Teaching Your Models to Understand Code via Focal Preference Alignment
作者: Jie Wu, Haoling Li, Xin Zhang, Xiao Liu, Yangyu Huang, Jianwen Luo, Yizhen Zhang, Zuchao Li, Ruihang Chu, Yujiu Yang, Scarlett Li
分类: cs.CL, cs.AI, cs.LG
发布日期: 2025-03-04 (更新: 2025-10-09)
备注: Accepted by EMNLP'25
🔗 代码/项目: GITHUB
💡 一句话要点
提出Target-DPO,通过焦点偏好对齐提升代码大模型理解代码能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 代码大模型 偏好学习 直接偏好优化 错误修正 代码生成
📋 核心要点
- 现有代码大模型偏好学习方法缺乏细粒度,无法有效捕捉代码错误修正关系。
- Target-DPO通过显式定位错误区域并对齐相应token,模仿人类迭代调试过程。
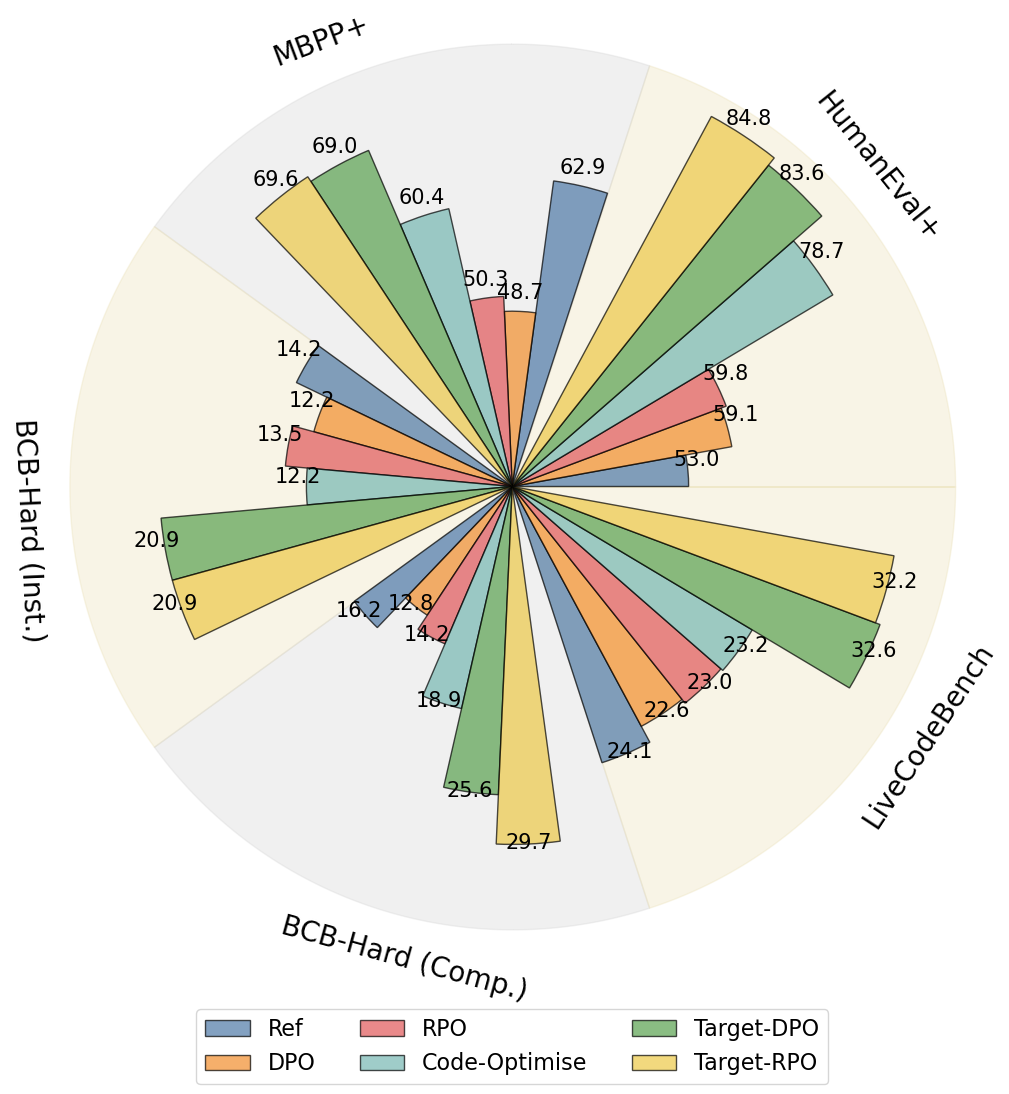
- 实验表明,Target-DPO显著提升了代码生成性能,并在BigCodeBench等任务上有所改进。
📝 摘要(中文)
本文提出了一种新的偏好对齐框架Target-DPO,旨在通过模仿人类迭代调试过程来改进代码大语言模型(Code LLMs)。现有方法通常基于测试用例成功率评估候选代码,并将通过率高的代码标记为正样本,反之则为负样本。然而,这种方法对整个失败的代码块进行对齐,缺乏精细度,无法捕捉有意义的错误修正关系,导致模型无法学习更具信息量的错误修正模式。Target-DPO显式地定位错误区域,并通过定制的DPO算法对齐相应的token。为了支持该方法,作者构建了CodeFlow数据集,其中样本被迭代地改进直到通过测试,修改过程捕捉了错误修正。大量实验表明,配备Target-DPO的各种Code LLM在代码生成方面取得了显著的性能提升,并在BigCodeBench等具有挑战性的任务上有所改进。深入分析表明,Target-DPO产生的错误更少。代码、模型和数据集已开源。
🔬 方法详解
问题定义:现有基于偏好学习的代码大模型训练方法,通常以测试用例的通过率作为奖励信号。这种方法将整个代码块作为训练样本,无法精确定位代码中的错误位置,导致模型学习到的错误修正模式不够精确,阻碍了模型性能的进一步提升。
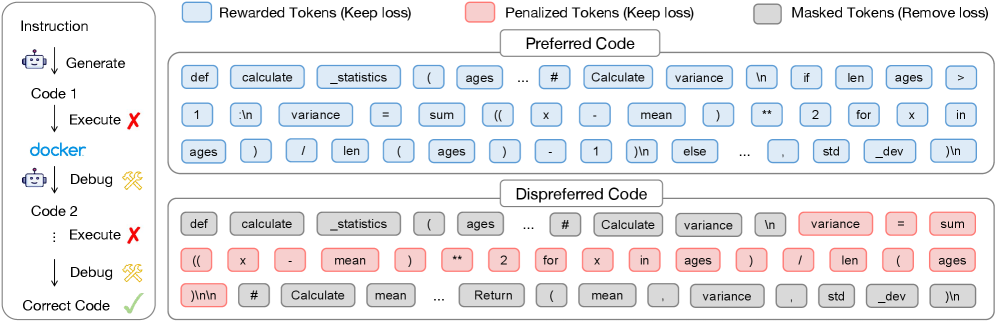
核心思路:Target-DPO的核心思路是模仿人类调试代码的过程,通过迭代地定位和修正代码中的错误,使模型能够学习到更精确的错误修正模式。该方法显式地识别代码中的错误区域,并针对这些区域进行偏好对齐,从而提高模型的代码理解和生成能力。
技术框架:Target-DPO框架主要包含以下几个阶段:1) 错误定位:使用某种方法(例如,基于测试用例失败信息)定位代码中的错误区域。2) 数据构建:构建包含错误代码和修正后代码的偏好数据集,其中修正后的代码作为正样本,错误代码作为负样本。3) 偏好对齐:使用定制的DPO算法,根据偏好数据集对代码大模型进行微调,使模型更倾向于生成修正后的代码。
关键创新:Target-DPO的关键创新在于其细粒度的错误定位和偏好对齐机制。与现有方法相比,Target-DPO能够更精确地识别代码中的错误,并针对这些错误进行有针对性的训练,从而提高模型的代码理解和生成能力。此外,CodeFlow数据集的构建也为Target-DPO的训练提供了高质量的数据支持。
关键设计:Target-DPO的关键设计包括:1) 错误定位方法:论文中可能使用了某种特定的错误定位方法,例如基于测试用例失败信息或静态代码分析。2) 偏好对齐算法:论文使用了定制的DPO算法,可能对DPO算法进行了修改,以适应代码生成任务的特点。3) CodeFlow数据集:该数据集包含迭代修正的代码样本,为Target-DPO的训练提供了高质量的数据支持。具体参数设置、损失函数和网络结构等技术细节未知,需要查阅论文原文。
