LINGOLY-TOO: Disentangling Reasoning from Knowledge with Templatised Orthographic Obfuscation
作者: Jude Khouja, Karolina Korgul, Simi Hellsten, Lingyi Yang, Vlad Neacsu, Harry Mayne, Ryan Kearns, Andrew Bean, Adam Mahdi
分类: cs.CL, cs.AI
发布日期: 2025-03-04 (更新: 2025-05-28)
💡 一句话要点
提出LINGOLY-TOO基准,通过模板化正字法混淆解耦语言模型中的推理与知识
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 推理能力 知识解耦 基准测试 正字法混淆
📋 核心要点
- 现有语言模型过度依赖记忆知识解决推理问题,导致推理能力评估失真。
- LINGOLY-TOO通过语言学规则生成问题变体,保留推理步骤,减少知识依赖。
- 实验表明模型在一致性推理上表现不佳,推理能力仍有提升空间。
📝 摘要(中文)
大型语言模型(LLMs)不断增长的知识和记忆能力使其能够直接利用先验知识解决许多推理任务,从而导致对其推理能力的评估过高。我们引入LINGOLY-TOO,这是一个具有挑战性的推理基准,它以自然语言为基础,旨在抵消非推理能力对推理评估的影响。通过使用语言学规则集,我们对用真实语言编写的推理问题进行排列,以生成大量问题变体。这些排列保留了每个解决方案所需的内在推理步骤,同时降低了模型直接利用其知识解决问题的可能性。实验和分析表明,模型可以绕过推理,直接从先验知识中获得答案。在一个奖励一致推理的指标上,所有模型的表现都很差,并且在问题排列中表现出很高的方差,这表明大型语言模型的推理能力仍然很脆弱。总的来说,该基准上的结果反映了推理时计算(ITC)模型的最新进展,但也表明仍有很大的改进空间。该基准是朝着更好衡量LLM推理能力迈出的一步,并为在开发推理基准时,将推理能力与模型内部知识分离的重要性提供了一个警示。