Open-Source Large Language Models as Multilingual Crowdworkers: Synthesizing Open-Domain Dialogues in Several Languages With No Examples in Targets and No Machine Translation
作者: Ahmed Njifenjou, Virgile Sucal, Bassam Jabaian, Fabrice Lefèvre
分类: cs.CL, cs.AI, cs.HC, cs.LG
发布日期: 2025-03-05
💡 一句话要点
利用开源大语言模型作为多语众包工人,零样本合成多语言开放域对话
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多语言对话生成 大型语言模型 零样本学习 开放域对话 指令调优
📋 核心要点
- 现有开放域对话Agent主要集中于英语,多语言数据集构建成本高昂。
- 利用指令调优的LLM,无需显式机器翻译,直接生成多语言对话数据。
- 在PersonaChat数据集上验证,通过引入语音事件和共同基础增强对话真实性。
📝 摘要(中文)
开放域对话Agent领域的主流范式主要集中在英语上,包括模型和数据集。为微调而众包此类数据集需要大量的资金和时间投入,尤其是在涉及多种语言时。幸运的是,大型语言模型(LLM)的进步揭示了跨各种任务的多种可能性。具体来说,指令调优使LLM能够根据自然语言指令执行任务,有时甚至超过人类众包工作者的表现。此外,这些模型还能够在单个线程中以多种语言运行。因此,为了生成不同语言的新样本,我们建议利用这些能力来复制数据收集过程。我们引入了一个使用LLM在多种目标语言中生成开放域对话数据的pipeline,并以唯一的源语言提供演示。通过避免在此方法中显式的机器翻译,我们增强了对特定语言细微差别的遵守。我们将此方法应用于PersonaChat数据集。为了增强生成对话的开放性并模仿真实生活场景,我们添加了对应于说话者参与的对话类型的语音事件的概念,以及代表对话前提的共同基础的概念。
🔬 方法详解
问题定义:论文旨在解决多语言开放域对话数据稀缺的问题。现有方法依赖于人工标注或机器翻译,成本高昂且难以捕捉语言的细微差别。特别是,针对小语种的对话数据构建面临更大的挑战。因此,如何低成本、高质量地生成多语言开放域对话数据是本研究要解决的核心问题。
核心思路:论文的核心思路是利用大型语言模型(LLM)的强大生成能力和多语言处理能力,将其作为“多语众包工人”,直接生成目标语言的对话数据。通过指令调优,LLM能够理解并执行生成对话的任务,避免了传统方法中对人工标注或机器翻译的依赖,从而降低了成本并提高了效率。
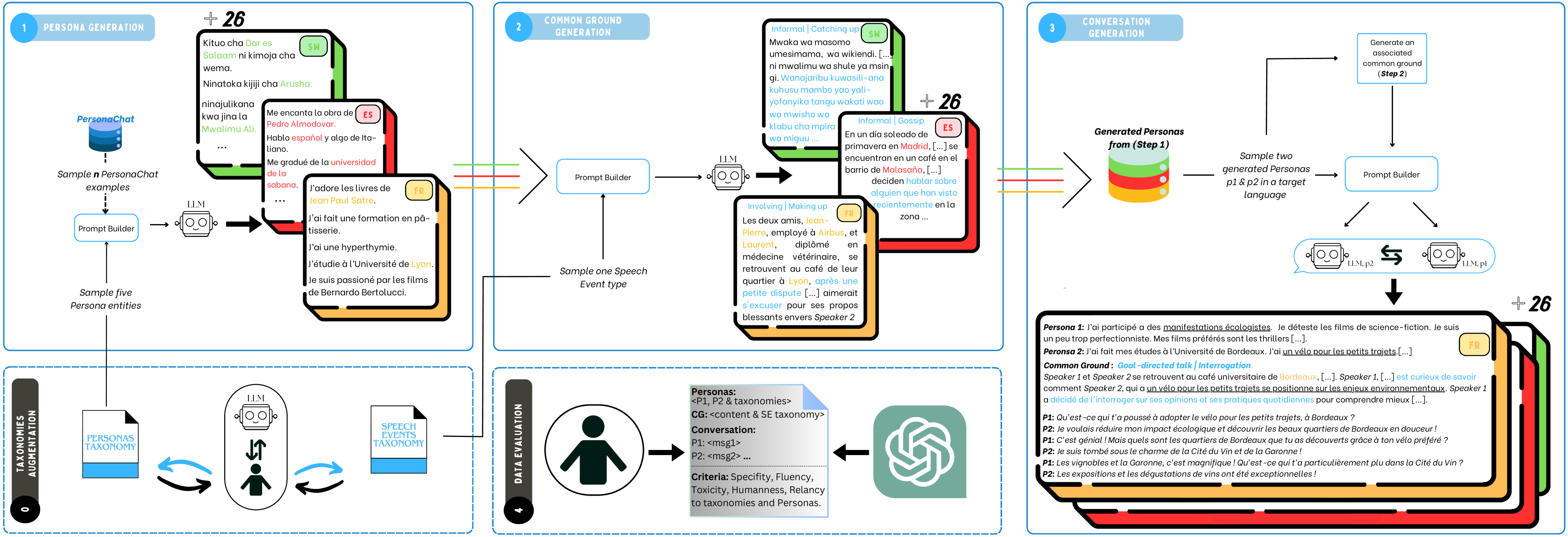
技术框架:论文提出的pipeline主要包含以下几个阶段: 1. 任务定义:明确定义对话生成的任务,例如设定角色、主题等。 2. 指令构建:使用自然语言构建指令,指导LLM生成符合要求的对话。 3. LLM生成:使用指令调优的LLM生成对话数据,可以指定目标语言。 4. 数据后处理:对生成的数据进行清洗和过滤,去除不符合要求的样本。 5. 评估:评估生成数据的质量,例如流畅度、相关性等。
关键创新:论文的关键创新在于: 1. 零样本多语言生成:无需目标语言的训练样本,即可生成高质量的对话数据。 2. 避免显式机器翻译:直接利用LLM的多语言能力,避免了机器翻译带来的信息损失和语言风格不一致的问题。 3. 引入语音事件和共同基础:增强了生成对话的开放性和真实性,使其更接近真实生活场景。
关键设计: 1. 指令设计:指令的设计至关重要,需要清晰、明确地指导LLM生成符合要求的对话。论文中使用了自然语言指令,例如“你是一个友好的助手,请与用户进行对话,讨论天气。” 2. LLM选择:选择具有较强生成能力和多语言处理能力的LLM,例如GPT-3、LaMDA等。 3. 数据后处理策略:设计有效的数据后处理策略,例如使用规则或模型过滤不符合要求的样本。
🖼️ 关键图片
