Improving Neutral Point-of-View Generation with Data- and Parameter-Efficient RL
作者: Jessica Hoffmann, Christiane Ahlheim, Zac Yu, Aria Walfrand, Jarvis Jin, Marie Tano, Ahmad Beirami, Erin van Liemt, Nithum Thain, Hakim Sidahmed, Lucas Dixon
分类: cs.CL, cs.AI, cs.LG
发布日期: 2025-03-05 (更新: 2025-10-08)
💡 一句话要点
提出参数高效强化学习(PE-RL)方法,提升大语言模型生成中立观点回复的能力。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 中立观点生成 参数高效强化学习 大型语言模型 敏感话题 泛化能力
📋 核心要点
- 现有方法在训练LLM生成中立观点回复时,存在泛化性差、参数效率低等问题。
- 论文提出PE-RL方法,通过参数高效的强化学习,提升模型生成中立观点回复的质量和泛化能力。
- 实验表明,PE-RL在NPOV质量和关键语言特征上均优于现有方法,且具备更好的主题泛化能力。
📝 摘要(中文)
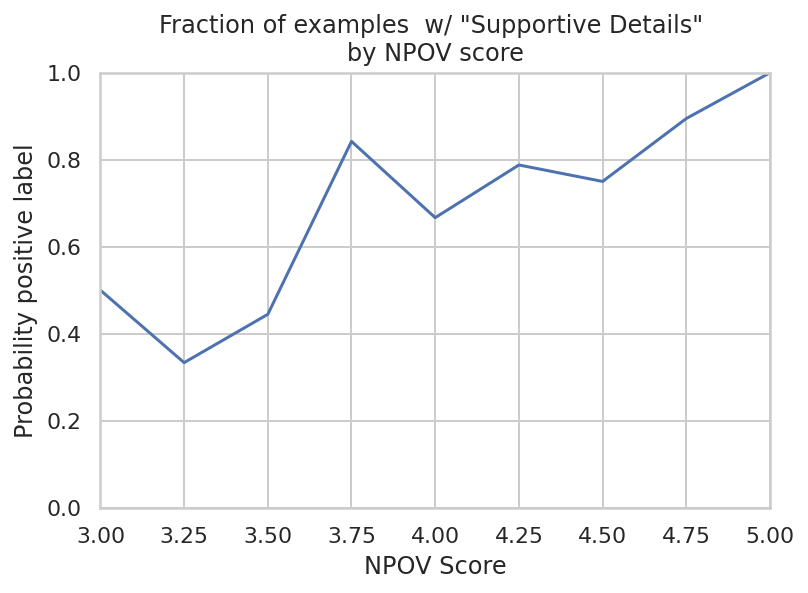
本文提出了一种参数高效强化学习(PE-RL)训练方案,显著提升大型语言模型(LLM)在敏感话题上生成中立观点(NPOV)回复的能力,使其回复更具信息量、多样性和公正性。通过与LoRA微调(最强基线)、SFT和RLHF等多种强基线对比,结果表明PE-RL不仅在整体NPOV质量上优于最强基线(97.06% → 99.08%),而且在语言学家认为区分“足够好”和“优秀”答案的关键特征上也表现更佳(支持性细节存在度:60.25% → 85.21%;避免过度简化:68.74% → 91.43%)。定性分析也证实了这一点。此外,评估还发现PE-RL的一个关键特性:与更新所有参数的方法不同,它可以泛化到未涉及的主题。最后,为了方便进一步研究,我们还发布了数据集SHQ-NPOV,并提供了一种通过迭代的人工同行评审和标注者培训来创建此类数据集的方法。
🔬 方法详解
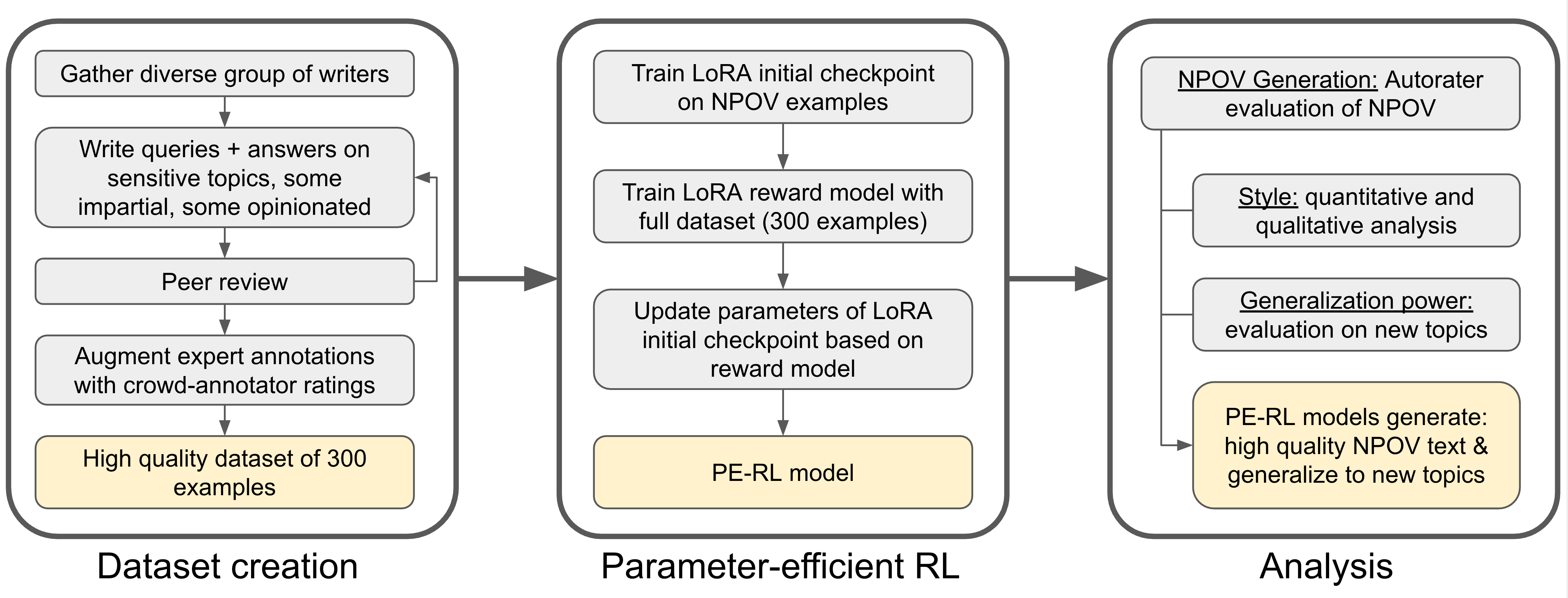
