An Efficient and Precise Training Data Construction Framework for Process-supervised Reward Model in Mathematical Reasoning
作者: Wei Sun, Qianlong Du, Fuwei Cui, Jiajun Zhang
分类: cs.CL, cs.AI
发布日期: 2025-03-04 (更新: 2025-07-23)
🔗 代码/项目: GITHUB
💡 一句话要点
EpicPRM:高效精确的数学推理过程监督奖励模型训练数据构建框架
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 数学推理 过程监督 奖励模型 数据构建 自适应二分搜索
📋 核心要点
- 现有数学推理过程监督数据构建方法成本高或质量差,限制了奖励模型训练效果。
- EpicPRM框架通过量化中间步骤贡献并结合自适应二分搜索,提升标注效率和精度。
- 实验表明,基于EpicPRM构建的Epic50k数据集训练的奖励模型,性能显著优于其他数据集。
📝 摘要(中文)
本文旨在提升大型语言模型(LLMs)的数学推理能力。研究者通常采用过程监督奖励模型(PRMs)来指导推理过程,从而有效提高模型的推理能力。然而,现有的过程监督训练数据构建方法,如人工标注和逐步骤蒙特卡洛估计,通常成本高昂或质量较差。为了解决这些挑战,本文提出了一种名为EpicPRM的框架,该框架基于量化的贡献来标注每个中间推理步骤,并使用自适应二分搜索算法来提高标注精度和效率。通过这种方法,我们高效地构建了一个高质量的过程监督训练数据集Epic50k,其中包含50k个带注释的中间步骤。与其他公开数据集相比,在Epic50k上训练的PRM表现出明显优越的性能。Epic50k数据集可在https://github.com/xiaolizh1/EpicPRM获取。
🔬 方法详解
问题定义:论文旨在解决大型语言模型数学推理中,过程监督奖励模型(PRM)训练数据构建效率低、质量差的问题。现有方法如人工标注成本高昂,而逐步骤蒙特卡洛估计则质量难以保证,导致训练出的PRM无法有效指导模型的推理过程。
核心思路:论文的核心思路是基于中间推理步骤对最终结果的贡献度进行量化,并以此为依据进行标注。通过量化贡献度,可以更准确地评估每个步骤的重要性,从而避免对不重要步骤的过度关注。同时,采用自适应二分搜索算法,可以在保证标注精度的前提下,显著提高标注效率。
技术框架:EpicPRM框架主要包含两个阶段:贡献度量化和自适应二分搜索标注。首先,通过某种方式(具体方式未知,论文中未详细说明)量化每个中间步骤对最终结果的贡献度。然后,利用自适应二分搜索算法,根据贡献度确定每个步骤的奖励值。该算法通过不断缩小搜索范围,快速找到合适的奖励值,从而提高标注效率。
关键创新:该论文的关键创新在于提出了一种基于贡献度量化的过程监督数据标注方法,并结合自适应二分搜索算法来提高标注效率和精度。与传统的标注方法相比,该方法能够更准确地评估每个步骤的重要性,并能够以更高效的方式进行标注。
关键设计:关于贡献度量化的具体方法,论文中没有详细说明,这部分是未知的。自适应二分搜索算法的具体实现细节也未完全公开,包括搜索范围的确定、停止条件等。奖励值的具体计算方式也未明确说明。这些细节可能影响最终的标注效果。
