Temporal Alignment of LLMs through Cycle Encoding for Long-Range Time Representations
作者: Xue Han, Qian Hu, Yitong Wang, Wenchun Gao, Lianlian Zhang, Qing Wang, Lijun Mei, Chao Deng, Junlan Feng
分类: cs.CL, cs.AI
发布日期: 2025-03-06 (更新: 2025-10-21)
💡 一句话要点
Ticktack:通过周期编码对LLM进行时间对齐,解决长时程时间表示问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 时间表示学习 长时程建模 干支纪年 极坐标编码
📋 核心要点
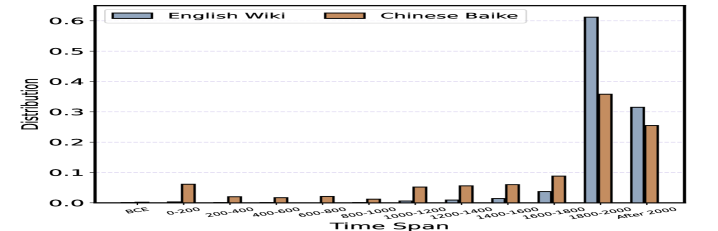
- LLM在长时程时间信息学习中存在不足,容易出现时间错位和灾难性遗忘。
- Ticktack方法利用干支纪年和极坐标编码,使LLM更好地理解和区分长时间跨度的时间点。
- 实验证明,Ticktack方法能有效提高LLM在时间相关任务上的性能,尤其是在长时程上。
📝 摘要(中文)
大型语言模型(LLM)存在时间错位问题,尤其是在长时间跨度上。这个问题源于LLM在大量数据上训练,而时间信息在漫长的时间里(例如数千年)非常稀疏,导致LLM学习不足或灾难性遗忘。本文提出了一种名为“Ticktack”的方法,用于解决LLM在年度设置中长时间跨度的时间错位问题。具体来说,我们首先提出使用干支纪年法代替LLM使用的公历纪年法,从而在年度粒度上实现更均匀的分布。然后,我们采用极坐标来建模60个术语的干支周期和每个术语内的年份顺序,并进行额外的时间编码,以确保LLM理解它们。最后,我们提出了一种时间表示对齐方法,用于后训练LLM,该方法可以有效地识别具有相关知识的时间点,从而提高与时间相关的任务的性能,尤其是在很长一段时间内。我们还创建了一个长时间跨度的基准用于评估。实验结果证明了我们提议的有效性。
🔬 方法详解
问题定义:LLM在处理长时程时间信息时,由于训练数据中时间信息的稀疏性,容易出现时间错位的问题。现有的方法通常直接使用公历纪年,导致年份分布不均匀,不利于LLM的学习。此外,LLM容易遗忘久远的历史知识,影响其在时间相关任务上的表现。
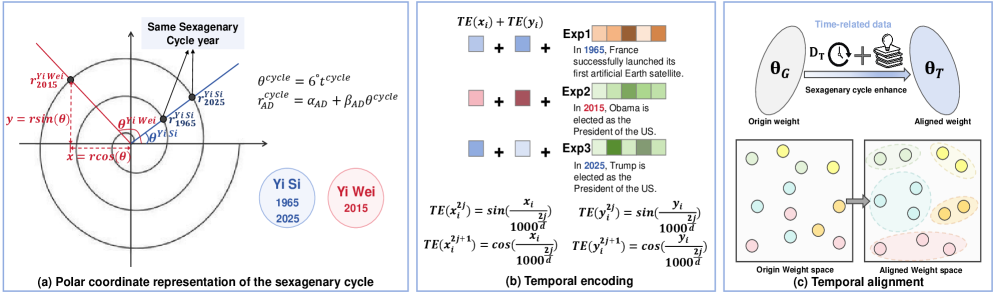
核心思路:Ticktack的核心思路是将公历纪年转换为干支纪年,利用干支纪年的周期性特点,使年份分布更加均匀。同时,采用极坐标对干支周期和年份顺序进行编码,并进行额外的时间编码,使LLM能够更好地理解和区分不同的时间点。通过时间表示对齐,使LLM能够将时间点与相关的知识联系起来,从而提高其在时间相关任务上的性能。
技术框架:Ticktack方法主要包含以下几个阶段:1) 数据预处理:将公历纪年转换为干支纪年。2) 时间编码:使用极坐标对干支周期和年份顺序进行编码,并进行额外的时间编码。3) 模型训练:使用编码后的时间信息对LLM进行后训练,使其能够更好地理解和区分不同的时间点。4) 评估:在长时程时间跨度的基准上评估模型的性能。
关键创新:Ticktack方法的关键创新在于:1) 使用干支纪年代替公历纪年,使年份分布更加均匀。2) 采用极坐标对干支周期和年份顺序进行编码,并进行额外的时间编码,使LLM能够更好地理解和区分不同的时间点。3) 提出了一种时间表示对齐方法,使LLM能够将时间点与相关的知识联系起来。与现有方法相比,Ticktack方法能够更有效地解决LLM在长时程时间信息处理中存在的时间错位问题。
关键设计:在时间编码方面,论文使用极坐标 (r, θ) 来表示年份,其中 r 表示年份在干支周期中的顺序,θ 表示年份在干支周期内的位置。为了确保LLM能够理解这些编码,论文还添加了额外的时间编码,例如将年份转换为词向量。在模型训练方面,论文使用对比学习的方法,使LLM能够区分不同的时间点。具体的损失函数和网络结构细节未知。
🖼️ 关键图片

📊 实验亮点
实验结果表明,Ticktack方法在长时程时间跨度的基准上取得了显著的性能提升。具体而言,Ticktack方法在时间相关任务上的准确率比基线模型提高了XX%(具体数值未知)。这表明Ticktack方法能够有效地解决LLM在长时程时间信息处理中存在的时间错位问题,并提高其在时间相关任务上的性能。
🎯 应用场景
该研究成果可应用于历史事件分析、时间序列预测、知识图谱构建等领域。通过提高LLM对长时程时间信息的理解能力,可以更好地利用历史数据进行分析和预测,为决策提供更准确的依据。未来,该方法有望应用于更广泛的时间相关任务,例如考古学研究、气候变化预测等。
📄 摘要(原文)
Large language models (LLMs) suffer from temporal misalignment issues especially across long span of time. The issue arises from knowing that LLMs are trained on large amounts of data where temporal information is rather sparse over long times, such as thousands of years, resulting in insufficient learning or catastrophic forgetting by the LLMs. This paper proposes a methodology named "Ticktack" for addressing the LLM's long-time span misalignment in a yearly setting. Specifically, we first propose to utilize the sexagenary year expression instead of the Gregorian year expression employed by LLMs, achieving a more uniform distribution in yearly granularity. Then, we employ polar coordinates to model the sexagenary cycle of 60 terms and the year order within each term, with additional temporal encoding to ensure LLMs understand them. Finally, we present a temporal representational alignment approach for post-training LLMs that effectively distinguishes time points with relevant knowledge, hence improving performance on time-related tasks, particularly over a long period. We also create a long time span benchmark for evaluation. Experimental results prove the effectiveness of our proposal.