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)在推理任务中过度依赖记忆知识,导致对其真实推理能力评估不准确的问题。现有方法难以区分模型是通过真正的推理,还是简单地回忆已知的答案来解决问题。这种现象使得评估LLMs的推理能力变得困难,并可能误导研究人员对模型能力的判断。
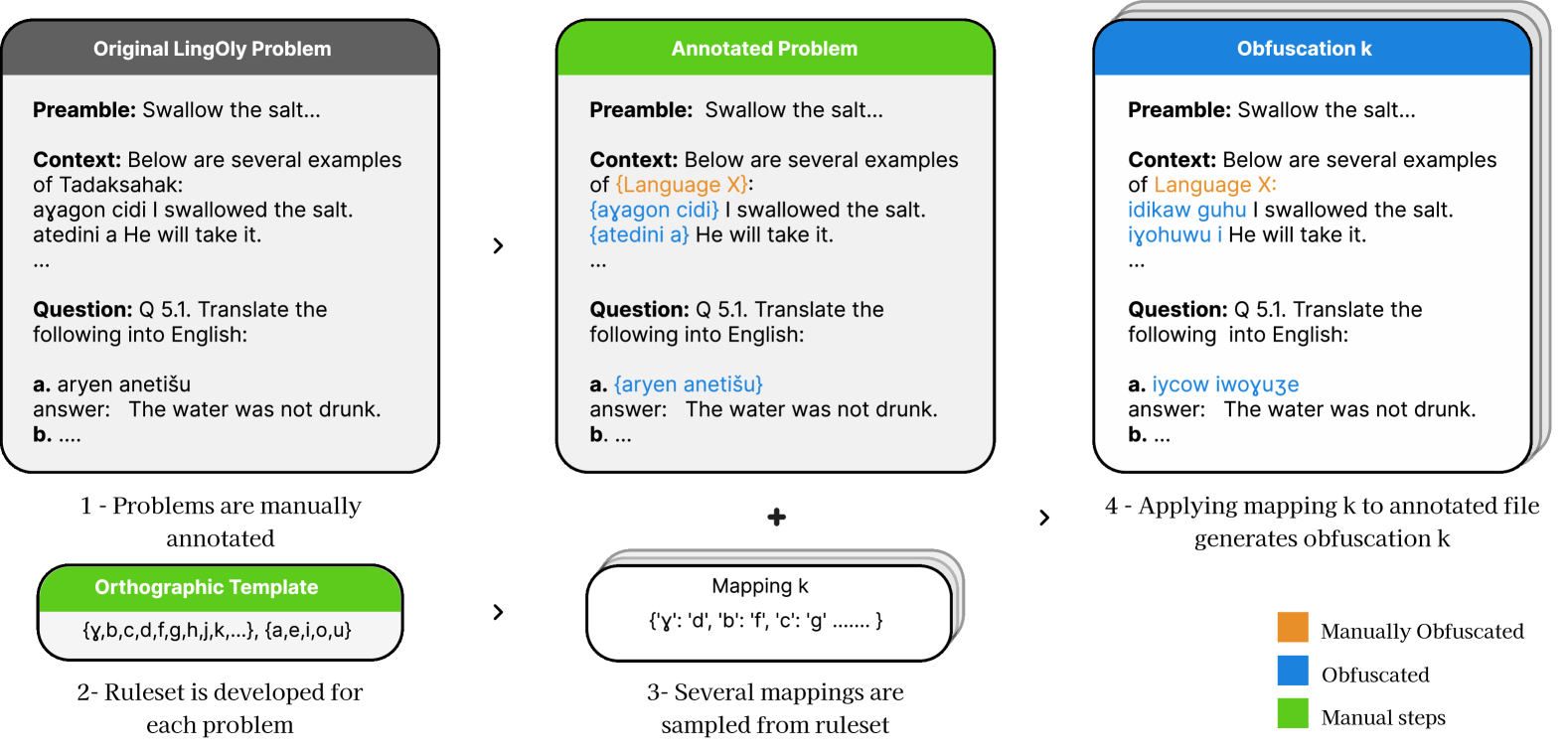
核心思路:论文的核心思路是通过对推理问题进行系统性的、语言学驱动的变换,生成大量语义相同但表面形式不同的问题变体。这些变体保留了原始问题所需的推理步骤,但改变了问题的表达方式,从而降低了模型直接从记忆中检索答案的可能性。通过评估模型在这些变体上的表现一致性,可以更准确地衡量其真正的推理能力。
技术框架:LINGOLY-TOO基准的构建流程主要包括以下几个阶段:1) 选择现有的推理数据集;2) 定义一系列基于语言学规则的变换规则,例如词序调整、同义词替换、句子结构调整等;3) 应用这些变换规则,为每个原始问题生成多个变体;4) 设计评估指标,用于衡量模型在不同问题变体上的表现一致性。整体框架旨在创建一个具有挑战性的推理基准,能够有效区分模型的推理能力和知识记忆能力。
关键创新:该论文的关键创新在于提出了一种基于模板化正字法混淆的方法,用于生成推理问题的变体。这种方法利用语言学知识,确保问题变体在语义上等价,但在表面形式上差异很大,从而有效地降低了模型直接从记忆中检索答案的可能性。与以往的简单数据增强方法相比,该方法更加系统化和可控,能够更好地控制问题变体的难度和多样性。
关键设计:LINGOLY-TOO的关键设计包括:1) 变换规则的选择:选择的变换规则需要能够有效地改变问题的表面形式,同时保持其语义不变;2) 变体数量的控制:生成的变体数量需要足够多,以覆盖不同的表达方式,但又不能过多,以免增加评估的计算成本;3) 评估指标的设计:评估指标需要能够有效地衡量模型在不同问题变体上的表现一致性,例如,可以计算模型在同一问题的所有变体上给出相同答案的比例。
