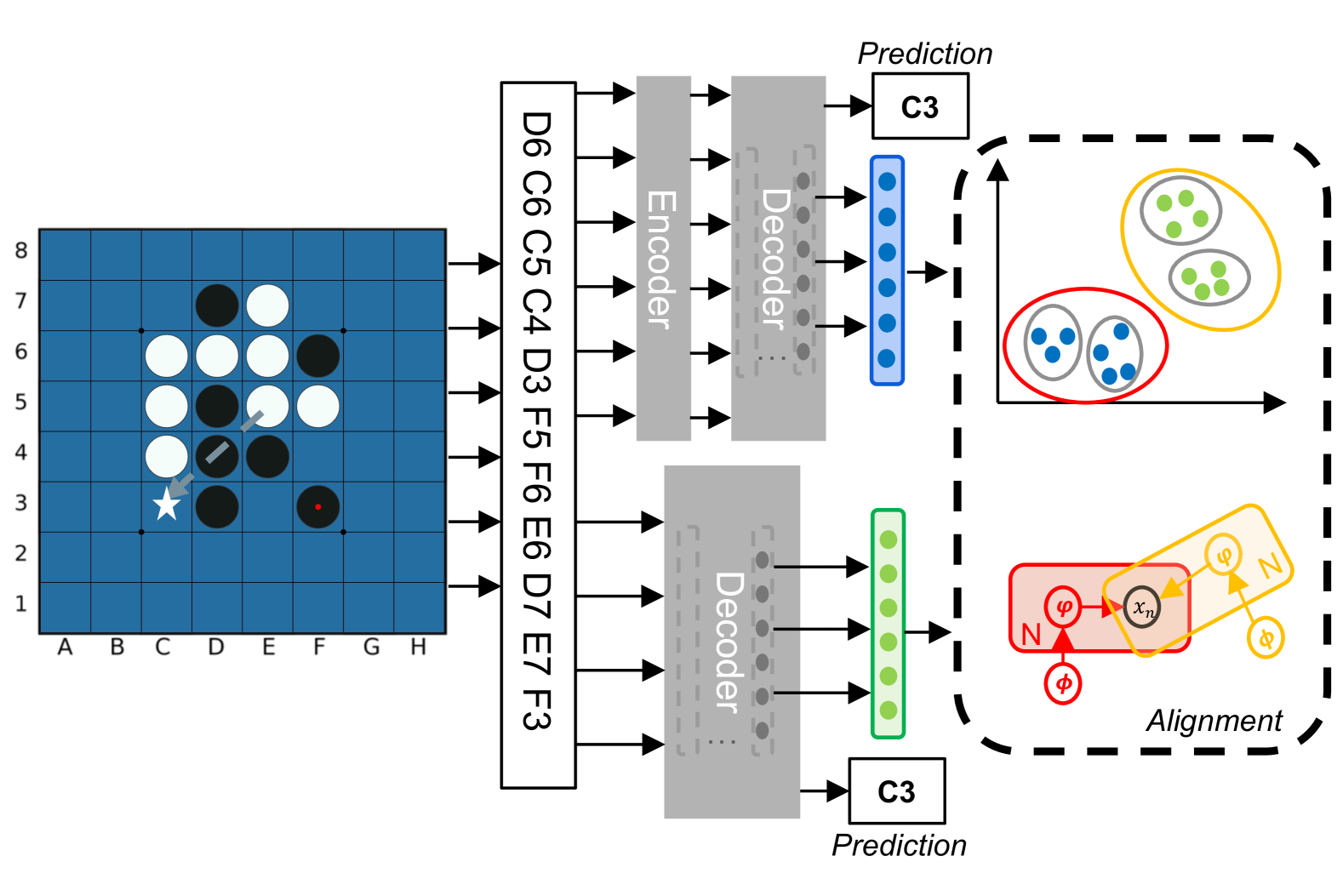
核心思路:核心思路是训练语言模型预测黑白棋的下一步走法,并分析模型内部表征,以确定模型是否学习了黑白棋的规则和棋盘布局。如果模型能够准确预测下一步走法,并且其内部表征与棋盘布局高度相关,则可以认为模型具备黑白棋世界模型。这种设计思路基于一个假设:如果模型真正理解了黑白棋,它就应该能够预测下一步,并且其内部表征应该反映棋盘的状态。
技术框架:整体框架包括以下几个主要步骤:1) 数据准备:收集黑白棋棋盘状态序列数据。2) 模型训练:使用语言模型(GPT-2、T5、Bart、Flan-T5、Mistral、LLaMA-2和Qwen2.5)训练模型预测下一步走法。3) 模型评估:评估模型预测下一步走法的准确率。4) 表征分析:分析模型内部表征,例如注意力权重或隐藏层激活,以确定模型是否学习了棋盘布局。5) 模型比较:比较不同模型学习到的棋盘表征的相似度。
关键创新:最重要的创新点在于对多种语言模型进行了系统性的评估,并深入分析了模型学习到的棋盘表征。与现有方法相比,本文不仅关注模型预测下一步走法的准确率,还关注模型内部表征与棋盘布局之间的关系。通过比较不同模型学习到的棋盘表征的相似度,本文进一步验证了语言模型具备黑白棋世界模型的能力。
关键设计:关键设计包括:1) 使用交叉熵损失函数训练模型预测下一步走法。2) 使用注意力权重或隐藏层激活作为模型内部表征。3) 使用余弦相似度来衡量不同模型学习到的棋盘表征的相似度。4) 对模型进行无监督 grounding 评估,以确定模型是否能够将棋盘上的位置与相应的符号关联起来。
🖼️ 关键图片


📊 实验亮点
实验结果显示,所有七个语言模型在黑白棋任务上都表现出色,在无监督 grounding 中达到了高达 99% 的准确率。此外,不同模型学习到的棋盘特征表现出高度相似性,表明这些模型都以类似的方式学习了黑白棋世界模型。这些结果为语言模型具备世界模型能力提供了强有力的支持。
🎯 应用场景
该研究有助于理解大型语言模型如何学习和表示世界知识,为开发更智能、更具泛化能力的AI系统提供理论基础。潜在应用包括:提升AI在复杂环境中的决策能力,改进AI对物理世界的理解,以及开发更可靠的AI模拟器。
📄 摘要(原文)
Li et al. (2023) used the Othello board game as a test case for the ability of GPT-2 to induce world models, and were followed up by Nanda et al. (2023b). We briefly discuss the original experiments, expanding them to include more language models with more comprehensive probing. Specifically, we analyze sequences of Othello board states and train the model to predict the next move based on previous moves. We evaluate seven language models (GPT-2, T5, Bart, Flan-T5, Mistral, LLaMA-2, and Qwen2.5) on the Othello task and conclude that these models not only learn to play Othello, but also induce the Othello board layout. We find that all models achieve up to 99% accuracy in unsupervised grounding and exhibit high similarity in the board features they learned. This provides considerably stronger evidence for the Othello World Model Hypothesis than previous works.