TableLoRA: Low-rank Adaptation on Table Structure Understanding for Large Language Models
作者: Xinyi He, Yihao Liu, Mengyu Zhou, Yeye He, Haoyu Dong, Shi Han, Zejian Yuan, Dongmei Zhang
分类: cs.CL
发布日期: 2025-03-06 (更新: 2025-06-27)
备注: Accepted by ACL 2025 main conference, long paper
💡 一句话要点
TableLoRA:面向大语言模型的表格结构理解低秩自适应方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 表格理解 低秩自适应 参数高效微调 大语言模型 结构化数据
📋 核心要点
- 现有PEFT方法在表格数据上表现不佳,难以有效处理表格的二维结构信息,阻碍了LLM对表格数据的理解。
- TableLoRA通过特殊token编码器序列化表格,并利用2D LoRA对单元格位置信息进行编码,从而提升LLM对表格结构的理解能力。
- 实验结果表明,TableLoRA在多个表格数据集上显著优于传统LoRA和其他表格编码方法,尤其在低参数场景下表现出色。
📝 摘要(中文)
表格数据在许多领域至关重要,大语言模型(LLM)在高参数效率范式下理解表格数据非常重要。然而,直接将参数高效微调(PEFT)技术应用于表格任务面临重大挑战,尤其是在更好的表格序列化以及在一维序列中表示二维结构化信息方面。为了解决这个问题,我们提出了TableLoRA,一个旨在提高LLM在PEFT期间对表格结构理解的模块。它结合了用于序列化表格的特殊token编码器,并使用2D LoRA来编码单元格位置上的低秩信息。在四个与表格相关的的数据集上的实验表明,TableLoRA始终优于vanilla LoRA,并超过了对照实验中测试的各种表格编码方法。这些发现表明,TableLoRA作为一种特定于表格的LoRA,增强了LLM有效处理表格数据的能力,尤其是在低参数设置下,展示了其作为处理表格相关任务的强大解决方案的潜力。
🔬 方法详解
问题定义:论文旨在解决大语言模型在参数高效微调(PEFT)框架下,对表格结构理解不足的问题。现有方法难以有效处理表格的二维结构信息,导致LLM无法充分利用表格数据中的信息。直接应用传统PEFT方法(如LoRA)到表格任务,无法很好地捕捉表格的行列关系和单元格之间的依赖。
