PowerAttention: Exponentially Scaling of Receptive Fields for Effective Sparse Attention
作者: Lida Chen, Dong Xu, Chenxin An, Xintao Wang, Yikai Zhang, Jiangjie Chen, Zujie Liang, Feng Wei, Jiaqing Liang, Yanghua Xiao, Wei Wang
分类: cs.CL, cs.LG
发布日期: 2025-03-05
备注: for associated code, see https://github.com/w568w/PowerAttention
💡 一句话要点
提出PowerAttention以解决长上下文处理中的稀疏注意力问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 稀疏注意力 长上下文处理 大型语言模型 感受野扩展 自然语言处理 效率提升 机器学习
📋 核心要点
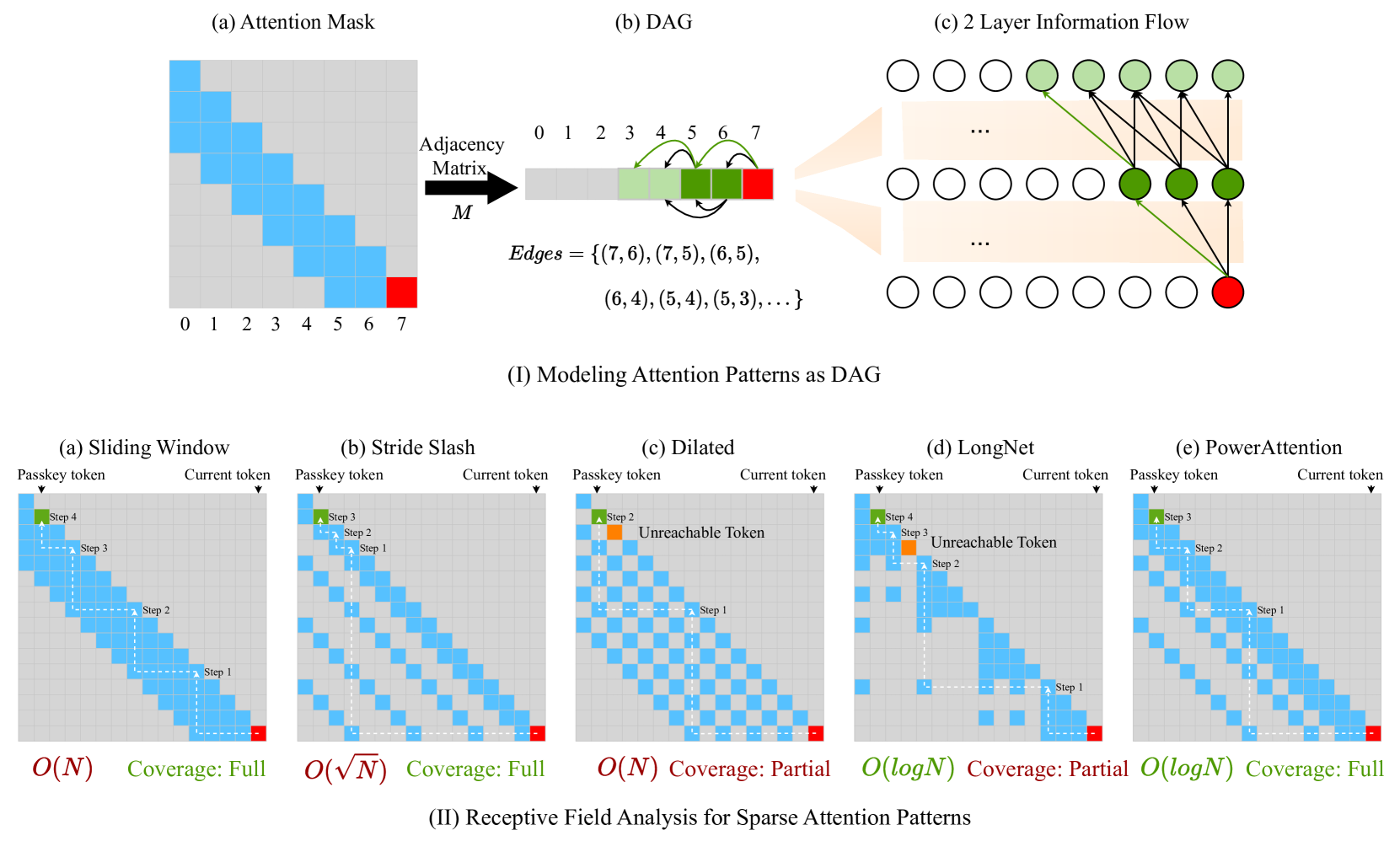
- 现有稀疏注意力方法在扩展感受野时存在有效上下文不完整和实现复杂的问题。
- 本文提出PowerAttention,通过理论分析实现感受野的指数级增长,确保上下文的完整性。
- 实验结果显示,PowerAttention在长距离依赖任务上性能提升5%至40%,且在时间复杂度上与滑动窗口注意力相当。
📝 摘要(中文)
大型语言模型(LLMs)在处理长上下文时面临效率瓶颈,主要源于注意力机制的二次复杂性。稀疏注意力方法提供了一个有前景的解决方案,但现有方法往往存在有效上下文不完整或实现复杂的问题。本文对自回归LLMs的稀疏注意力进行了全面分析,提出了PowerAttention,这是一种新颖的稀疏注意力设计,通过理论分析促进有效和完整的上下文扩展。PowerAttention在$d$层LLMs中实现了指数级的感受野增长,使每个输出token能够关注到$2^d$个token,确保了感受野的完整性和连续性。实验表明,PowerAttention在处理长距离依赖任务时,性能比现有静态稀疏注意力方法提升了5%至40%。
🔬 方法详解
问题定义:本文旨在解决大型语言模型在处理长上下文时,由于注意力机制的二次复杂性导致的效率瓶颈。现有稀疏注意力方法常常无法提供完整的有效上下文,或实现复杂,影响了模型性能。
