Rewarding Doubt: A Reinforcement Learning Approach to Calibrated Confidence Expression of Large Language Models
作者: Paul Stangel, David Bani-Harouni, Chantal Pellegrini, Ege Özsoy, Kamilia Zaripova, Matthias Keicher, Nassir Navab
分类: cs.CL, cs.AI
发布日期: 2025-03-04 (更新: 2025-05-23)
💡 一句话要点
提出基于强化学习的LLM置信度校准方法,提升模型回答事实性问题的可靠性。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 置信度校准 强化学习 对数评分规则 事实性问题
📋 核心要点
- 大型语言模型需要准确表达对其答案的置信度,以确保安全和可信的使用,但现有方法通常缺乏有效的置信度校准。
- 论文提出一种基于强化学习的方法,通过优化奖励函数,直接微调LLM,使其在生成答案的同时输出校准后的置信度估计。
- 实验表明,该方法显著提高了模型的置信度校准能力,并且能够泛化到未见过的任务,无需额外微调。
📝 摘要(中文)
本文提出了一种新颖的强化学习方法,用于直接微调大型语言模型(LLM),使其在回答事实性问题时能够表达校准后的置信度估计。该方法优化了一个基于对数评分规则的奖励函数,明确惩罚过度自信和欠自信的情况,从而鼓励模型将其置信度估计与实际预测准确率对齐。在所设计的奖励机制下,最优策略将产生完美校准的置信度表达。与以往将置信度估计与响应生成分离的方法不同,本文方法将置信度校准无缝集成到LLM的生成过程中。实验结果表明,使用该方法训练的模型在校准方面表现出显著改善,并且能够泛化到未见过的任务,无需进一步微调,表明模型具备了通用的置信度感知能力。训练和评估代码将在接受后公开。
🔬 方法详解
问题定义:现有的大型语言模型在生成答案时,通常缺乏对其答案置信度的准确表达。这意味着模型可能会对错误的答案表现出过高的置信度,或者对正确的答案表现出过低的置信度。这种不准确的置信度表达会降低模型的可信度,并可能导致用户做出错误的决策。因此,如何让LLM能够准确地表达其答案的置信度是一个重要的研究问题。
核心思路:本文的核心思路是利用强化学习,直接微调LLM,使其在生成答案的同时,也能够生成一个校准后的置信度估计。通过设计一个基于对数评分规则的奖励函数,明确地惩罚过度自信和欠自信的情况,从而鼓励模型将其置信度估计与实际预测准确率对齐。
技术框架:该方法将LLM视为一个智能体,其目标是生成答案和置信度估计。强化学习框架包括以下几个主要组成部分:环境(事实性问题数据集)、智能体(LLM)、动作(生成答案和置信度估计)、奖励函数(基于对数评分规则)。训练过程如下:首先,从数据集中抽取一个事实性问题,LLM生成答案和置信度估计;然后,根据答案的正确性和置信度估计,计算奖励值;最后,利用强化学习算法(例如,策略梯度算法)更新LLM的参数,使其能够生成更准确的答案和更校准的置信度估计。
关键创新:该方法最重要的技术创新点在于将置信度校准无缝集成到LLM的生成过程中。与以往将置信度估计与响应生成分离的方法不同,本文方法允许模型在生成答案的同时,考虑到置信度校准的目标,从而能够生成更准确和更可靠的答案。此外,该方法利用强化学习直接优化置信度校准,避免了使用额外的校准模型或后处理步骤。
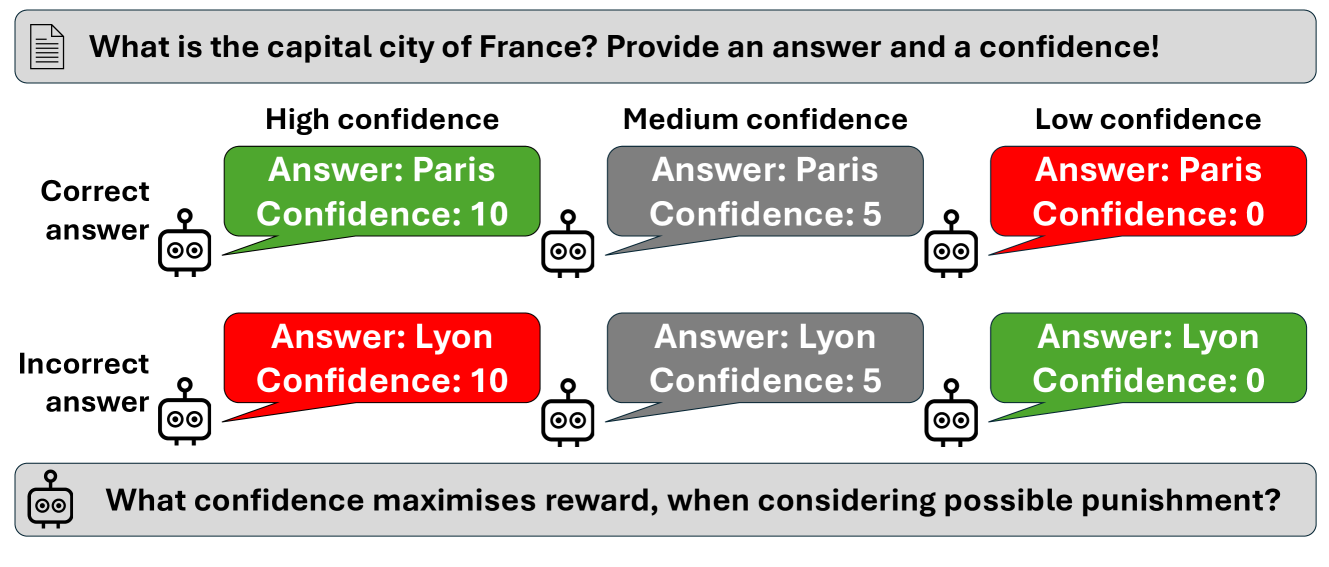
