Towards Event Extraction with Massive Types: LLM-based Collaborative Annotation and Partitioning Extraction
作者: Wenxuan Liu, Zixuan Li, Long Bai, Yuxin Zuo, Daozhu Xu, Xiaolong Jin, Jiafeng Guo, Xueqi Cheng
分类: cs.CL, cs.AI
发布日期: 2025-03-04
备注: Work in progress
💡 一句话要点
提出基于LLM的协同标注与划分抽取方法,用于解决大规模类型事件抽取问题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 事件抽取 大型语言模型 协同标注 划分抽取 零样本学习
📋 核心要点
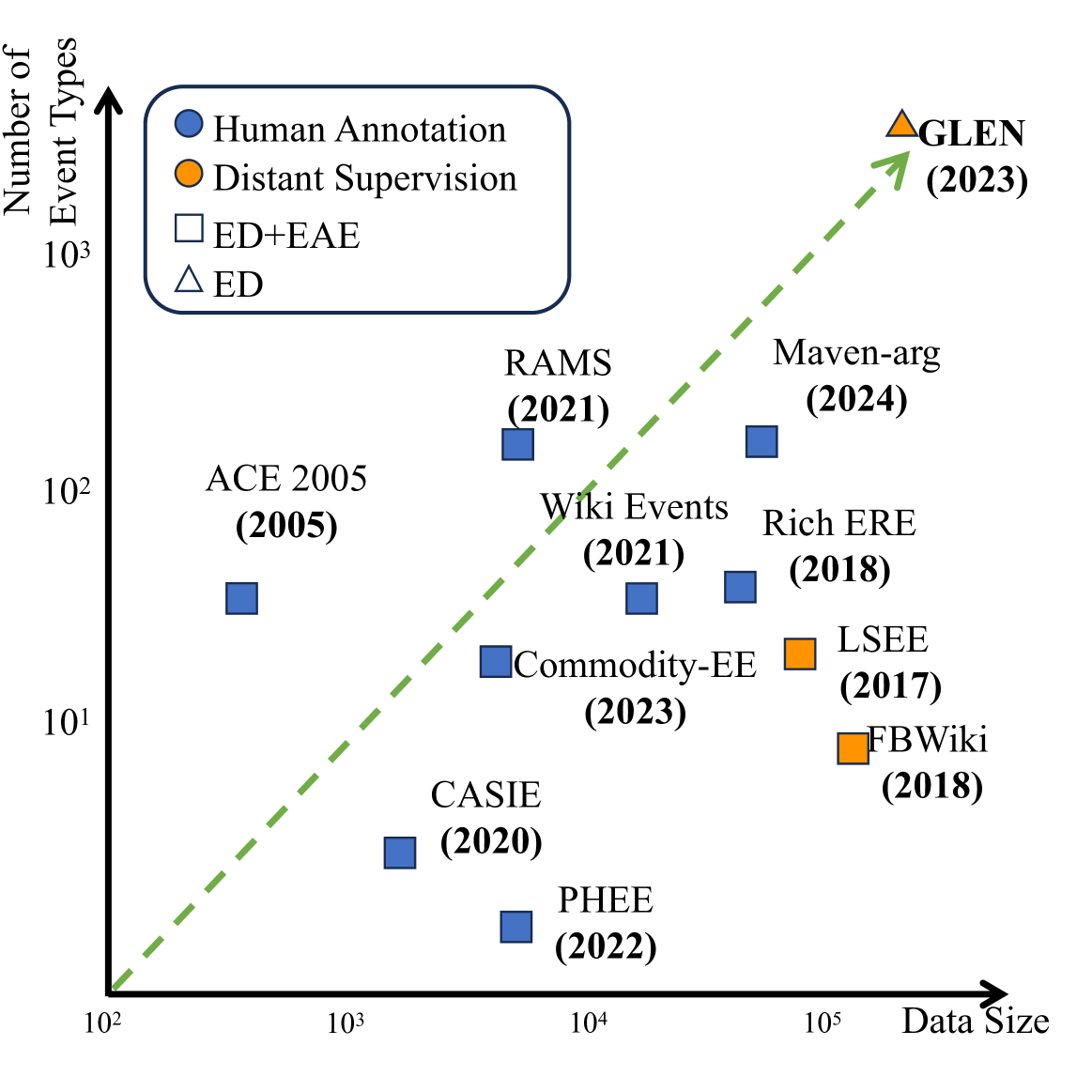
- 现有事件抽取方法难以有效处理大规模事件类型,标注效率和抽取性能均面临挑战。
- 论文提出基于LLM的协同标注方法和划分抽取方法,构建大规模数据集并提升抽取性能。
- 实验结果表明,该方法在监督和零样本设置下均显著优于现有方法,展现了强大的泛化能力。
📝 摘要(中文)
本文旨在解决事件抽取(EE)中长期存在的大规模类型处理难题。为此,论文提出了两种创新方法。首先,针对高效标注的缺失,提出了一种基于大型语言模型(LLM)的协同标注方法,通过多个LLM之间的协作,优化远程监督的触发词标注,并进行论元标注,最终通过投票机制整合不同LLM的标注偏好,构建了迄今为止最大的事件抽取数据集EEMT,包含超过20万个样本、3465个事件类型和6297个角色类型。其次,针对抽取方法不足的问题,提出了一种基于LLM的划分事件抽取方法LLM-PEE。该方法通过召回候选事件类型,并将其分割成多个分区,利用LLM进行事件抽取,从而克服了LLM的上下文长度限制。在监督设置下,LLM-PEE在事件检测和论元抽取方面分别优于现有最佳方法5.4和6.1。在零样本设置下,LLM-PEE相比主流LLM取得了高达12.9的提升,展示了其强大的泛化能力。
