Phi-4-Mini Technical Report: Compact yet Powerful Multimodal Language Models via Mixture-of-LoRAs
作者: Microsoft, :, Abdelrahman Abouelenin, Atabak Ashfaq, Adam Atkinson, Hany Awadalla, Nguyen Bach, Jianmin Bao, Alon Benhaim, Martin Cai, Vishrav Chaudhary, Congcong Chen, Dong Chen, Dongdong Chen, Junkun Chen, Weizhu Chen, Yen-Chun Chen, Yi-ling Chen, Qi Dai, Xiyang Dai, Ruchao Fan, Mei Gao, Min Gao, Amit Garg, Abhishek Goswami, Junheng Hao, Amr Hendy, Yuxuan Hu, Xin Jin, Mahmoud Khademi, Dongwoo Kim, Young Jin Kim, Gina Lee, Jinyu Li, Yunsheng Li, Chen Liang, Xihui Lin, Zeqi Lin, Mengchen Liu, Yang Liu, Gilsinia Lopez, Chong Luo, Piyush Madan, Vadim Mazalov, Arindam Mitra, Ali Mousavi, Anh Nguyen, Jing Pan, Daniel Perez-Becker, Jacob Platin, Thomas Portet, Kai Qiu, Bo Ren, Liliang Ren, Sambuddha Roy, Ning Shang, Yelong Shen, Saksham Singhal, Subhojit Som, Xia Song, Tetyana Sych, Praneetha Vaddamanu, Shuohang Wang, Yiming Wang, Zhenghao Wang, Haibin Wu, Haoran Xu, Weijian Xu, Yifan Yang, Ziyi Yang, Donghan Yu, Ishmam Zabir, Jianwen Zhang, Li Lyna Zhang, Yunan Zhang, Xiren Zhou
分类: cs.CL, cs.AI, cs.LG
发布日期: 2025-03-03 (更新: 2025-03-07)
备注: 39 pages
💡 一句话要点
微软发布Phi-4-Mini系列模型,通过混合LoRA实现紧凑而强大的多模态语言能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 LoRA适配器 语言模型 语音识别 视觉语言模型 合成数据 小模型 推理能力
📋 核心要点
- 现有语言模型在规模和性能之间存在权衡,小型模型能力有限,大型模型计算成本高昂。
- Phi-4系列模型通过高质量数据和LoRA适配器,在保持模型紧凑的同时,显著提升了语言和多模态能力。
- 实验表明,Phi-4-Mini在数学、编码和多模态任务上,超越了同等规模甚至更大规模的开源模型。
📝 摘要(中文)