🖼️ 关键图片

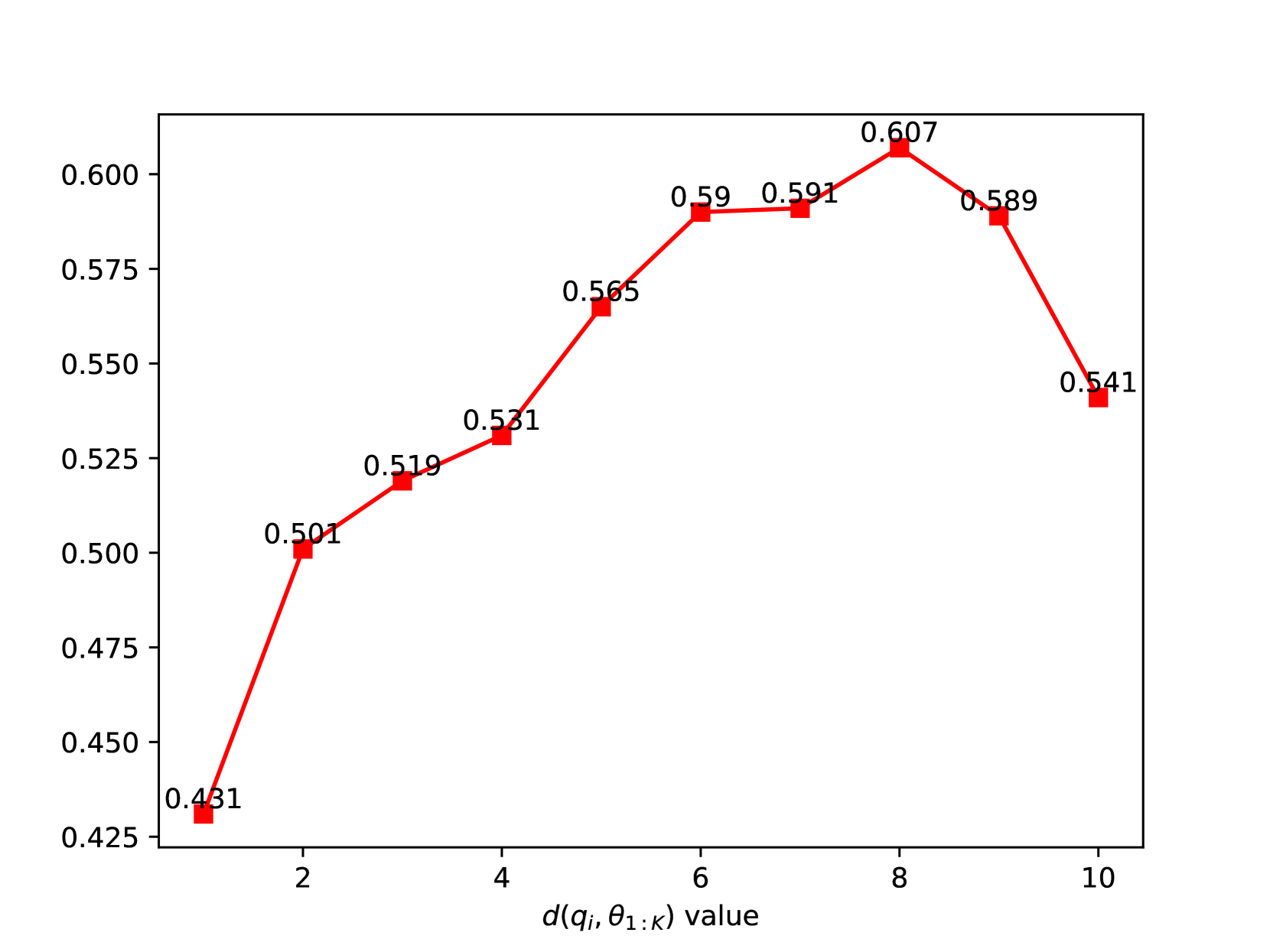
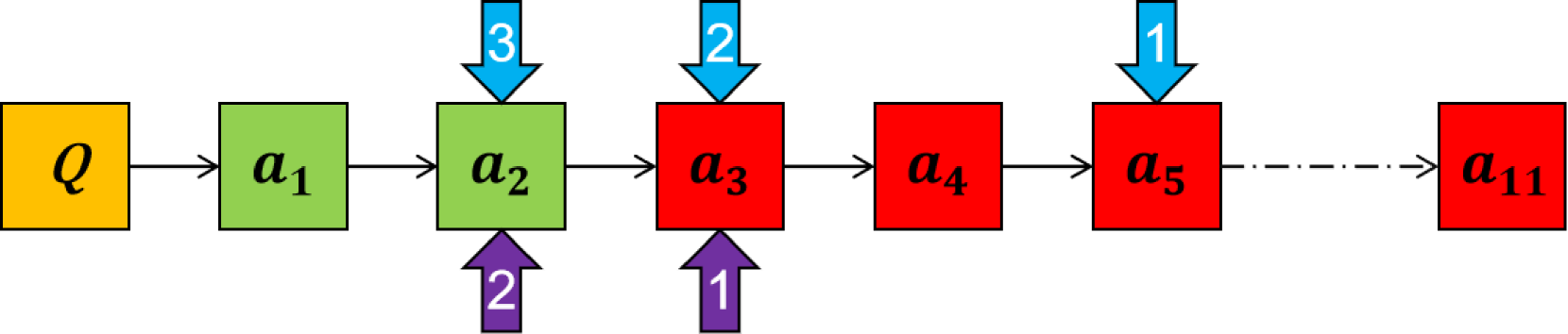
📊 实验亮点
实验结果表明,使用EpicPRM构建的Epic50k数据集训练的PRM,性能显著优于使用其他公开数据集训练的PRM。具体的性能指标和提升幅度在摘要中未给出,需要在论文中进一步查找。该结果验证了EpicPRM框架的有效性和Epic50k数据集的质量。
🎯 应用场景
该研究成果可应用于提升大型语言模型在数学、科学等领域的推理能力。高质量的过程监督数据能够有效训练奖励模型,从而指导模型生成更准确、更可靠的推理过程。此外,该框架也可推广到其他需要过程监督的任务中,例如代码生成、文本摘要等。
📄 摘要(原文)
Enhancing the mathematical reasoning capabilities of Large Language Models (LLMs) is of great scientific and practical significance. Researchers typically employ process-supervised reward models (PRMs) to guide the reasoning process, effectively improving the models' reasoning abilities. However, existing methods for constructing process supervision training data, such as manual annotation and per-step Monte Carlo estimation, are often costly or suffer from poor quality. To address these challenges, this paper introduces a framework called EpicPRM, which annotates each intermediate reasoning step based on its quantified contribution and uses an adaptive binary search algorithm to enhance both annotation precision and efficiency. Using this approach, we efficiently construct a high-quality process supervision training dataset named Epic50k, consisting of 50k annotated intermediate steps. Compared to other publicly available datasets, the PRM trained on Epic50k demonstrates significantly superior performance. Getting Epic50k at https://github.com/xiaolizh1/EpicPRM.