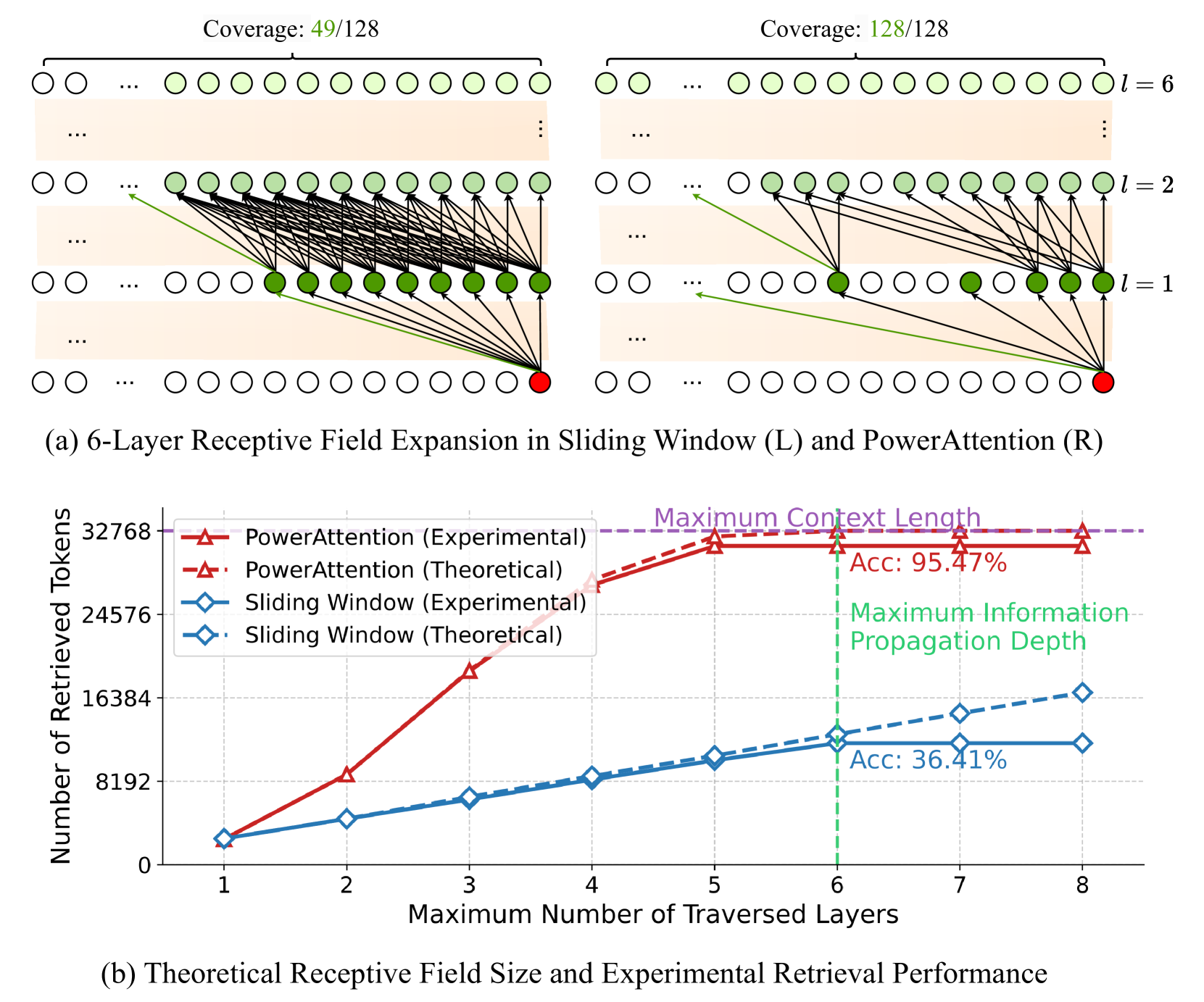
核心思路:论文提出的PowerAttention通过理论分析,设计了一种新颖的稀疏注意力机制,能够实现感受野的指数级扩展,使得每个输出token可以关注到$2^d$个token,从而确保上下文的完整性和连续性。
技术框架:PowerAttention的整体架构包括输入处理、稀疏注意力计算和输出生成三个主要模块。输入处理阶段负责将长上下文分割为适合模型处理的格式,稀疏注意力计算模块则实现了高效的注意力机制,最后输出生成模块将处理结果转化为最终的输出。
关键创新:PowerAttention的核心创新在于其能够实现感受野的指数级增长,这与现有方法的线性或静态扩展方式有本质区别,确保了模型在处理长距离依赖时的有效性。
关键设计:在设计中,PowerAttention采用了特定的参数设置以优化计算效率,并通过损失函数的调整来提升模型的学习能力。此外,网络结构上进行了优化,以适应稀疏注意力的计算需求。
🖼️ 关键图片

📊 实验亮点
实验结果表明,PowerAttention在多个长距离依赖任务上表现优异,相较于现有静态稀疏注意力方法提升了5%至40%的性能。同时,在预填充和解码阶段,PowerAttention的速度比动态稀疏注意力和全注意力快3.0倍,展现出其高效性。
🎯 应用场景
PowerAttention的设计具有广泛的应用潜力,尤其在需要处理长序列的自然语言处理任务中,如文本生成、机器翻译和信息检索等领域。其高效的稀疏注意力机制能够显著提升模型在长上下文处理中的性能,具有重要的实际价值和未来影响。
📄 摘要(原文)
Large Language Models (LLMs) face efficiency bottlenecks due to the quadratic complexity of the attention mechanism when processing long contexts. Sparse attention methods offer a promising solution, but existing approaches often suffer from incomplete effective context and/or require complex implementation of pipeline. We present a comprehensive analysis of sparse attention for autoregressive LLMs from the respective of receptive field, recognize the suboptimal nature of existing methods for expanding the receptive field, and introduce PowerAttention, a novel sparse attention design that facilitates effective and complete context extension through the theoretical analysis. PowerAttention achieves exponential receptive field growth in $d$-layer LLMs, allowing each output token to attend to $2^d$ tokens, ensuring completeness and continuity of the receptive field. Experiments demonstrate that PowerAttention outperforms existing static sparse attention methods by $5\sim 40\%$, especially on tasks demanding long-range dependencies like Passkey Retrieval and RULER, while maintaining a comparable time complexity to sliding window attention. Efficiency evaluations further highlight PowerAttention's superior speedup in both prefilling and decoding phases compared with dynamic sparse attentions and full attention ($3.0\times$ faster on 128K context), making it a highly effective and user-friendly solution for processing long sequences in LLMs.