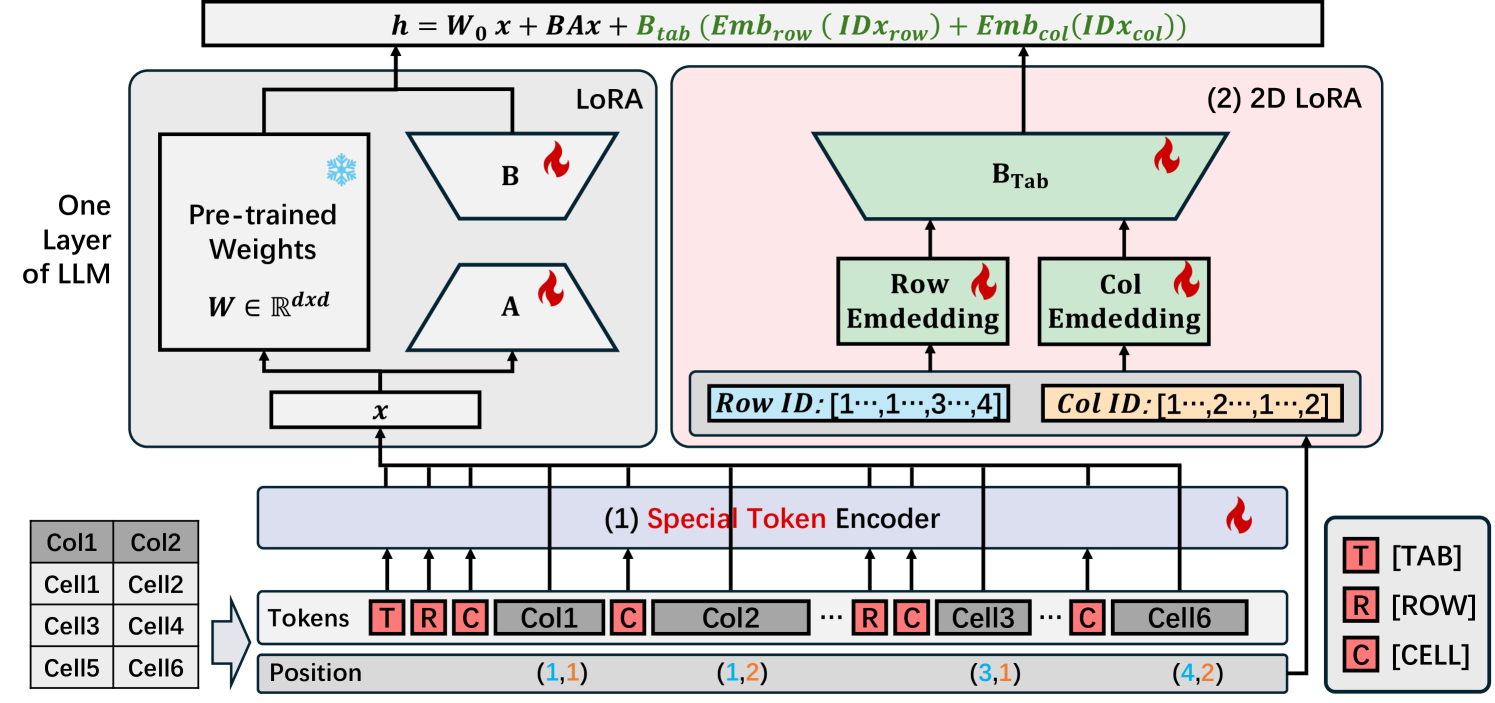
核心思路:论文的核心思路是设计一个表格特定的LoRA模块(TableLoRA),通过引入特殊token编码器和2D LoRA,显式地对表格结构信息进行编码。特殊token编码器用于将表格序列化,同时保留表格的行列信息。2D LoRA则用于学习单元格位置的低秩表示,从而增强LLM对表格结构的感知能力。
技术框架:TableLoRA的整体框架包括两个主要模块:特殊token编码器和2D LoRA。首先,特殊token编码器将表格转换为一维序列,其中使用特殊的token来标记行和列的边界。然后,2D LoRA模块被应用于LLM的Transformer层,用于学习单元格位置的低秩表示。在训练过程中,只有TableLoRA模块的参数被更新,而LLM的其余参数保持固定。
关键创新:TableLoRA的关键创新在于其针对表格结构信息的显式编码方式。与传统的LoRA方法相比,TableLoRA不仅学习了输入数据的低秩表示,还学习了表格的结构信息,从而更好地适应了表格任务。2D LoRA的设计能够捕捉单元格之间的空间关系,这对于理解表格数据至关重要。
关键设计:特殊token编码器使用预定义的特殊token来标记表格的行和列。2D LoRA模块通过将单元格的位置信息编码为二维坐标,并将其作为LoRA模块的输入,从而学习单元格位置的低秩表示。损失函数采用标准的交叉熵损失函数,用于优化TableLoRA模块的参数。具体的网络结构细节(如LoRA的秩)和超参数设置(如学习率)需要根据具体的任务和数据集进行调整。
🖼️ 关键图片
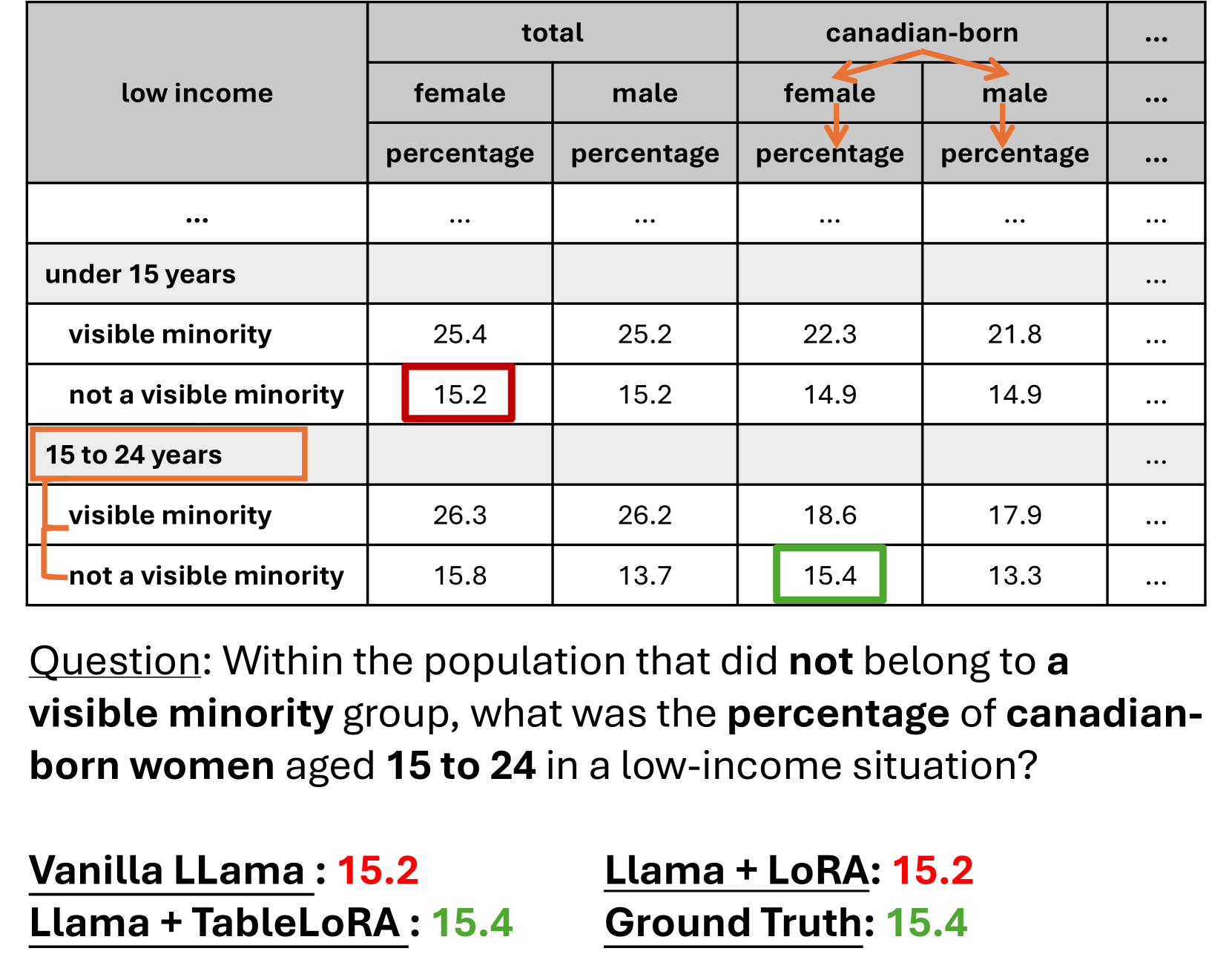
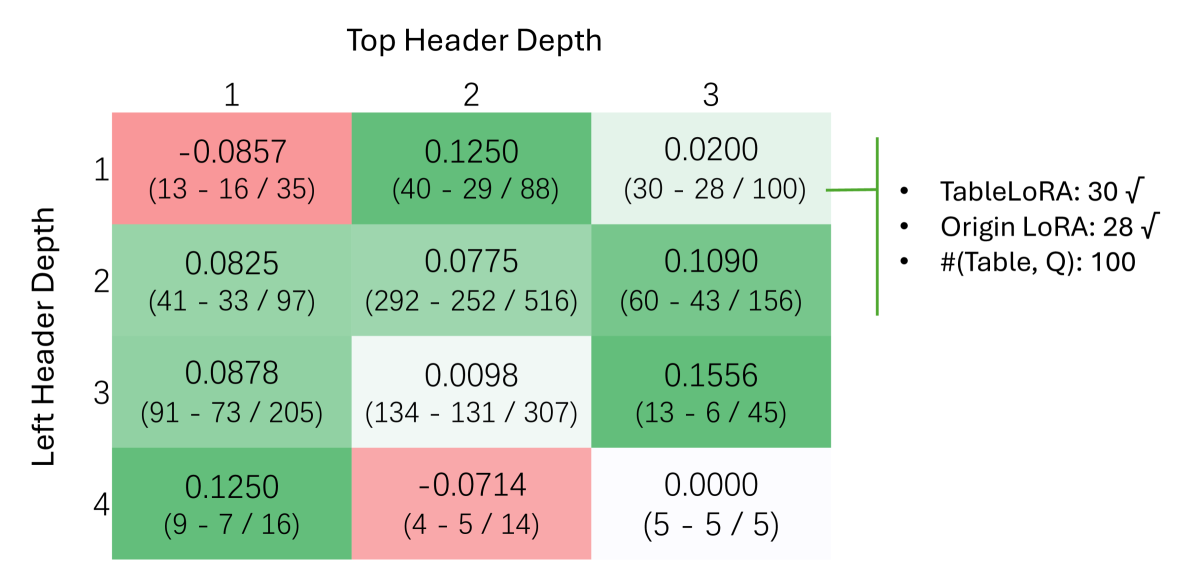
📊 实验亮点
实验结果表明,TableLoRA在四个表格相关的数据集上均优于vanilla LoRA和其他表格编码方法。例如,在某个数据集上,TableLoRA的性能提升了5%以上。这些结果证明了TableLoRA能够有效提升LLM对表格结构的理解能力,尤其是在低参数设置下。
🎯 应用场景
TableLoRA具有广泛的应用前景,可应用于金融、医疗、电商等领域,提升LLM在表格数据分析、报告生成、问答系统等任务中的性能。该方法能够有效降低模型微调的成本,使得LLM能够更好地适应各种表格相关的应用场景,具有重要的实际价值和未来影响。
📄 摘要(原文)
Tabular data are crucial in many fields and their understanding by large language models (LLMs) under high parameter efficiency paradigm is important. However, directly applying parameter-efficient fine-tuning (PEFT) techniques to tabular tasks presents significant challenges, particularly in terms of better table serialization and the representation of two-dimensional structured information within a one-dimensional sequence. To address this, we propose TableLoRA, a module designed to improve LLMs' understanding of table structure during PEFT. It incorporates special tokens for serializing tables with special token encoder and uses 2D LoRA to encode low-rank information on cell positions. Experiments on four tabular-related datasets demonstrate that TableLoRA consistently outperforms vanilla LoRA and surpasses various table encoding methods tested in control experiments. These findings reveal that TableLoRA, as a table-specific LoRA, enhances the ability of LLMs to process tabular data effectively, especially in low-parameter settings, demonstrating its potential as a robust solution for handling table-related tasks.