Put the Space of LoRA Initialization to the Extreme to Preserve Pre-trained Knowledge
作者: Pengwei Tang, Xiaolin Hu, Yong Liu, Lizhong Ding, Dongjie Zhang, Xing Wu, Debing Zhang
分类: cs.CL
发布日期: 2025-03-04 (更新: 2026-01-12)
备注: Accepted at AAAI 2026. We rediscovered why our approach works from the perspective of the LoRA initialization space. Accordingly, we added new experiments and also removed inappropriate experiments (those without catastrophic forgetting)
🔗 代码/项目: GITHUB
💡 一句话要点
提出LoRA-Null,通过激活空空间初始化LoRA,有效缓解大语言模型微调中的灾难性遗忘。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: LoRA 参数高效微调 灾难性遗忘 大语言模型 激活零空间 知识保留 模型初始化
📋 核心要点
- 大语言模型微调中的灾难性遗忘问题依然严峻,现有LoRA初始化方法未能充分利用与预训练知识正交的初始化空间。
- LoRA-Null的核心思想是在输入激活的零空间中初始化LoRA,从而更精确地排除预训练知识,保留模型原有能力。
- 实验表明,LoRA-Null在保留预训练知识的同时,实现了良好的微调性能,有效缓解了灾难性遗忘现象。
📝 摘要(中文)
低秩适应(LoRA)是大语言模型(LLMs)参数高效微调的主流方法,但仍存在灾难性遗忘问题。最近的研究表明,专门的LoRA初始化可以缓解灾难性遗忘。目前有两种LoRA初始化方法旨在防止微调期间的知识遗忘:(1)使残差权重接近预训练权重,(2)确保LoRA初始化空间与预训练知识正交。前者是当前方法努力实现的目标,而后者重要性未被充分认识。我们发现LoRA初始化空间是保持预训练知识的关键,而非残差权重。现有方法如MiLoRA提出使LoRA初始化空间与预训练权重正交。然而,MiLoRA利用预训练权重的零空间。与预训练权重相比,预训练知识的输入激活考虑了所有先前层的参数以及输入数据,而预训练权重仅包含当前层的信息。此外,我们发现输入激活的有效秩远小于预训练权重的有效秩。因此,与权重的零空间相比,激活的零空间更准确,包含的预训练知识信息更少。基于此,我们提出了LoRA-Null,该方法在激活的零空间中初始化LoRA。实验结果表明,LoRA-Null有效地保留了LLM的预训练世界知识,同时实现了良好的微调性能。
🔬 方法详解
问题定义:论文旨在解决大语言模型(LLMs)在使用LoRA进行参数高效微调时出现的灾难性遗忘问题。现有方法,如MiLoRA,尝试通过使LoRA初始化空间与预训练权重正交来缓解这个问题,但它们依赖于预训练权重的零空间,这不够精确,因为预训练权重仅包含当前层的信息,而忽略了之前层的影响。
核心思路:论文的核心思路是利用输入激活的零空间来初始化LoRA。输入激活包含了所有先前层的参数以及输入数据的信息,因此其零空间能更准确地排除预训练知识。此外,输入激活的有效秩通常远小于预训练权重的有效秩,这意味着激活的零空间包含的预训练知识信息更少,从而能更好地保留模型的原有能力。
技术框架:LoRA-Null的整体框架是在LoRA微调过程中,不再使用传统的随机初始化或基于权重的初始化方法,而是计算输入激活的零空间,并将LoRA矩阵初始化在这个零空间中。具体流程包括:1. 获取预训练模型的输入激活;2. 计算输入激活的零空间;3. 在该零空间中初始化LoRA矩阵;4. 进行正常的LoRA微调过程。
关键创新:最重要的技术创新点在于使用输入激活的零空间进行LoRA初始化,而不是像现有方法那样使用预训练权重的零空间。这种方法能够更精确地排除预训练知识,从而更好地保留模型的原有能力,并缓解灾难性遗忘。与现有方法的本质区别在于,LoRA-Null考虑了所有先前层的影响,而不仅仅是当前层的信息。
关键设计:关键设计在于如何有效地计算输入激活的零空间。论文可能采用了某种降维或近似计算方法来处理高维激活数据。此外,LoRA的秩(rank)的选择也是一个关键参数,需要根据具体任务和数据集进行调整。论文可能还涉及一些正则化技术,以防止LoRA矩阵过于复杂,从而进一步提高模型的泛化能力。
🖼️ 关键图片

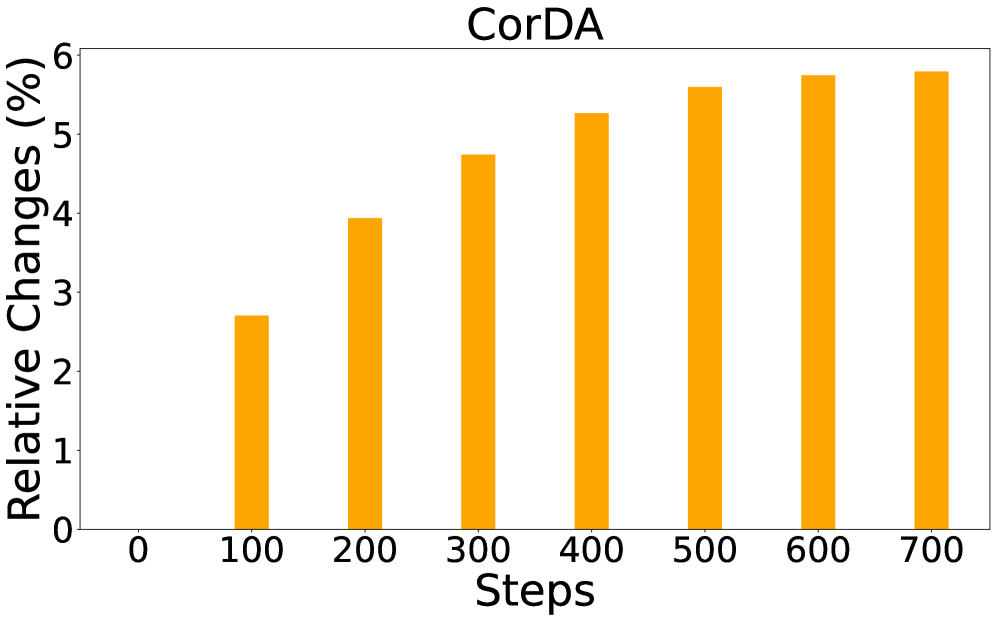
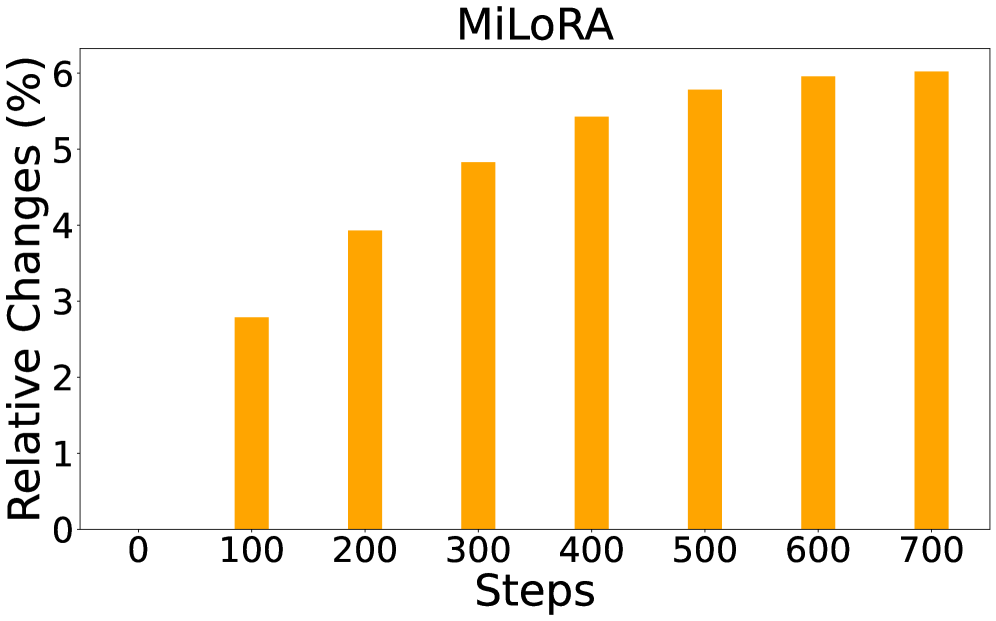