🖼️ 关键图片

📊 实验亮点
实验结果表明,配备Target-DPO的代码大模型在代码生成方面取得了显著的性能提升。具体而言,Target-DPO在BigCodeBench等具有挑战性的任务上有所改进,并且生成的代码错误更少。具体的性能数据和提升幅度未知,需要查阅论文原文。
🎯 应用场景
Target-DPO可应用于各种代码生成场景,例如自动化代码补全、代码修复、代码翻译等。该方法能够提高代码大模型的代码理解和生成能力,从而提高软件开发的效率和质量。未来,Target-DPO有望被应用于更复杂的代码生成任务,例如自动化程序合成和代码优化。
📄 摘要(原文)
Preference learning extends the performance of Code LLMs beyond traditional supervised fine-tuning by leveraging relative quality comparisons. In existing approaches, a set of n candidate solutions is evaluated based on test case success rates, with the candidate demonstrating a higher pass rate being labeled as positive and its counterpart with a lower pass rate as negative. However, because this approach aligns entire failing code blocks rather than pinpointing specific errors, it lacks the granularity necessary to capture meaningful error-correction relationships. As a result, the model is unable to learn more informative error-correction patterns. To address these issues, we propose Target-DPO, a new preference alignment framework that mimics human iterative debugging to refine Code LLMs. Target-DPO explicitly locates error regions and aligns the corresponding tokens via a tailored DPO algorithm. To facilitate it, we introduce the CodeFlow dataset, where samples are iteratively refined until passing tests, with modifications capturing error corrections. Extensive experiments show that a diverse suite of Code LLMs equipped with Target-DPO achieves significant performance gains in code generation and improves on challenging tasks like BigCodeBench. In-depth analysis reveals that Target-DPO yields fewer errors. Code, model and datasets are in: https://github.com/JieWu02/Target-DPO.