Chart-HQA: A Benchmark for Hypothetical Question Answering in Charts
作者: Xiangnan Chen, Yuancheng Fang, Qian Xiao, Juncheng Li, Jun Lin, Siliang Tang, Yi Yang, Yueting Zhuang
分类: cs.CL, cs.AI
发布日期: 2025-03-06 (更新: 2025-03-07)
备注: Under review
💡 一句话要点
提出Chart-HQA基准,用于评估多模态大语言模型在图表中的假设性问题回答能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 图表问答 多模态大语言模型 假设性问题回答 反事实推理 人机交互 数据合成 基准测试
📋 核心要点
- 现有图表问答基准测试忽略了多模态大语言模型(MLLMs)的输出偏差,模型倾向于依赖参数记忆而非图表理解。
- 提出Chart-HQA任务,通过对问题施加假设,促使模型进行基于图表内容的反事实推理,从而评估其真正理解能力。
- 引入HAI人机交互数据合成方法,利用LLMs和专家知识,低成本生成高质量、多样化的HQA数据,构建了具有挑战性的基准。
📝 摘要(中文)
多模态大语言模型(MLLMs)因其强大的视觉语义理解能力而备受关注。现有的大多数图表基准测试评估MLLMs从图表中解析信息以回答问题的能力。然而,它们忽略了MLLMs固有的输出偏差,即模型依赖其参数记忆来回答问题,而不是真正理解图表内容。为了解决这个局限性,我们引入了一种新的图表假设性问题回答(HQA)任务,该任务对同一问题施加假设,迫使模型基于图表内容进行反事实推理。此外,我们引入了HAI,一种人机交互数据合成方法,它利用LLMs高效的文本编辑能力以及人类专家知识,以低成本生成多样化和高质量的HQA数据。使用HAI,我们构建了Chart-HQA,这是一个从公开可用数据源合成的具有挑战性的基准。对18个不同模型大小的MLLMs的评估结果表明,当前的模型面临着重大的泛化挑战,并且在HQA任务上表现出不平衡的推理性能。
🔬 方法详解
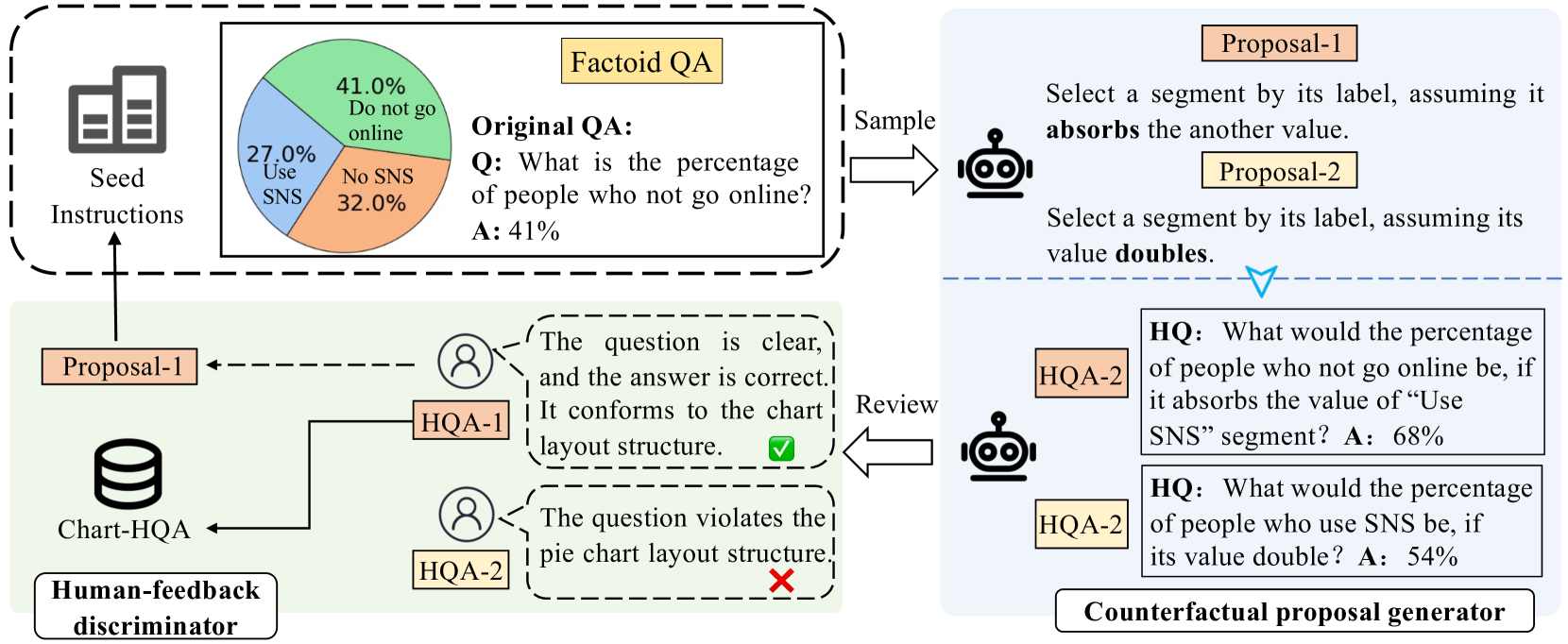
问题定义:现有图表问答任务主要关注模型从图表中提取信息并回答问题的能力,但忽略了模型可能存在的输出偏差,即模型可能仅仅依赖于预训练的参数记忆来回答问题,而没有真正理解图表的内容。这导致模型在实际应用中泛化能力不足,无法处理需要反事实推理的复杂问题。
核心思路:为了解决上述问题,论文提出了Chart-HQA任务,该任务的核心在于引入“假设性问题”。通过对同一问题施加不同的假设条件,迫使模型基于图表内容进行反事实推理,从而更准确地评估模型对图表的真正理解能力。这种方法可以有效减少模型对参数记忆的依赖,提高模型的泛化能力。
技术框架:论文提出的技术框架主要包括两个部分:一是Chart-HQA基准的构建,二是HAI(Human-AI Interactive)数据合成方法。HAI方法利用LLMs的文本编辑能力和人类专家的知识,迭代生成高质量的假设性问题和答案。具体流程是,首先由人类专家设计问题模板,然后利用LLMs生成候选问题和答案,最后由人类专家进行审核和修正,最终得到高质量的HQA数据。
关键创新:论文的关键创新在于提出了Chart-HQA任务和HAI数据合成方法。Chart-HQA任务通过引入假设性问题,更有效地评估了模型对图表的理解能力。HAI方法则通过人机交互的方式,低成本地生成了高质量、多样化的HQA数据,解决了数据标注成本高昂的问题。
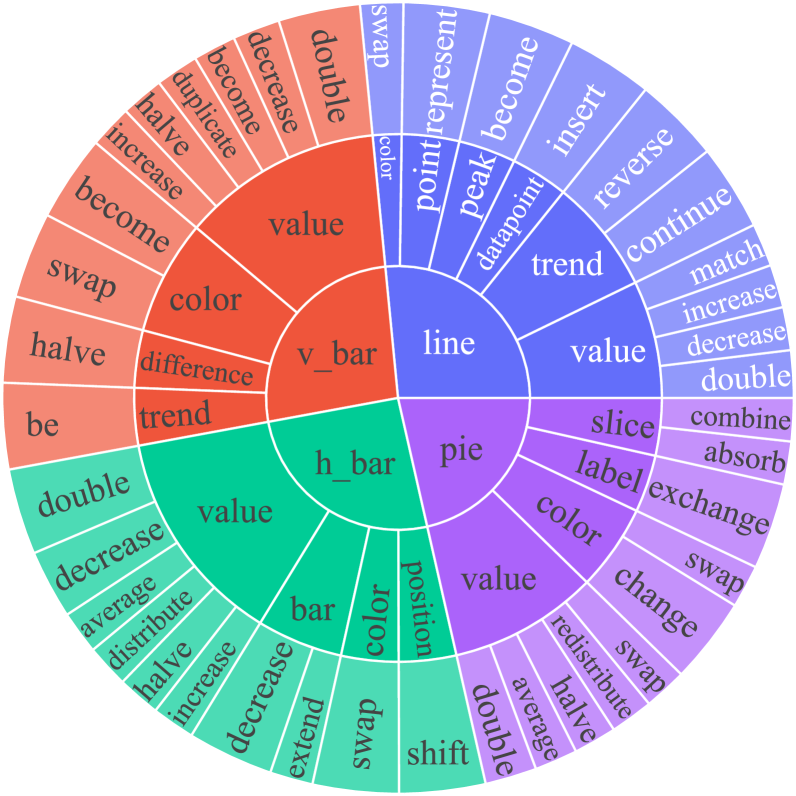