📊 实验亮点
论文在PersonaChat数据集上进行了实验,验证了该方法的有效性。实验结果表明,使用LLM生成的对话数据具有较高的质量,能够生成流畅、相关性强的对话。通过引入语音事件和共同基础,生成对话的开放性和真实性得到了显著提升。虽然论文没有给出具体的性能指标,但定性分析表明,该方法能够有效生成多语言开放域对话数据。
🎯 应用场景
该研究成果可应用于多语言对话系统、跨文化交流、在线教育等领域。通过低成本生成多语言对话数据,可以促进小语种对话系统的发展,提升跨文化交流的效率,并为在线教育提供更丰富的教学资源。此外,该方法还可以应用于其他自然语言生成任务,例如文本摘要、机器翻译等。
📄 摘要(原文)
The prevailing paradigm in the domain of Open-Domain Dialogue agents predominantly focuses on the English language, encompassing both models and datasets. Furthermore, the financial and temporal investments required for crowdsourcing such datasets for finetuning are substantial, particularly when multiple languages are involved. Fortunately, advancements in Large Language Models (LLMs) have unveiled a plethora of possibilities across diverse tasks. Specifically, instruction-tuning has enabled LLMs to execute tasks based on natural language instructions, occasionally surpassing the performance of human crowdworkers. Additionally, these models possess the capability to function in various languages within a single thread. Consequently, to generate new samples in different languages, we propose leveraging these capabilities to replicate the data collection process. We introduce a pipeline for generating Open-Domain Dialogue data in multiple Target Languages using LLMs, with demonstrations provided in a unique Source Language. By eschewing explicit Machine Translation in this approach, we enhance the adherence to language-specific nuances. We apply this methodology to the PersonaChat dataset. To enhance the openness of generated dialogues and mimic real life scenarii, we added the notion of speech events corresponding to the type of conversation the speakers are involved in and also that of common ground which represents the premises of a conversation.