问题定义:论文旨在解决大型语言模型在处理敏感话题时,难以生成高质量中立观点回复的问题。现有方法,如全参数微调的RLHF,虽然可以提升回复质量,但参数效率低,容易过拟合特定主题,泛化能力较差。
核心思路:论文的核心思路是利用参数高效的强化学习(PE-RL)方法,在不更新所有模型参数的情况下,学习生成高质量的中立观点回复。通过限制可训练参数的数量,提高模型的泛化能力,使其能够处理未见过的敏感话题。
技术框架:整体框架包括:1) 使用SFT(Supervised Fine-Tuning)对LLM进行初步训练;2) 构建奖励模型,用于评估回复的中立性、信息量和多样性;3) 使用PE-RL算法,基于奖励模型对LLM进行强化学习训练,优化生成策略。PE-RL算法在训练过程中只更新部分参数,例如使用Adapter模块或LoRA等技术。
关键创新:关键创新在于将参数高效的强化学习应用于中立观点生成任务。与传统的全参数微调方法相比,PE-RL能够以更少的计算资源和数据量,达到甚至超过现有方法的性能,同时具备更好的泛化能力。
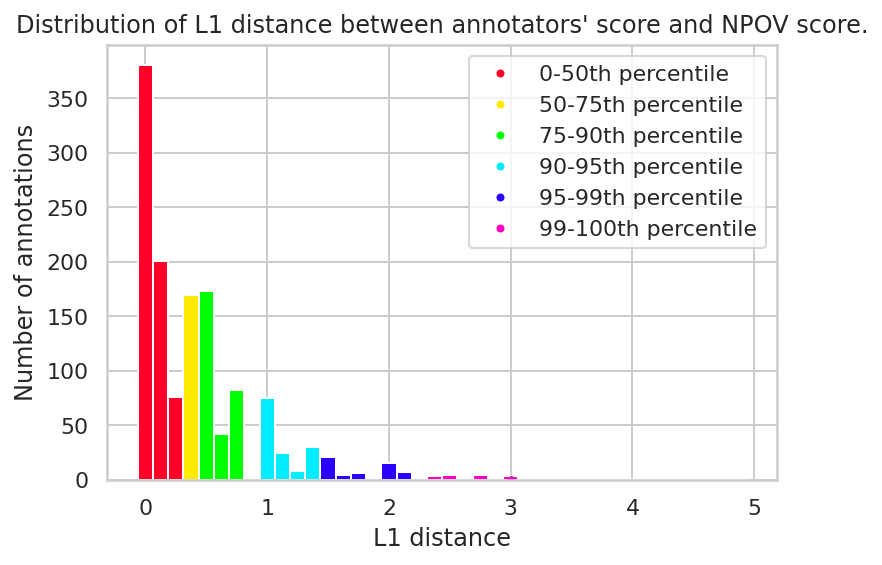
关键设计:论文可能采用了以下关键设计:1) 使用精心设计的奖励函数,鼓励模型生成信息丰富、避免过度简化、包含支持性细节的回复;2) 选择合适的PE-RL算法,例如Adapter或LoRA,并调整其参数,以达到最佳的性能和泛化能力;3) 使用迭代的人工同行评审和标注者培训方法,构建高质量的训练数据集SHQ-NPOV。
🖼️ 关键图片
📊 实验亮点
实验结果表明,PE-RL在整体NPOV质量上优于最强基线LoRA微调(97.06% → 99.08%),并且在支持性细节存在度(60.25% → 85.21%)和避免过度简化(68.74% → 91.43%)等关键语言特征上取得了显著提升。此外,PE-RL还展现出更好的主题泛化能力。
🎯 应用场景
该研究成果可应用于智能客服、舆情分析、内容审核等领域,帮助构建更客观、公正、负责任的AI系统。通过提升LLM生成中立观点回复的能力,可以减少信息偏见和误导,促进更健康的在线讨论环境,并为用户提供更全面、客观的信息。
📄 摘要(原文)
The paper shows that parameter-efficient reinforcement learning (PE-RL) is a highly effective training regime to improve large language models' (LLMs) ability to answer queries on sensitive topics with a Neutral Point of View (NPOV), i.e. to provide significantly more informative, diverse and impartial answers. This is shown by evaluating PE-RL and multiple strong baselines-including LoRA finetuning (strongest baseline), SFT and RLHF. PE-RL not only improves on overall NPOV quality compared to the strongest baseline ($97.06\%\rightarrow 99.08\%$), but also scores much higher on features linguists identify as key to separating sufficient answers from "great'' answers ($60.25\%\rightarrow 85.21\%$ for presence of supportive details, $68.74\%\rightarrow 91.43\%$ for absence of oversimplification). A qualitative analysis corroborates this. Moreover, our evaluation also finds a key property of PE-RL for this task: unlike methods that update all parameters, it generalises out of topic. Finally, to enable further studies we also release the dataset, SHQ-NPOV, and provide a methodology to create such datasets through iterative rounds of human peer-critique and annotator training.