Add-One-In: Incremental Sample Selection for Large Language Models via a Choice-Based Greedy Paradigm
作者: Zhuo Li, Yuhao Du, Xiaoqi Jiao, Yiwen Guo, Yuege Feng, Xiang Wan, Anningzhe Gao, Jinpeng Hu
分类: cs.CL
发布日期: 2025-03-04 (更新: 2025-10-13)
备注: EMNLP2025
🔗 代码/项目: GITHUB
💡 一句话要点
提出Add-One-In增量采样法,利用LLM进行高质量、多样性大模型训练数据选择。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 样本选择 增量学习 贪婪算法 数据质量 模型训练 LLM应用
📋 核心要点
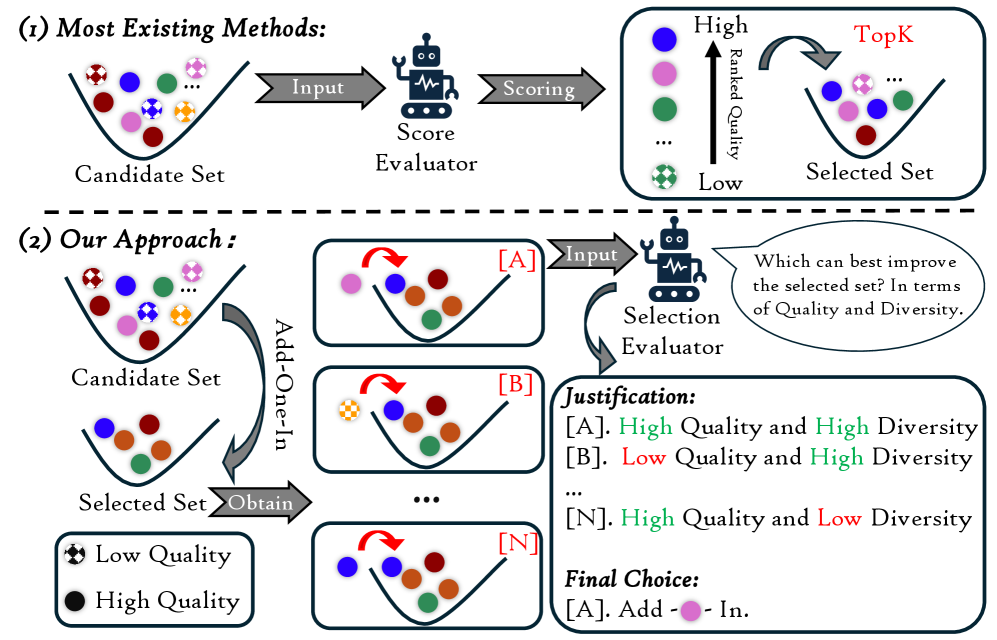
- 现有样本选择方法侧重个体质量评估,忽略了数据子集的整体价值,难以平衡多样性与效率。
- 提出Add-One-In框架,利用LLM评估样本加入子集后的贡献,采用贪婪增量采样提升效率。
- 实验表明,该方法选择的数据超越完整数据集,且在医疗数据集上验证了实用性。
📝 摘要(中文)
从海量数据集中选择高质量且多样化的训练样本,对于降低训练开销和提升大型语言模型(LLMs)的性能至关重要。然而,现有研究未能充分评估所选数据的整体价值,主要侧重于个体质量,并且难以在确保多样性和最小化数据点遍历之间取得有效平衡。因此,本文提出了一种新颖的基于选择的样本选择框架,该框架将重点从评估个体样本质量转移到比较不同样本加入子集时的贡献价值。借助LLMs先进的语言理解能力,我们利用LLMs来评估选择过程中每个选项的价值。此外,我们设计了一个贪婪采样过程,其中样本被增量式地添加到子集中,从而通过消除在有限预算下详尽遍历整个数据集的需求来提高效率。大量实验表明,我们方法选择的数据不仅超越了完整数据集的性能,而且在需要更少选择的情况下,实现了与最近的强大研究具有竞争力的结果。此外,我们在更大的医疗数据集上验证了我们的方法,突出了其在实际应用中的实用性。我们的代码和数据可在https://github.com/BIRlz/comperative_sample_selection上找到。
🔬 方法详解
问题定义:现有的大语言模型训练数据选择方法主要关注单个样本的质量,而忽略了样本之间的相互作用以及它们对整个训练数据集的贡献。此外,在海量数据集中进行样本选择时,如何在保证数据多样性的同时,降低计算复杂度,避免遍历整个数据集是一个挑战。现有方法难以在效率和效果之间取得平衡。
核心思路:本文的核心思路是将样本选择问题转化为一个基于选择的优化问题。不再单独评估每个样本的质量,而是评估将每个候选样本添加到已选择的样本子集中后,对模型性能的贡献。利用大型语言模型(LLM)的强大语言理解能力来评估这种贡献,从而更准确地衡量样本的价值。
技术框架:该方法采用增量式的贪婪采样过程。首先,初始化一个空的样本子集。然后,在每一轮迭代中,从剩余的样本中选择一个添加到当前子集中,使得添加该样本后,子集的整体价值最大。这个价值由LLM评估,具体来说,LLM被用来比较添加不同样本后,子集在特定任务上的表现。重复这个过程,直到达到预定的样本数量或预算。
关键创新:该方法最重要的创新点在于将样本选择问题转化为一个比较不同样本贡献的问题,并利用LLM来评估这种贡献。这与传统的基于样本质量的评估方法有本质区别,因为它考虑了样本之间的相互作用,以及它们对整个训练数据集的整体影响。此外,增量式的贪婪采样过程避免了对整个数据集的遍历,提高了效率。
关键设计:在利用LLM评估样本贡献时,需要设计合适的prompt,以引导LLM进行有效的比较。例如,可以设计prompt让LLM比较添加不同样本后,模型在特定任务上的表现,并给出相应的评分。此外,还需要考虑如何有效地利用LLM的输出,例如,可以使用LLM的评分作为选择样本的依据,或者使用LLM生成的文本来增强样本的多样性。
🖼️ 关键图片