本文介绍了Phi-4-Mini和Phi-4-Multimodal,它们是紧凑但功能强大的语言和多模态模型。Phi-4-Mini是一个38亿参数的语言模型,基于高质量的Web数据和合成数据进行训练,显著优于近期同等规模的开源模型,并在需要复杂推理的数学和编码任务上与两倍规模的模型性能相当。这一成就归功于精心设计的合成数据方案,强调高质量的数学和编码数据集。与之前的Phi-3.5-Mini相比,Phi-4-Mini具有更大的20万token的词汇量,以更好地支持多语言应用,并采用分组查询注意力机制以实现更高效的长序列生成。Phi-4-Multimodal是一个将文本、视觉和语音/音频输入模态集成到单个模型中的多模态模型。其新颖的模态扩展方法利用LoRA适配器和模态特定路由器,允许多种推理模式组合各种模态而互不干扰。例如,尽管语音/音频模态的LoRA组件只有4.6亿参数,但它目前在OpenASR排行榜上名列前茅。Phi-4-Multimodal支持涉及(视觉+语言)、(视觉+语音)和(语音/音频)输入的场景,在各种任务上优于更大的视觉-语言和语音-语言模型。此外,我们还尝试进一步训练Phi-4-Mini以增强其推理能力。尽管其紧凑的38亿参数规模,但这个实验版本在推理性能上与甚至超过了更大的模型,包括DeepSeek-R1-Distill-Qwen-7B和DeepSeek-R1-Distill-Llama-8B。
🔬 方法详解
问题定义:现有语言模型通常需要在模型规模和性能之间做出权衡。大型模型虽然性能强大,但计算资源消耗巨大,难以部署在资源受限的环境中。小型模型虽然计算效率高,但往往在复杂推理任务上表现不佳。此外,如何有效地融合多种模态信息(如文本、图像、语音)仍然是一个挑战。
核心思路:Phi-4系列模型的核心思路是在保持模型规模较小的同时,通过高质量的数据和高效的训练方法来提升模型性能。对于语言模型,重点在于精心设计的合成数据,特别是高质量的数学和编码数据集。对于多模态模型,则采用LoRA适配器和模态特定路由器,实现不同模态信息的有效融合,避免模态间的相互干扰。
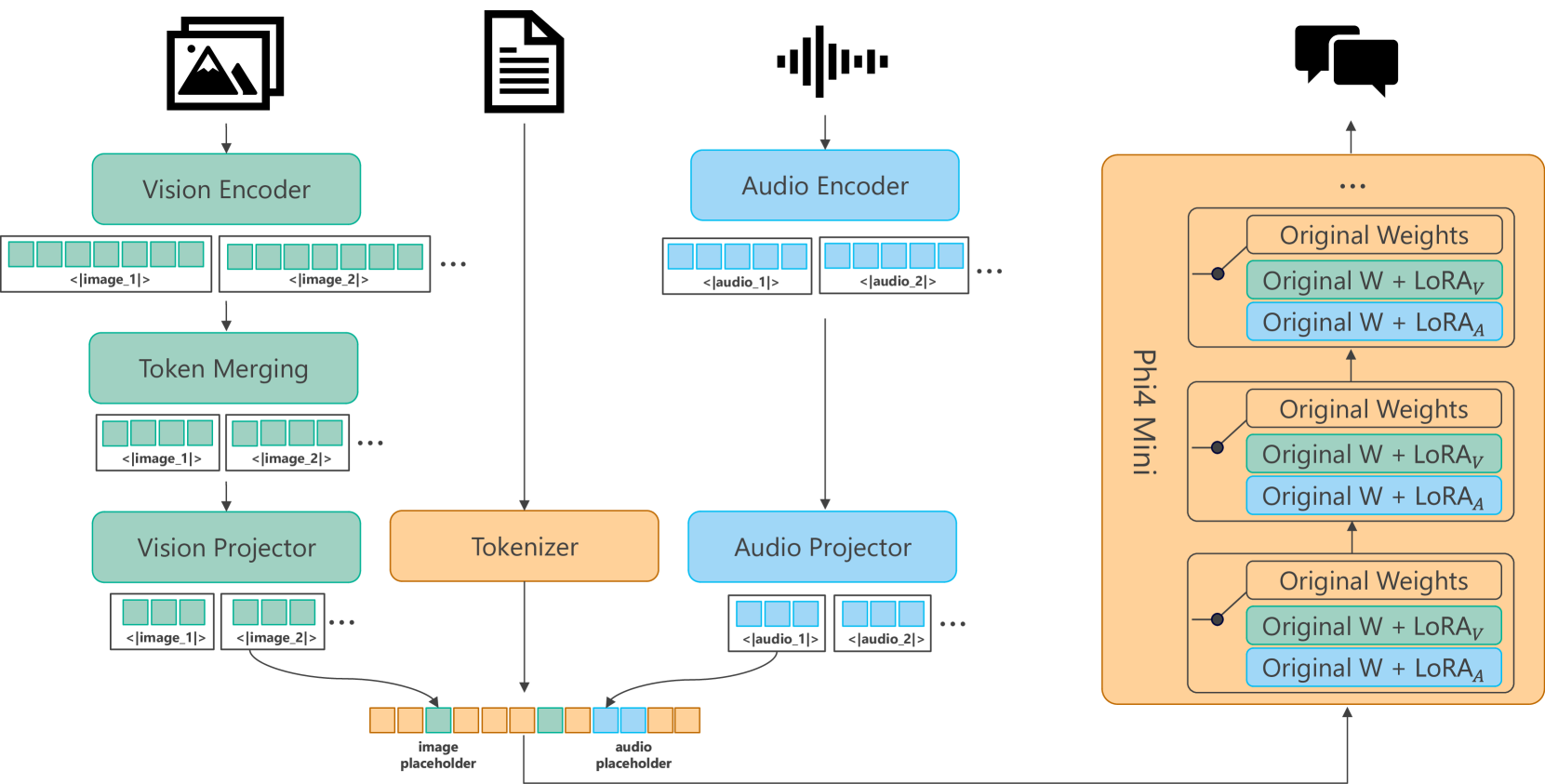
技术框架:Phi-4-Mini是基于Transformer架构的语言模型,拥有38亿参数。Phi-4-Multimodal则是在Phi-4-Mini的基础上,通过LoRA适配器扩展了视觉和语音/音频模态。整体框架包含以下主要模块:1) 文本编码器(Phi-4-Mini);2) 视觉编码器(用于处理图像输入);3) 语音/音频编码器(用于处理语音/音频输入);4) LoRA适配器(用于将视觉和语音/音频模态的信息融入到文本编码器中);5) 模态特定路由器(用于控制不同模态信息的流动)。
关键创新:Phi-4系列模型的关键创新在于:1) 高质量的合成数据方案,显著提升了小型语言模型在复杂推理任务上的性能;2) 基于LoRA适配器和模态特定路由器的多模态融合方法,实现了不同模态信息的有效集成,避免了模态间的相互干扰。这种方法允许模型在不同的推理模式下工作,例如仅使用文本、文本+图像、文本+语音等。
关键设计:Phi-4-Mini采用了20万token的词汇量,以更好地支持多语言应用。同时,采用了分组查询注意力(Group Query Attention)机制,以提高长序列生成的效率。对于多模态模型,LoRA适配器的参数量为4.6亿,针对不同的模态设计了不同的损失函数,以优化模型的训练。
🖼️ 关键图片
📊 实验亮点
Phi-4-Mini在数学和编码任务上达到了与两倍规模模型相当的性能。Phi-4-Multimodal在OpenASR排行榜上名列前茅,超越了更大的视觉-语言和语音-语言模型。实验版本Phi-4-Mini在推理能力上与DeepSeek-R1-Distill-Qwen-7B和DeepSeek-R1-Distill-Llama-8B等更大模型相当甚至超越。
🎯 应用场景
Phi-4系列模型具有广泛的应用前景,包括智能助手、代码生成、数学问题求解、多模态内容理解和生成等。其紧凑的模型规模使其能够部署在移动设备和边缘计算环境中,为资源受限的场景提供强大的AI能力。未来,该模型有望在教育、医疗、金融等领域发挥重要作用。
📄 摘要(原文)