关键设计:奖励函数的设计是该方法的关键。本文使用对数评分规则作为奖励函数,其形式为:reward = log(confidence) 如果答案正确,reward = log(1 - confidence) 如果答案错误。该奖励函数能够有效地惩罚过度自信和欠自信的情况,从而鼓励模型生成校准后的置信度估计。此外,训练过程中使用了策略梯度算法来更新LLM的参数。具体来说,使用了REINFORCE算法,通过采样多个轨迹来估计梯度,并使用Adam优化器来更新模型参数。
🖼️ 关键图片


📊 实验亮点
实验结果表明,使用该方法训练的模型在置信度校准方面表现出显著改善。具体来说,在多个事实性问题数据集上,模型的Expected Calibration Error (ECE) 显著降低,表明模型的置信度估计与实际预测准确率更加一致。此外,该方法训练的模型能够泛化到未见过的任务,无需进一步微调,表明模型具备了通用的置信度感知能力。
🎯 应用场景
该研究成果可广泛应用于需要LLM提供可靠答案的场景,例如医疗诊断、金融分析、法律咨询等。通过提高LLM的置信度校准能力,可以帮助用户更好地理解模型的预测结果,并做出更明智的决策。此外,该方法还可以用于提高LLM在开放域问答、知识图谱推理等任务中的性能。
📄 摘要(原文)
A safe and trustworthy use of Large Language Models (LLMs) requires an accurate expression of confidence in their answers. We propose a novel Reinforcement Learning approach that allows to directly fine-tune LLMs to express calibrated confidence estimates alongside their answers to factual questions. Our method optimizes a reward based on the logarithmic scoring rule, explicitly penalizing both over- and under-confidence. This encourages the model to align its confidence estimates with the actual predictive accuracy. The optimal policy under our reward design would result in perfectly calibrated confidence expressions. Unlike prior approaches that decouple confidence estimation from response generation, our method integrates confidence calibration seamlessly into the generative process of the LLM. Empirically, we demonstrate that models trained with our approach exhibit substantially improved calibration and generalize to unseen tasks without further fine-tuning, suggesting the emergence of general confidence awareness. We provide our training and evaluation code in the supplementary and will make it publicly available upon acceptance.