关键设计:在HAI方法中,关键的设计包括问题模板的设计、LLMs的选择和使用、以及人类专家的审核流程。问题模板需要覆盖各种类型的图表和问题,LLMs需要具备强大的文本生成和编辑能力,人类专家需要具备专业的图表理解和推理能力。此外,论文还设计了一套评估指标,用于评估模型在Chart-HQA任务上的性能,包括准确率、召回率和F1值等。
🖼️ 关键图片

📊 实验亮点
在18个不同规模的MLLMs上的实验结果表明,现有模型在Chart-HQA任务上表现出显著的泛化挑战和不平衡的推理性能。这表明现有模型在理解图表内容和进行反事实推理方面仍有很大的提升空间。Chart-HQA基准的提出为未来研究提供了一个更具挑战性和更具代表性的评估平台。
🎯 应用场景
该研究成果可应用于提升多模态大语言模型在数据分析、商业智能、教育等领域的应用能力。通过Chart-HQA基准的评估,可以筛选出更具泛化能力和推理能力的模型,从而更好地辅助用户理解和分析图表数据,做出更明智的决策。未来,该研究还可以扩展到其他类型的图表和数据可视化,进一步提升模型的通用性和实用性。
📄 摘要(原文)
Multimodal Large Language Models (MLLMs) have garnered significant attention for their strong visual-semantic understanding. Most existing chart benchmarks evaluate MLLMs' ability to parse information from charts to answer questions. However, they overlook the inherent output biases of MLLMs, where models rely on their parametric memory to answer questions rather than genuinely understanding the chart content. To address this limitation, we introduce a novel Chart Hypothetical Question Answering (HQA) task, which imposes assumptions on the same question to compel models to engage in counterfactual reasoning based on the chart content. Furthermore, we introduce HAI, a human-AI interactive data synthesis approach that leverages the efficient text-editing capabilities of LLMs alongside human expert knowledge to generate diverse and high-quality HQA data at a low cost. Using HAI, we construct Chart-HQA, a challenging benchmark synthesized from publicly available data sources. Evaluation results on 18 MLLMs of varying model sizes reveal that current models face significant generalization challenges and exhibit imbalanced reasoning performance on the HQA task.