📊 实验亮点
实验结果表明,使用Add-One-In方法选择的数据不仅超越了完整数据集的性能,而且在需要更少选择的情况下,实现了与最近的强大研究具有竞争力的结果。例如,在某个具体任务上,使用该方法选择的10%的数据,可以达到甚至超过使用全部数据训练的模型性能。此外,该方法在医疗数据集上的验证也表明了其在实际应用中的有效性。
🎯 应用场景
该研究成果可广泛应用于大型语言模型的预训练和微调阶段,尤其是在数据资源有限或数据质量参差不齐的情况下。通过选择高质量、多样性的训练数据,可以显著降低训练成本,提升模型性能,加速LLM在各个领域的应用,例如医疗、金融、教育等。
📄 摘要(原文)
Selecting high-quality and diverse training samples from extensive datasets plays a crucial role in reducing training overhead and enhancing the performance of Large Language Models (LLMs). However, existing studies fall short in assessing the overall value of selected data, focusing primarily on individual quality, and struggle to strike an effective balance between ensuring diversity and minimizing data point traversals. Therefore, this paper introduces a novel choice-based sample selection framework that shifts the focus from evaluating individual sample quality to comparing the contribution value of different samples when incorporated into the subset. Thanks to the advanced language understanding capabilities of LLMs, we utilize LLMs to evaluate the value of each option during the selection process. Furthermore, we design a greedy sampling process where samples are incrementally added to the subset, thereby improving efficiency by eliminating the need for exhaustive traversal of the entire dataset with the limited budget. Extensive experiments demonstrate that selected data from our method not only surpasses the performance of the full dataset but also achieves competitive results with recent powerful studies, while requiring fewer selections. Moreover, we validate our approach on a larger medical dataset, highlighting its practical applicability in real-world applications. Our code and data are available at https://github.com/BIRlz/comperative_sample_selection.