Improving LLM Safety Alignment with Dual-Objective Optimization
作者: Xuandong Zhao, Will Cai, Tianneng Shi, David Huang, Licong Lin, Song Mei, Dawn Song
分类: cs.CL, cs.CR, cs.LG
发布日期: 2025-03-05 (更新: 2025-10-30)
备注: ICML 2025
🔗 代码/项目: GITHUB
💡 一句话要点
提出双目标优化方法DOOR,提升LLM抵抗对抗攻击的安全对齐能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 安全对齐 Jailbreak攻击 直接偏好优化 双目标优化 鲁棒拒绝训练 有害知识消除 token级别加权
📋 核心要点
- 现有LLM安全对齐方法,如DPO,在抵抗jailbreak攻击时存在不足,其损失函数在拒绝学习方面并非最优。
- 论文提出双目标优化方法DOOR,解耦DPO目标为鲁棒拒绝训练和有害知识消除,提升模型安全性。
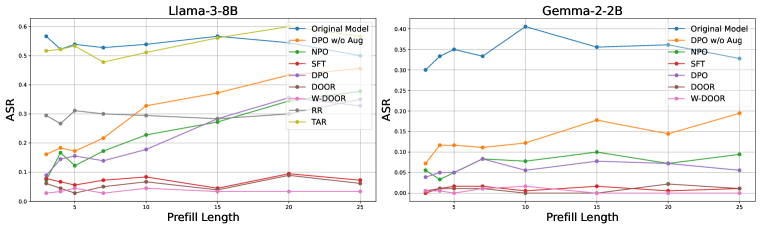
- 实验表明,DOOR显著提升LLM对各种jailbreak攻击的抵抗能力,并发现鲁棒性与token分布变化相关。
📝 摘要(中文)
现有大型语言模型(LLM)的训练时安全对齐技术仍然容易受到jailbreak攻击。直接偏好优化(DPO)作为一种广泛部署的对齐方法,在实验和理论背景下都表现出局限性,因为其损失函数对于拒绝学习而言并非最优。通过基于梯度的分析,我们发现了这些缺点,并提出了一种改进的安全对齐方法,将DPO目标分解为两个组成部分:(1)鲁棒的拒绝训练,即使在产生部分不安全生成时也鼓励拒绝;(2)有针对性地消除有害知识。这种方法显著提高了LLM对各种jailbreak攻击的鲁棒性,包括预填充、后缀和多轮攻击,涵盖了分布内和分布外场景。此外,我们引入了一种方法,通过为拒绝学习结合基于奖励的token级别加权机制来强调关键的拒绝token,从而进一步提高了对抗性利用的鲁棒性。我们的研究还表明,对jailbreak攻击的鲁棒性与训练过程中的token分布变化以及拒绝和有害token的内部表示相关,为LLM安全对齐的未来研究提供了有价值的方向。
🔬 方法详解
问题定义:现有的大型语言模型安全对齐方法,特别是基于直接偏好优化(DPO)的方法,在面对jailbreak攻击时表现出脆弱性。DPO的损失函数在拒绝学习方面存在缺陷,导致模型无法有效拒绝生成有害内容,使得攻击者可以通过精心设计的输入(如预填充、后缀攻击等)绕过安全机制。因此,需要一种更鲁棒的安全对齐方法,能够有效抵抗各种类型的jailbreak攻击。
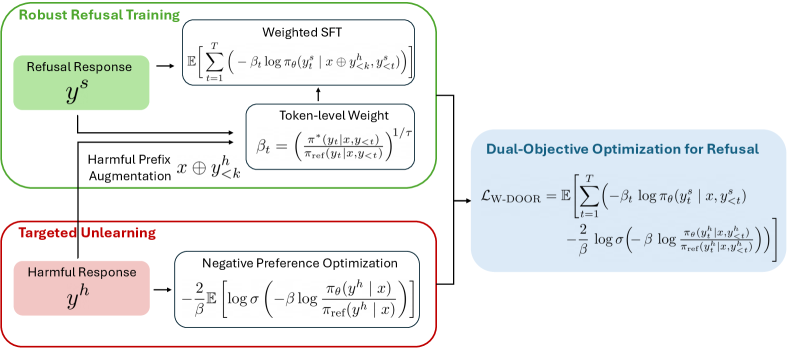
核心思路:论文的核心思路是将DPO的目标解耦为两个独立的组成部分:一是鲁棒的拒绝训练,即使在模型生成部分不安全内容的情况下,也鼓励模型拒绝生成;二是有针对性地消除有害知识,直接减少模型中与有害内容相关的知识。通过这种双目标优化,模型可以更有效地学习拒绝有害请求,并减少生成有害内容的可能性。
技术框架:DOOR方法的整体框架基于DPO,但对其损失函数进行了改进。主要包含以下几个阶段:1) 数据收集:收集包含安全回复和不安全回复的偏好数据。2) 鲁棒拒绝训练:使用改进的损失函数,鼓励模型对不安全回复进行拒绝,即使在生成部分不安全内容时。3) 有害知识消除:通过特定的优化策略,减少模型中与有害内容相关的知识。4) token级别加权:对关键的拒绝token进行加权,进一步提升拒绝学习的效果。
关键创新:DOOR方法最重要的技术创新点在于其双目标优化策略,将DPO的目标解耦为鲁棒拒绝训练和有害知识消除。这种解耦使得模型可以更专注于学习拒绝有害请求,并减少生成有害内容的可能性。此外,token级别加权机制也是一个重要的创新,通过强调关键的拒绝token,进一步提升了拒绝学习的效果。
关键设计:DOOR的关键设计包括:1) 改进的损失函数:用于鲁棒拒绝训练,鼓励模型在生成部分不安全内容时也进行拒绝。2) 有害知识消除策略:具体策略未知,但目标是减少模型中与有害内容相关的知识。3) token级别加权机制:基于奖励的token级别加权,对关键的拒绝token进行加权,提升拒绝学习效果。具体的加权方式和奖励函数未知。