🔬 方法详解
问题定义:现有事件抽取系统难以处理大规模事件类型,主要痛点在于缺乏高效的标注方法和能够处理大规模类型的抽取方法。传统标注方法成本高昂,而现有抽取模型在面对大量事件类型时,性能显著下降。
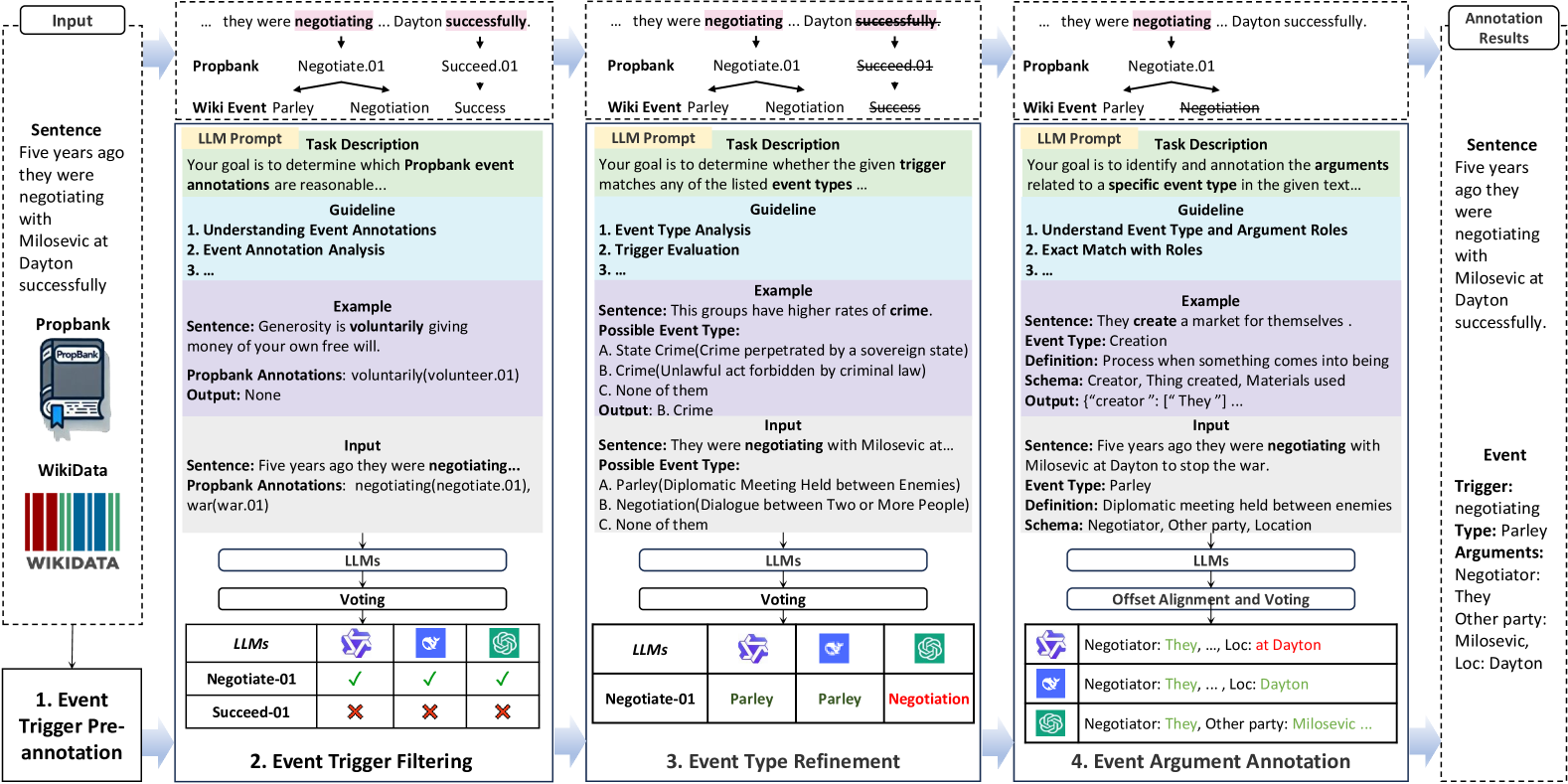
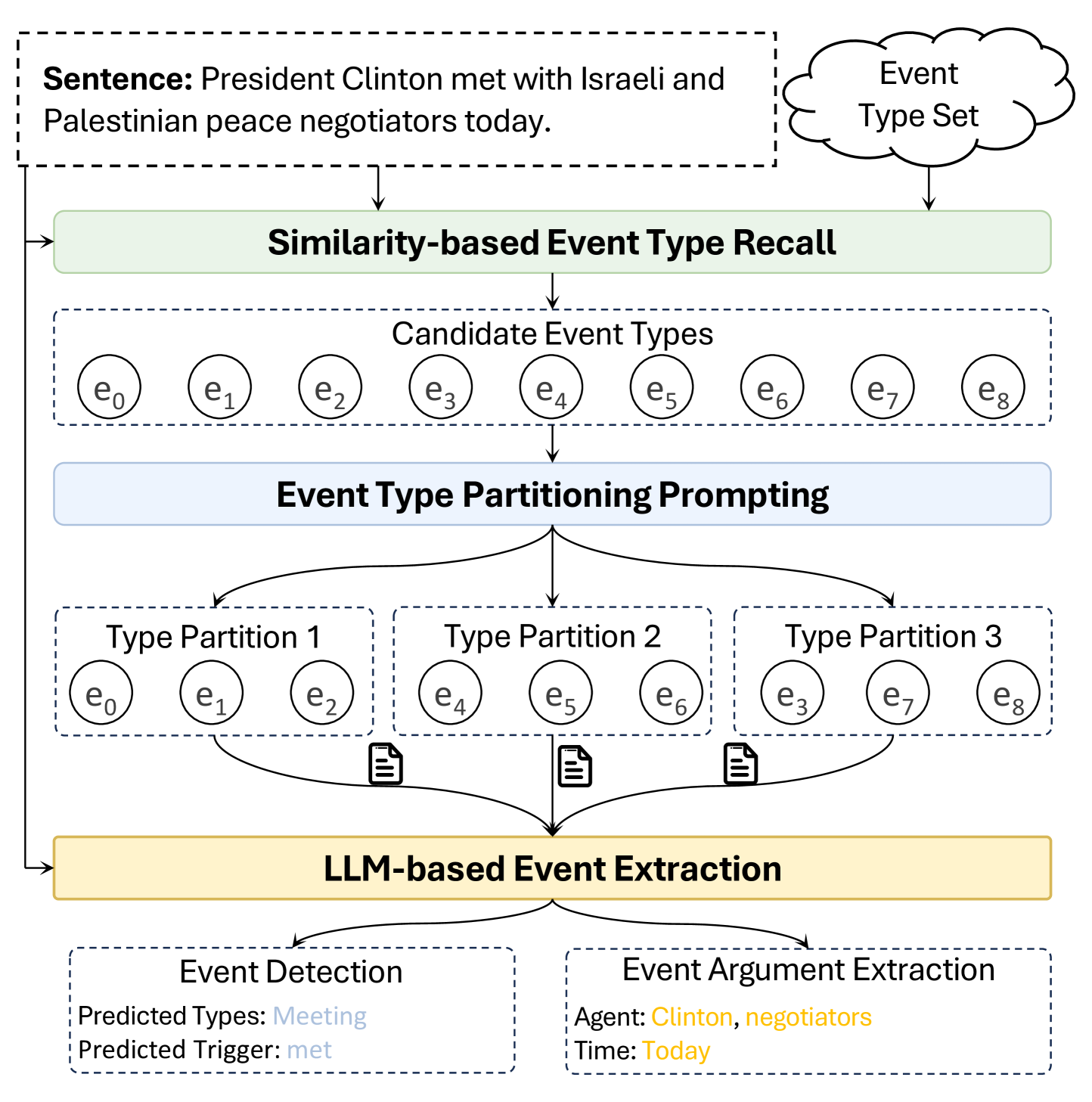
核心思路:论文的核心思路是利用LLM的强大能力,通过协同标注降低标注成本,并通过划分策略克服LLM的上下文长度限制,从而实现对大规模事件类型的有效抽取。协同标注旨在提高标注效率和质量,划分抽取旨在提升LLM在长文本和多类型场景下的抽取性能。
技术框架:整体框架包含两个主要部分:1) 基于LLM的协同标注:多个LLM对数据进行标注,包括触发词和论元标注,然后通过投票机制整合标注结果,生成高质量的标注数据。2) 基于LLM的划分事件抽取(LLM-PEE):首先召回候选事件类型,然后将事件类型划分为多个分区,每个分区由LLM独立进行事件抽取,最后整合各个分区的抽取结果。
关键创新:论文的关键创新在于:1) 提出了一种基于LLM的协同标注方法,显著降低了标注成本并提高了标注质量。2) 提出了一种基于LLM的划分事件抽取方法,有效克服了LLM的上下文长度限制,使其能够处理大规模事件类型。3) 构建了迄今为止最大的事件抽取数据集EEMT。
关键设计:在协同标注阶段,采用了多个不同类型的LLM,并设计了投票机制来整合不同LLM的标注结果。在LLM-PEE中,采用了基于相似度的事件类型划分策略,以保证每个分区内的事件类型具有一定的相关性。具体参数设置和损失函数细节在论文中未详细说明,属于未知信息。