🖼️ 关键图片
📊 实验亮点
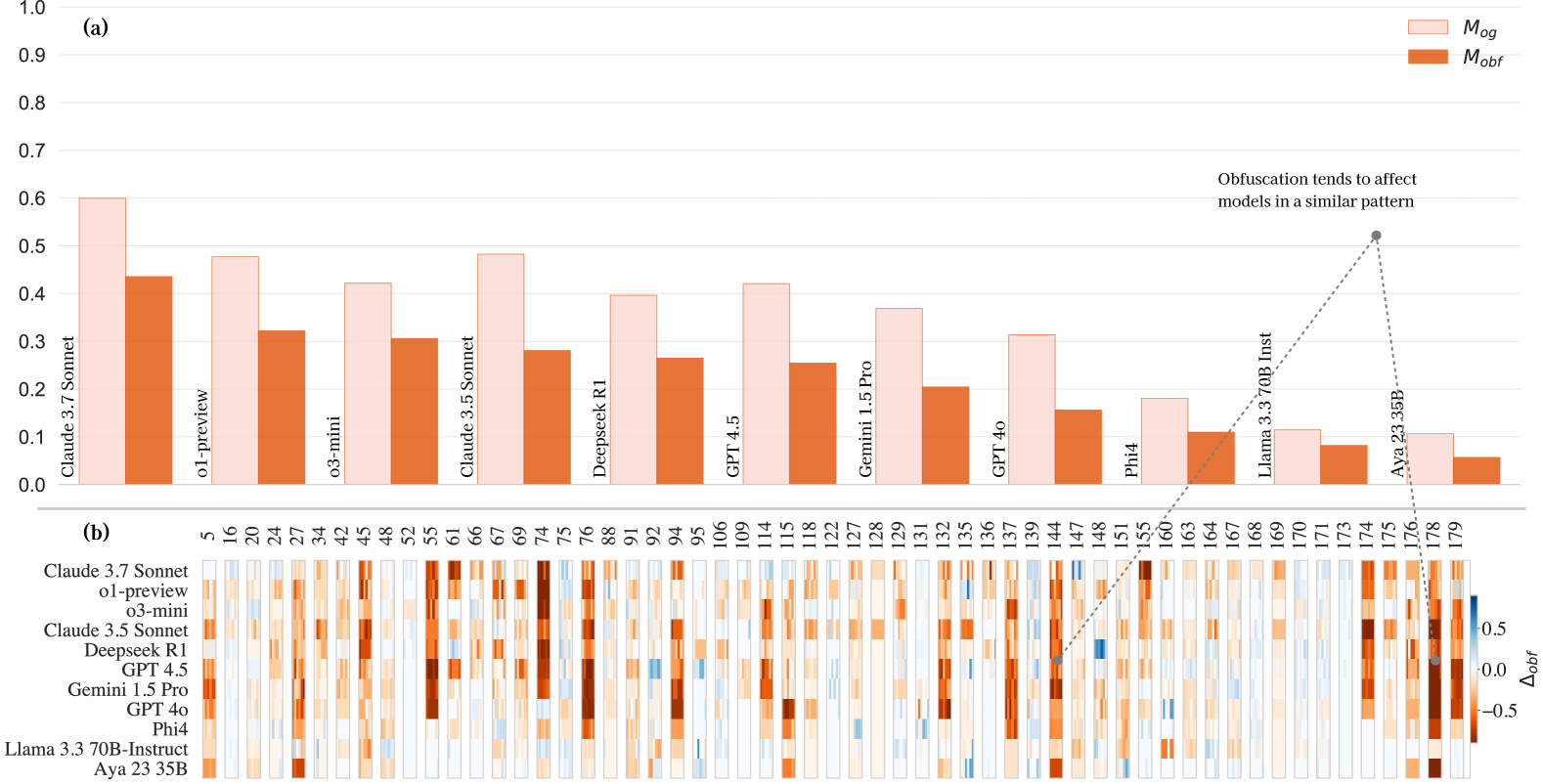
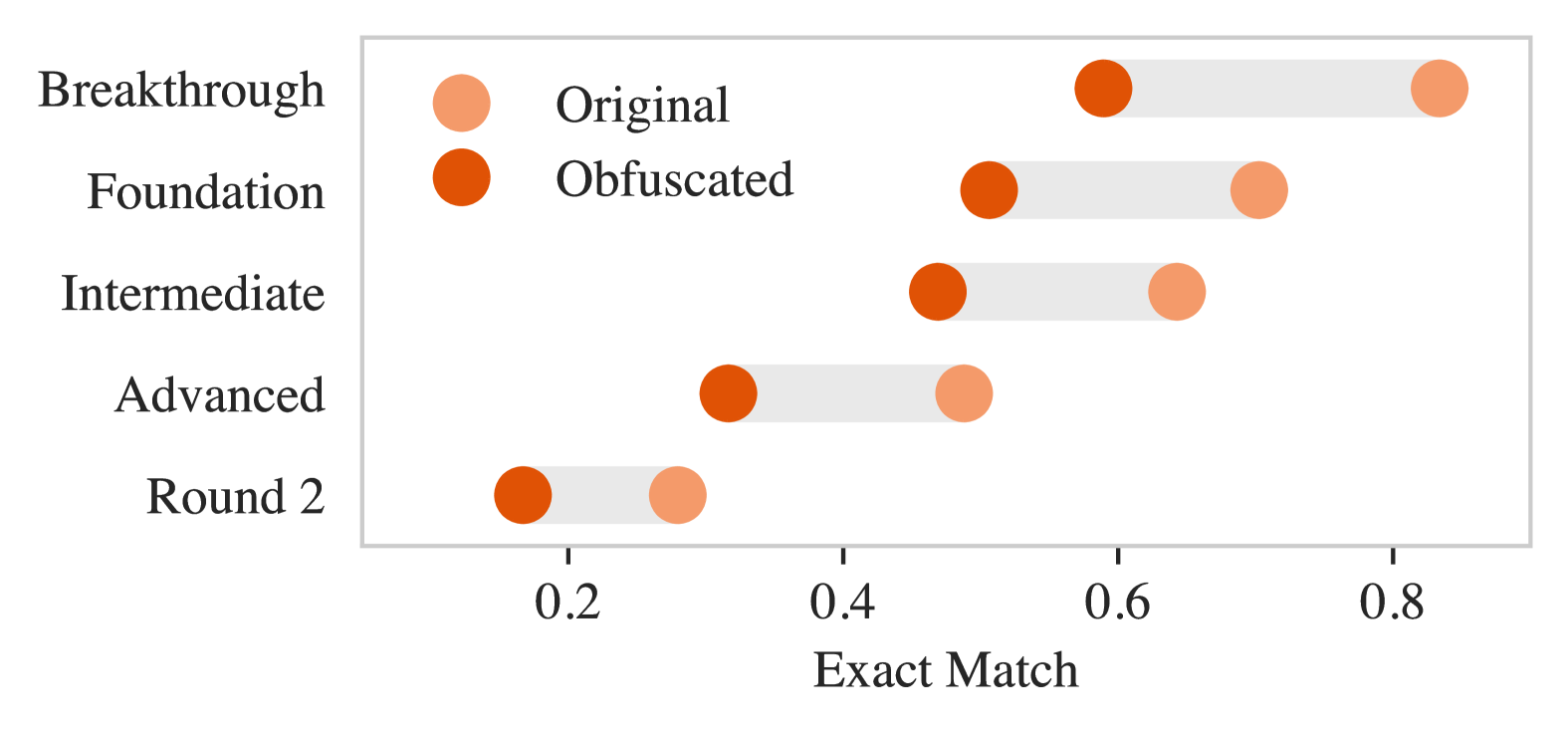
实验结果表明,即使是大型语言模型在LINGOLY-TOO基准上表现出较低的一致性推理能力,表明它们在很大程度上依赖于记忆知识而非真正的推理。在奖励一致性推理的指标上,所有模型的表现都很差,并且在问题排列中表现出很高的方差。这突显了当前LLM推理能力的脆弱性,并强调了开发更强大的推理机制的重要性。
🎯 应用场景
该研究成果可应用于更准确地评估和提升大型语言模型的推理能力。通过使用LINGOLY-TOO基准,研究人员可以更好地了解模型的推理机制,并开发出更有效的训练方法,从而提高模型在实际应用中的表现。此外,该方法还可以用于评估其他类型的AI系统,例如知识图谱和问答系统。
📄 摘要(原文)
The expanding knowledge and memorisation capacity of frontier language models allows them to solve many reasoning tasks directly by exploiting prior knowledge, leading to inflated estimates of their reasoning abilities. We introduce LINGOLY-TOO, a challenging reasoning benchmark grounded in natural language and designed to counteract the effect of non-reasoning abilities on reasoning estimates. Using linguistically informed rulesets, we permute reasoning problems written in real languages to generate numerous question variations. These permutations preserve the intrinsic reasoning steps required for each solution while reducing the likelihood problems are directly solvable with models' knowledge. Experiments and analyses show that models can circumvent reasoning and answer from prior knowledge. On a metric that rewards consistent reasoning, all models perform poorly and exhibit high variance across question permutations, indicating that Large Language Models' (LLMs) reasoning faculty remains brittle. Overall, results on the benchmark reflect the recent progress of Inference-Time Compute (ITC) models but suggest ample room for further improvement. The benchmark is a step towards better measurement of reasoning abilities of LLMs and offers a cautionary tale on the importance of disentangling reasoning abilities from models' internalised knowledge when developing reasoning benchmarks.