Benchmarking Large Language Models on Multiple Tasks in Bioinformatics NLP with Prompting
作者: Jiyue Jiang, Pengan Chen, Jiuming Wang, Dongchen He, Ziqin Wei, Liang Hong, Licheng Zong, Sheng Wang, Qinze Yu, Zixian Ma, Yanyu Chen, Yimin Fan, Xiangyu Shi, Jiawei Sun, Chuan Wu, Yu Li
分类: cs.CL, cs.AI
发布日期: 2025-03-06
💡 一句话要点
Bio-benchmark:基于Prompt的大语言模型在生物信息学NLP多任务上的综合评测框架
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 生物信息学 自然语言处理 基准测试 Prompt工程
📋 核心要点
- 现有生物信息学LLM基准测试难以有效评估模型在多样化任务中的性能。
- 提出Bio-benchmark,一个包含30个生物信息学任务的prompt基准测试框架,无需微调。
- BioFinder工具将LLM答案提取准确率提升约30%,并分析了LLM在不同生物任务上的表现。
📝 摘要(中文)
大型语言模型(LLMs)已成为解决生物学问题的重要工具,与传统方法相比,在准确性和适应性方面有所改进。虽然已经提出了一些基准来评估这些LLM的性能,但现有的基准很难有效地评估这些模型在不同任务中的性能。本文介绍了一个全面的基于prompt的基准测试框架,名为Bio-benchmark,其中包括30个关键的生物信息学任务,涵盖蛋白质、RNA、药物、电子健康记录和传统中医药等领域。我们使用该基准评估了六个主流LLM,包括GPT-4o和Llama-3.1-70b等,采用0-shot和few-shot的思维链(CoT)设置,无需微调,以揭示它们的内在能力。为了提高评估效率,我们展示了BioFinder,这是一种从LLM响应中提取答案的新工具,与现有方法相比,提取准确率提高了约30%。我们的基准测试结果表明了当前LLM适合的生物学任务,并确定了需要加强的特定领域。此外,我们提出了有针对性的prompt工程策略,以优化LLM在这些环境中的性能。基于这些发现,我们为开发更强大的、为各种生物学应用量身定制的LLM提供了建议。这项工作提供了一个全面的评估框架和强大的工具,以支持LLM在生物信息学中的应用。
🔬 方法详解
问题定义:现有生物信息学领域的大语言模型(LLM)评估基准存在覆盖任务类型不足的问题,难以全面评估LLM在不同生物信息学任务上的性能。此外,从LLM的输出中准确提取答案也是一个挑战,现有的提取方法准确率较低。
核心思路:论文的核心思路是构建一个更全面、更高效的生物信息学LLM基准测试框架。通过设计包含多种生物信息学任务的基准数据集,并结合prompt工程和答案提取工具,更准确地评估LLM的性能,并为LLM在生物信息学领域的应用提供指导。
技术框架:Bio-benchmark框架主要包含以下几个部分:1) 任务选择与数据构建:选择涵盖蛋白质、RNA、药物、电子健康记录和传统中医药等领域的30个关键生物信息学任务,构建相应的测试数据集。2) Prompt设计:针对每个任务设计合适的prompt,包括0-shot和few-shot Chain-of-Thought (CoT) prompt。3) 模型评估:使用不同的LLM(如GPT-4o和Llama-3.1-70b)在Bio-benchmark上进行评估,记录模型的性能指标。4) 答案提取:开发BioFinder工具,从LLM的输出中提取答案。5) 结果分析与prompt优化:分析评估结果,提出针对性的prompt工程策略,以优化LLM在这些环境中的性能。
关键创新:1) 全面的生物信息学基准:Bio-benchmark覆盖了更广泛的生物信息学任务,能够更全面地评估LLM的性能。2) 高效的答案提取工具:BioFinder工具能够更准确地从LLM的输出中提取答案,提高了评估的效率和准确性。3) 针对性的prompt工程策略:论文提出了针对不同生物信息学任务的prompt工程策略,能够有效提升LLM的性能。
关键设计:BioFinder工具的具体实现细节未知,但其核心在于提高从LLM生成文本中提取正确答案的准确率。Prompt的设计需要根据不同的任务进行调整,以引导LLM生成更准确、更易于提取的答案。论文使用了0-shot和few-shot CoT prompting,CoT prompting通过引导模型进行逐步推理,可以提高模型的性能。