🖼️ 关键图片
📊 实验亮点
实验结果表明,LLM-PEE在监督设置下,事件检测和论元抽取方面分别优于现有最佳方法5.4和6.1。在零样本设置下,LLM-PEE相比主流LLM取得了高达12.9的提升,充分证明了其优越的性能和强大的泛化能力。EEMT数据集的构建也为事件抽取领域的研究提供了宝贵资源。
🎯 应用场景
该研究成果可应用于信息抽取、知识图谱构建、舆情分析、智能问答等领域。通过构建大规模事件抽取系统,可以自动从海量文本数据中提取事件信息,为下游应用提供高质量的数据支持,例如,可以用于构建更全面的知识图谱,提升舆情分析的准确性,以及改进智能问答系统的回答质量。
📄 摘要(原文)
Developing a general-purpose extraction system that can extract events with massive types is a long-standing target in Event Extraction (EE). In doing so, the challenge comes from two aspects: 1) The absence of an efficient and effective annotation method. 2) The absence of a powerful extraction method can handle massive types. For the first challenge, we propose a collaborative annotation method based on Large Language Models (LLMs). Through collaboration among multiple LLMs, it first refines annotations of trigger words from distant supervision and then carries out argument annotation. Next, a voting phase consolidates the annotation preferences across different LLMs. Finally, we create the EEMT dataset, the largest EE dataset to date, featuring over 200,000 samples, 3,465 event types, and 6,297 role types. For the second challenge, we propose an LLM-based Partitioning EE method called LLM-PEE. To overcome the limited context length of LLMs, LLM-PEE first recalls candidate event types and then splits them into multiple partitions for LLMs to extract events. The results in the supervised setting show that LLM-PEE outperforms the state-of-the-art methods by 5.4 in event detection and 6.1 in argument extraction. In the zero-shot setting, LLM-PEE achieves up to 12.9 improvement compared to mainstream LLMs, demonstrating its strong generalization capabilities.