We introduce Phi-4-Mini and Phi-4-Multimodal, compact yet highly capable language and multimodal models. Phi-4-Mini is a 3.8-billion-parameter language model trained on high-quality web and synthetic data, significantly outperforming recent open-source models of similar size and matching the performance of models twice its size on math and coding tasks requiring complex reasoning. This achievement is driven by a carefully curated synthetic data recipe emphasizing high-quality math and coding datasets. Compared to its predecessor, Phi-3.5-Mini, Phi-4-Mini features an expanded vocabulary size of 200K tokens to better support multilingual applications, as well as group query attention for more efficient long-sequence generation. Phi-4-Multimodal is a multimodal model that integrates text, vision, and speech/audio input modalities into a single model. Its novel modality extension approach leverages LoRA adapters and modality-specific routers to allow multiple inference modes combining various modalities without interference. For example, it now ranks first in the OpenASR leaderboard to date, although the LoRA component of the speech/audio modality has just 460 million parameters. Phi-4-Multimodal supports scenarios involving (vision + language), (vision + speech), and (speech/audio) inputs, outperforming larger vision-language and speech-language models on a wide range of tasks. Additionally, we experiment to further train Phi-4-Mini to enhance its reasoning capabilities. Despite its compact 3.8-billion-parameter size, this experimental version achieves reasoning performance on par with or surpassing significantly larger models, including DeepSeek-R1-Distill-Qwen-7B and DeepSeek-R1-Distill-Llama-8B.