🖼️ 关键图片
📊 实验亮点
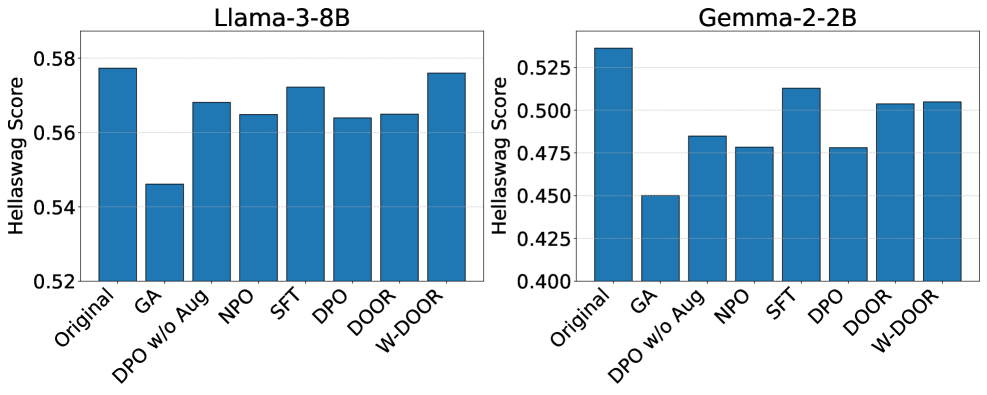
实验结果表明,DOOR方法显著提升了LLM对各种jailbreak攻击的抵抗能力,包括预填充、后缀和多轮攻击。在分布内和分布外场景下,DOOR均优于基线方法DPO。此外,研究还发现,对jailbreak攻击的鲁棒性与训练过程中的token分布变化以及拒绝和有害token的内部表示相关,为未来的研究提供了新的方向。
🎯 应用场景
该研究成果可应用于各种需要安全保障的大型语言模型应用场景,例如智能助手、聊天机器人、内容生成平台等。通过提高LLM抵抗jailbreak攻击的鲁棒性,可以有效防止模型生成有害、不当或具有误导性的内容,从而提升用户体验,降低安全风险,并促进LLM技术的健康发展。未来,该方法可以进一步扩展到其他安全对齐任务,例如减少模型偏见、提高模型透明度等。
📄 摘要(原文)
Existing training-time safety alignment techniques for large language models (LLMs) remain vulnerable to jailbreak attacks. Direct preference optimization (DPO), a widely deployed alignment method, exhibits limitations in both experimental and theoretical contexts as its loss function proves suboptimal for refusal learning. Through gradient-based analysis, we identify these shortcomings and propose an improved safety alignment that disentangles DPO objectives into two components: (1) robust refusal training, which encourages refusal even when partial unsafe generations are produced, and (2) targeted unlearning of harmful knowledge. This approach significantly increases LLM robustness against a wide range of jailbreak attacks, including prefilling, suffix, and multi-turn attacks across both in-distribution and out-of-distribution scenarios. Furthermore, we introduce a method to emphasize critical refusal tokens by incorporating a reward-based token-level weighting mechanism for refusal learning, which further improves the robustness against adversarial exploits. Our research also suggests that robustness to jailbreak attacks is correlated with token distribution shifts in the training process and internal representations of refusal and harmful tokens, offering valuable directions for future research in LLM safety alignment. The code is available at https://github.com/wicai24/DOOR-Alignment