🖼️ 关键图片

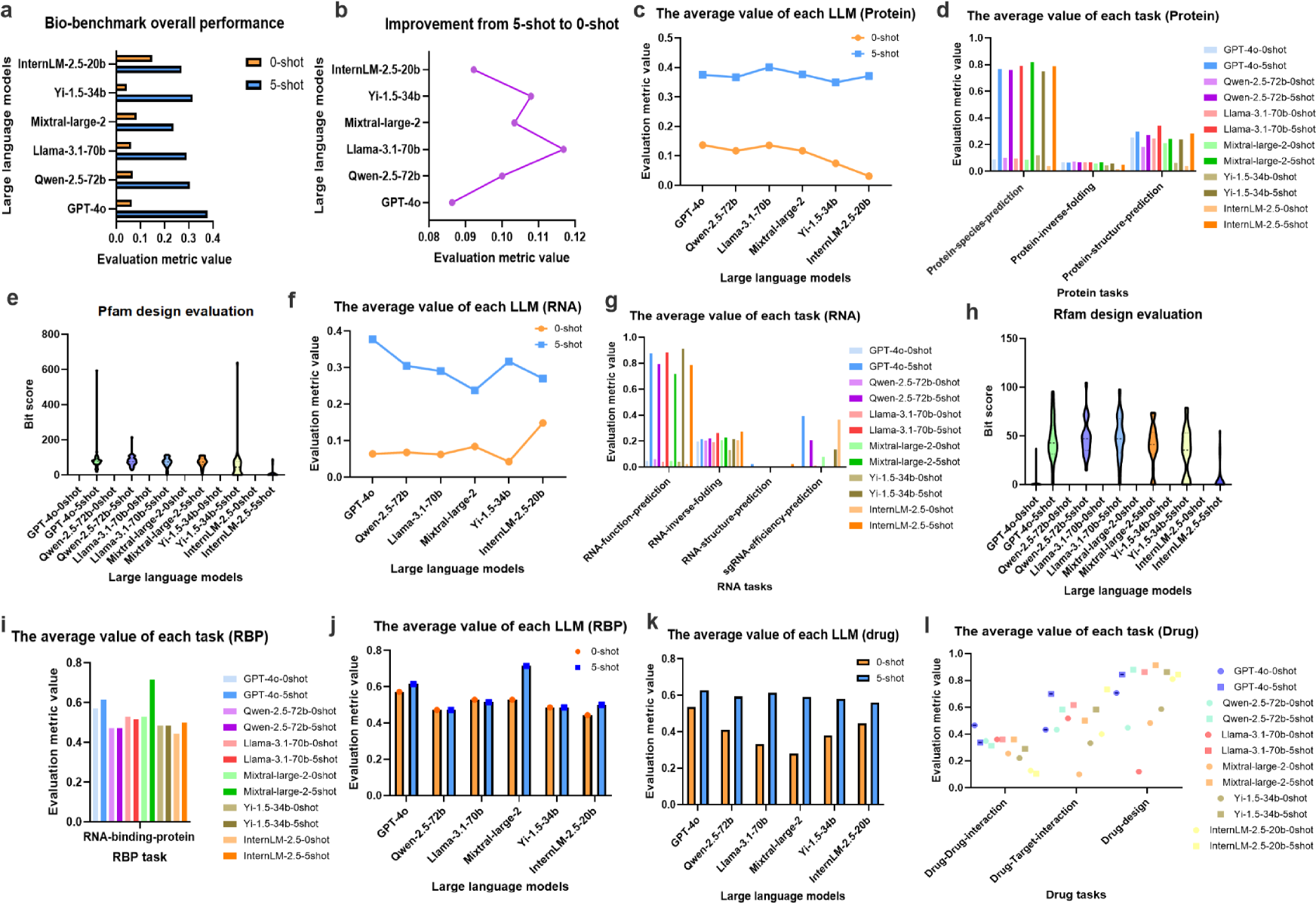

📊 实验亮点
Bio-benchmark评估了六个主流LLM在30个生物信息学任务上的性能,结果表明当前LLM在某些生物任务上表现良好,但在其他领域仍有提升空间。BioFinder工具将LLM答案提取准确率提升了约30%。此外,论文还提出了针对性的prompt工程策略,可以有效优化LLM在生物信息学任务中的性能,为开发更强大的生物信息学LLM提供了指导。
🎯 应用场景
该研究成果可应用于生物信息学领域,帮助研究人员选择和优化适用于特定生物任务的LLM。Bio-benchmark可以作为评估和比较不同LLM在生物信息学任务上性能的标准平台。此外,prompt工程策略可以指导用户设计更有效的prompt,从而提高LLM在生物信息学领域的应用效果。未来,该研究可以扩展到更多生物领域,并开发更强大的LLM和工具,以解决更复杂的生物问题。
📄 摘要(原文)
Large language models (LLMs) have become important tools in solving biological problems, offering improvements in accuracy and adaptability over conventional methods. Several benchmarks have been proposed to evaluate the performance of these LLMs. However, current benchmarks can hardly evaluate the performance of these models across diverse tasks effectively. In this paper, we introduce a comprehensive prompting-based benchmarking framework, termed Bio-benchmark, which includes 30 key bioinformatics tasks covering areas such as proteins, RNA, drugs, electronic health records, and traditional Chinese medicine. Using this benchmark, we evaluate six mainstream LLMs, including GPT-4o and Llama-3.1-70b, etc., using 0-shot and few-shot Chain-of-Thought (CoT) settings without fine-tuning to reveal their intrinsic capabilities. To improve the efficiency of our evaluations, we demonstrate BioFinder, a new tool for extracting answers from LLM responses, which increases extraction accuracy by round 30% compared to existing methods. Our benchmark results show the biological tasks suitable for current LLMs and identify specific areas requiring enhancement. Furthermore, we propose targeted prompt engineering strategies for optimizing LLM performance in these contexts. Based on these findings, we provide recommendations for the development of more robust LLMs tailored for various biological applications. This work offers a comprehensive evaluation framework and robust tools to support the application of LLMs in bioinformatics.