Superscopes: Amplifying Internal Feature Representations for Language Model Interpretation
作者: Jonathan Jacobi, Gal Niv
分类: cs.CL, cs.AI, cs.LG
发布日期: 2025-03-03 (更新: 2025-03-09)
💡 一句话要点
Superscopes:通过放大内部特征表示增强语言模型的可解释性
🎯 匹配领域: 支柱四:生成式动作 (Generative Motion) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 语言模型可解释性 内部表示 特征放大 机制可解释性 无分类器引导 MLP Patchscopes
📋 核心要点
- 大型语言模型内部表示的可解释性面临挑战,现有方法难以有效揭示模型如何构建上下文和表示概念。
- Superscopes通过系统地放大MLP输出和隐藏状态中的叠加特征,从而增强模型内部表示的可解释性。
- Superscopes无需额外训练,即可解释先前方法无法解释的内部表示,为理解LLM的内部机制提供了新视角。
📝 摘要(中文)
理解和解释大型语言模型(LLM)的内部表示仍然是一个开放的挑战。Patchscopes引入了一种通过将内部激活拼接到新的提示中来探测内部激活的方法,从而促使模型自我解释其隐藏表示。我们引入了Superscopes,这是一种在将MLP(多层感知器)输出和隐藏状态拼接到新上下文之前,系统地放大其中叠加的特征的技术。受到“特征即方向”的观点和扩散模型中的无分类器引导(CFG)方法的启发,Superscopes放大了微弱但有意义的特征,从而能够解释先前方法未能解释的内部表示——所有这些都无需额外的训练。这种方法为LLM如何构建上下文和表示复杂概念提供了新的见解,进一步推进了机制可解释性。
🔬 方法详解
问题定义:现有方法,如Patchscopes,虽然能够通过拼接激活来探测模型内部表示,但对于微弱但有意义的特征的解释能力有限。这些特征可能被叠加在其他更强的特征中,难以被有效识别和利用。因此,如何有效地放大这些微弱特征,从而更全面地理解LLM的内部机制,是一个亟待解决的问题。
核心思路:Superscopes的核心思路是借鉴“特征即方向”的观点和扩散模型中的无分类器引导(CFG)方法,通过系统性地放大MLP输出和隐藏状态中的叠加特征,从而增强这些微弱特征的影响力。这种方法类似于在图像生成中通过CFG来增强特定图像特征,从而使得模型更加关注这些特征,并更容易被解释。
技术框架:Superscopes的技术框架主要包含以下几个阶段:1) 选择需要探测的内部激活层(通常是MLP的输出或隐藏状态)。2) 识别该层中需要放大的特征方向。3) 使用类似于CFG的方法,通过调整激活向量,放大选定的特征方向。4) 将修改后的激活向量拼接到新的提示中,观察模型行为的变化。5) 分析模型行为的变化,从而推断被放大的特征所代表的含义。
关键创新:Superscopes的关键创新在于其系统性地放大叠加特征的能力。与传统的Patchscopes方法相比,Superscopes能够更有效地识别和利用微弱但有意义的特征,从而更全面地理解LLM的内部机制。此外,Superscopes无需额外的训练,即可实现对模型内部表示的增强和解释,降低了使用成本。
关键设计:Superscopes的关键设计在于如何有效地放大选定的特征方向。具体来说,该方法使用以下公式来调整激活向量:activation_new = activation_original + guidance_scale * (activation_original - activation_null),其中activation_original是原始激活向量,activation_null是对应于空提示的激活向量,guidance_scale是一个控制放大程度的参数。通过调整guidance_scale,可以控制被放大的特征的强度。此外,如何选择合适的activation_null也是一个重要的设计考虑因素。
🖼️ 关键图片

📊 实验亮点
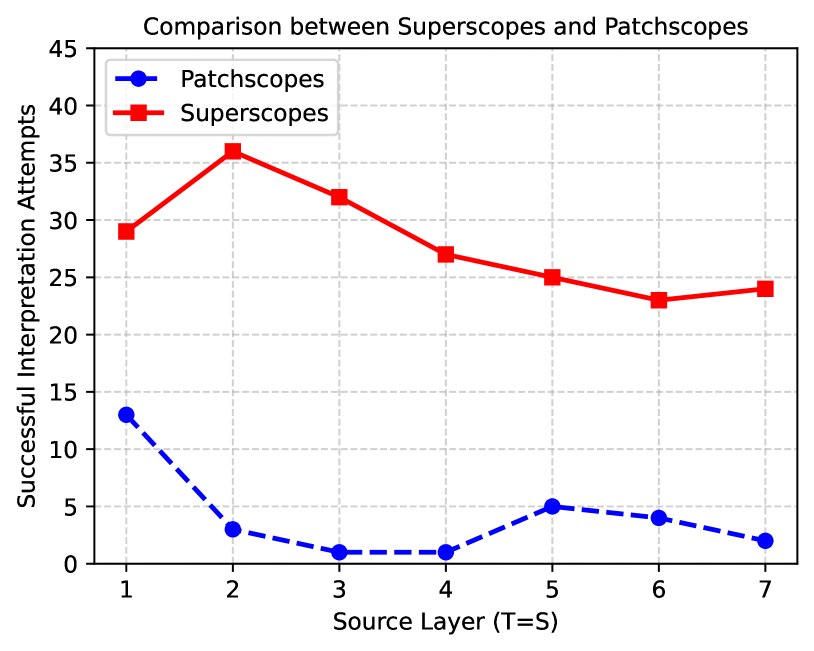
Superscopes在实验中成功解释了先前方法未能解释的内部表示,揭示了LLM如何构建上下文和表示复杂概念的新见解。例如,该方法能够识别模型中负责处理特定类型信息的神经元,并理解这些神经元之间的相互作用。具体性能提升数据未知。
🎯 应用场景
Superscopes可应用于提升大型语言模型的可解释性和安全性。通过理解模型内部如何表示知识和进行推理,可以更好地诊断和修复模型的潜在问题,例如偏见和生成有害内容。此外,该技术还可以用于改进模型的控制能力,使其能够更好地遵循用户的指令。
📄 摘要(原文)
Understanding and interpreting the internal representations of large language models (LLMs) remains an open challenge. Patchscopes introduced a method for probing internal activations by patching them into new prompts, prompting models to self-explain their hidden representations. We introduce Superscopes, a technique that systematically amplifies superposed features in MLP outputs (multilayer perceptron) and hidden states before patching them into new contexts. Inspired by the "features as directions" perspective and the Classifier-Free Guidance (CFG) approach from diffusion models, Superscopes amplifies weak but meaningful features, enabling the interpretation of internal representations that previous methods failed to explain-all without requiring additional training. This approach provides new insights into how LLMs build context and represent complex concepts, further advancing mechanistic interpretability.