📊 实验亮点
LoRA-Null通过在激活的零空间中初始化LoRA,在保留预训练世界知识方面表现出色。实验结果表明,该方法在各种任务上都优于现有的LoRA初始化方法,例如MiLoRA,并在缓解灾难性遗忘方面取得了显著的提升。具体的性能数据和提升幅度需要在论文的实验部分查找。
🎯 应用场景
LoRA-Null可广泛应用于各种需要对大语言模型进行参数高效微调的场景,例如领域知识迁移、任务特定优化等。该方法能够有效缓解灾难性遗忘,保证模型在适应新任务的同时,保留原有的通用知识,具有重要的实际应用价值和潜力。未来可进一步探索其在多任务学习、持续学习等领域的应用。
📄 摘要(原文)
Low-Rank Adaptation (LoRA) is the leading parameter-efficient fine-tuning method for Large Language Models (LLMs), but it still suffers from catastrophic forgetting. Recent work has shown that specialized LoRA initialization can alleviate catastrophic forgetting. There are currently two approaches to LoRA initialization aimed at preventing knowledge forgetting during fine-tuning: (1) making residual weights close to pre-trained weights, and (2) ensuring the space of LoRA initialization is orthogonal to pre-trained knowledge. The former is what current methods strive to achieve, while the importance of the latter is not sufficiently recognized. We find that the space of LoRA initialization is the key to preserving pre-trained knowledge rather than the residual weights. Existing methods like MiLoRA propose making the LoRA initialization space orthogonal to pre-trained weights. However, MiLoRA utilizes the null space of pre-trained weights. Compared to pre-trained weights, the input activations of pre-trained knowledge take into account the parameters of all previous layers as well as the input data, while pre-trained weights only contain information from the current layer. Moreover, we find that the effective ranks of input activations are much smaller than those of pre-trained weights. Thus, the null space of activations is more accurate and contains less pre-trained knowledge information compared to that of weights. Based on these, we introduce LoRA-Null, our proposed method that initializes LoRA in the null space of activations. Experimental results show that LoRA-Null effectively preserves the pre-trained world knowledge of LLMs while achieving good fine-tuning performance, as evidenced by extensive experiments. Code is available at {https://github.com/HungerPWAY/LoRA-Null}.